万字长文深度解析:TPU的发展科技慢变量
2025年凛冬,关于TPU的几条新闻被炒得火热:
AI独角兽Anthropic宣布扩大与谷歌云的合作,将在未来数年内部署100万颗TPU用于训练其下一代Claude模型 。
Google正在与Meta等巨头谈判,探讨将TPU部.署在客户的数据中心,或者提供某种形式的“私有云”租赁 。
谷歌分布式云边缘(Google Distributed Cloud Edge)产品已经开始集成Edge TPU,支持零售、制造等场景的本地化AI推理。这表明谷歌正在尝试将TPU的触角延伸至云边界之外,直接分食NVIDIA在边缘计算市场的份额。
可看到的趋势是,TPU不再只是Google内部的“算盘”,它正在被推向客户的数据中心、云边界与生态中心,成为一桩可交易的基础设施生意。
在英伟达CUDA生态看似牢不可破的今天,Google为何早在十年前就孤注一掷地选择了自研芯片这条寂寞之路?从那个功能纯粹、仅凭脉动阵列单点突围的TPU v1,到如今让Meta都垂涎的v7 Ironwood,Google究竟做对了什么?在它的发展历史上,有哪些关键事件和技术创新,又是在什么背景下发生的?
本文旨在回顾这十年间TPU发展的缘起和变革,用图文并茂、深入浅出的语言来硬核解析每一代TPU迭代的关键技术。
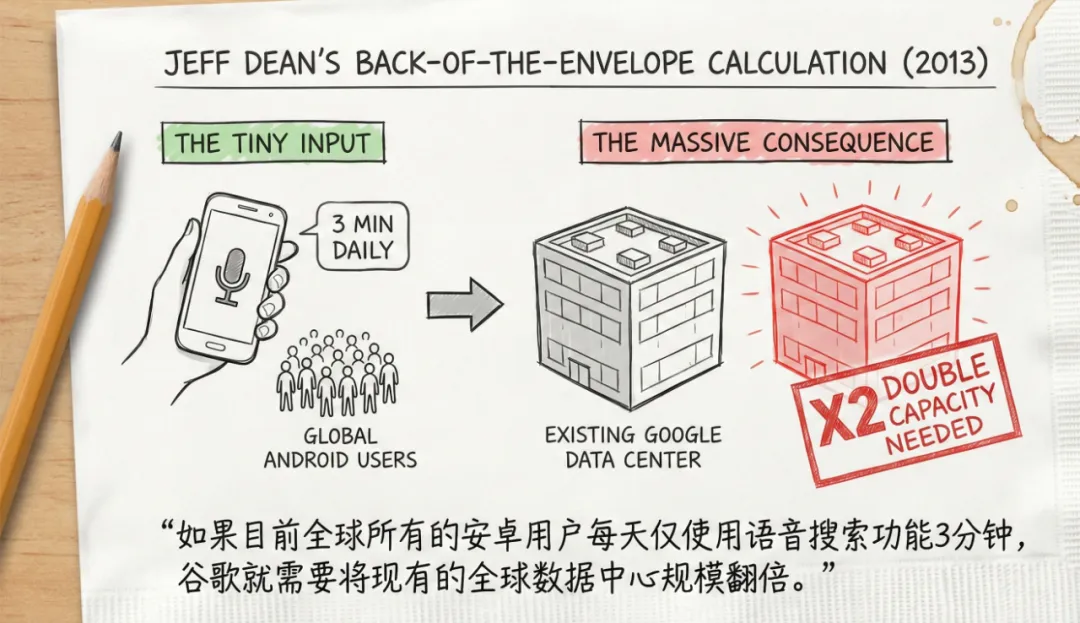
尽管对于自研芯片的讨论早在2006年就在Google内部有所讨论,但当时的神经网络只是边缘业务,讨论没有激起什么大的水花。真正让Google下决心开启自研芯片的,是2013年语音识别团队准备推出的基于深度神经网络的新一代语音模型。在项目评估时,Jeff Dean进行了一项著名的“封底计算”(Back-of-the-napkin calculation):
这一计算将事实摊在了台面上:在语音推理这种“极低延迟 + 海量请求”的规模下,通用CPU的能效与成本曲线开始失控。Haswell架构的CPU虽然通用,但在执行神经网络推理(本质上是大量的矩阵乘法)时,大量的晶体管和能耗被浪费在了解码、缓存管理和乱序执行逻辑上,而非算术运算本身。要想在不额外支出数十亿美元CapEx的前提下支持语音业务的发展,必须加强对AI硬件的研发。
当时Google内部形成了三个独立小组,分别代表三种不同的硬件加速路径进行竞争性提案。
方案一是扩大NVIDIA GPU的采购形成GPU集群。这个方案技术成熟,软件栈(CUDA)完善,无需自研风险。但在测试时发现,GPU追求极致的吞吐量和大批次,而在语音搜索的场景中,批处理的大小必须非常小以实现低延迟。小批次计算时,GPU的吞吐优势难以兑现,能效也不占优。
方案二是使用现场可编程门阵列(FPGA)。这一路线在当时被微软大力推崇,其“Project Catapult”项目成功将FPGA部署在Bing搜索服务器中 。它比GPU的延迟低很多,但其能效比仍远低于专用芯片。同时Jeff Dean认为,10倍于CPU的性能提升,并不足以一劳永逸地解决“数据中心翻倍”的危机。
方案三则是从零开始设计专用集成电路(ASIC),这也是TPU的诞生地。团队成员想,既然神经网络推理99%的计算量都是矩阵乘法和激活函数,为什么不设计一个只做这两件事的芯片?通过剥离CPU/GPU中所有通用的控制逻辑(乱序执行、分支预测、大缓存),ASIC可以将硅片面积几乎全部用于算术逻辑单元。反对的声音认为,芯片设计周期太长,如果芯片造出来时,AI算法已经变了,那么这批芯片就是电子垃圾。关键时刻,Jeff Dean判断:尽管AI模型结构(CNN, LSTM, RNN)在变,但底层的数学原语(线性代数运算)在未来很长一段时间内不会改变。这一判断为ASIC方案扫清了决策障碍。
三种技术路径竞争最终的结果如今已显而易见。对长期主义的坚持,和对AI趋势的正确判断,促成了TPU的诞生。与通用CPU相比,第一代TPU的设计哲学是激进的“减法”:
1、它抛弃了CPU中用于乱序执行、分支预测、多线程调度的复杂逻辑,将芯片上绝大多数的晶体管都用于乘累加单元,实现了极致的计算密度以及执行的确定性。
2、为了在有限的芯片面积和功耗预算下极致提升吞吐量,TPU v1还做出了一个关键的妥协:仅支持8位整数乘法,而非GPU通用的32位浮点。这是因为,v1的设立主要是为了解决推理(而非训练)的难题,而推理阶段在许多成熟任务上,经校准或量化训练后,INT8带来的精度损失可控制在很小范围。在时间短(15个月内需要完成从设计到部署)、任务重的工期下,这种现实主义可以被看做是“长期主义”与“小步快走”的混合产物。
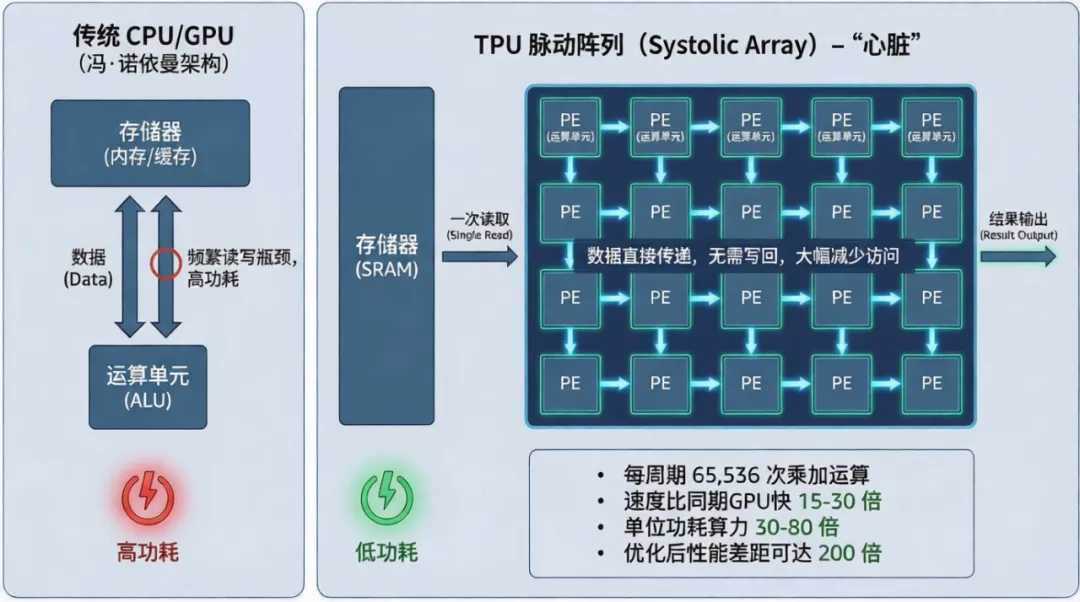
3、虽然在设计上有所妥协,但它的核心创新——脉动阵列——则一以贯之地从v1延续到了最新一代v7,可被称为是TPU的“心脏”。在传统的CPU/GPU(冯·诺依曼架构)中,每次运算都需要从寄存器或缓存中读取数据,计算完再写回,这导致了巨大的读写功耗瓶颈。在TPU的脉动阵列中,数据一旦从内存读取进入阵列,就会在运算单元之间直接传递并多次复用,大大减少了写回存储器的次数,使得TPU的MXU(矩阵乘法单元)达到了极高的计算密度,因为它把能量主要聚焦在了“算”上,而不是花在“存取”上。
TPU项目的成功支撑了Google语音搜索、Google翻译以及后来的AlphaGo的算力需求,而无需翻倍建设数据中心。更重要的是,它确立了Google在 AI 硬件领域的“系统级思维”:不要试图用软件去修补硬件的缺陷,要从系统层面重构软硬件的边界。
随着机器翻译和图像识别模型的复杂度指数级上升,仅用于推理的芯片已无法满足Google Brain的研究需求。研究人员发现,GPU训练与TPU推理之间的转换损耗严重阻碍了迭代速度。Google意识到,必须掌控训练环节。
但TPU v1是专为2013年的“语音搜索算力危机”而特别设计的,它有一些瓶颈导致了它适合推理而不是训练。
怎样的芯片适合推理,怎样的芯片适合训练呢?推理对精确计算的鲁棒性更高,在很多任务里,适度降低精度不会改变最终类别决策,却能显著换来吞吐与能效。比如识别一张图片里的猫,只要特征足够显著,即使中间的计算数值从0.75321变成了0.75(精度损失),最终结果依然是“猫”,不会变成“狗”,在精度上可做一定取舍。而且推理时模型的权重已经确定,不需要更新权重。而训练则需要需要计算梯度来反向更新权重。这些梯度往往是极小的数值(例如 0.00001)。如果用整数表示,这些微小的变化会直接被“四舍五入”成 0,导致模型学不到任何东西(梯度消失)。权重更新需要不断写入,也需要成千上万个芯片高效协同,同步梯度。
从这里就可以看出,TPU v1在训练端的弱点:不支持浮点运算,权重写入低效,芯片之间没有高速网络协同机制。TPU v2则针对这些弱点做了改进:
1、新数据格式,浮点数BF16的创建。
浮点数类似于科学计数法(例如 1.23 x 10^5 ),由三个部分组成:符号位(正负)、指数位(表示数值的大小范围,10^5里指的是5)和尾数位(表示具体的精度数值,即1.23)。标准的32位数据格式FP32精度大,但占用的内存和带宽也很大。半精度浮点数FP16占内存小,但指数位只有5位,这对于深度学习训练中经常出现的梯度累加来说,范围太窄了。Google团队创造了一个折中的格式:BF16。三者的结构对比如下:
FP32: [符号: 1][指数: 8][尾数: 23] (总共32位)
FP16: [符号: 1][指数: 5][尾数: 10] (总共16位,范围太小)
BF16: [符号: 1][指数: 8][尾数: 7] (总共16位,范围与FP32完全相同)
观察可以发现,BF16和FP32的指数位相同,即它能表示的范围与FP32完全相同,只是把尾数暴力截断,牺牲了精度。而深度学习对动态范围极度敏感(需要防止梯度爆炸或消失),但对精度非常宽容,而且对于神经网络来说,这只是相当于给图像加了一点点噪点,反而有助于模型的泛化,防止过拟合。这一特点,使BF16非常适合进行训练,既拥有和FP32一样的动态范围,却只有一半的内存占用。这一格式成为了TPU v2的核心特性,后来被业界广泛支持,成为训练常用低精度格式之一。
2、创建Pod集群架构,引入ICI (Inter-Chip Interconnect)。
在引入ICI之前,芯片之前如果要交流数据,必须先把数据发回CPU内存,CPU 再通过慢速的以太网发给另一台机器的CPU,再传给那边的TPU,这个过程是训练的极大瓶颈。
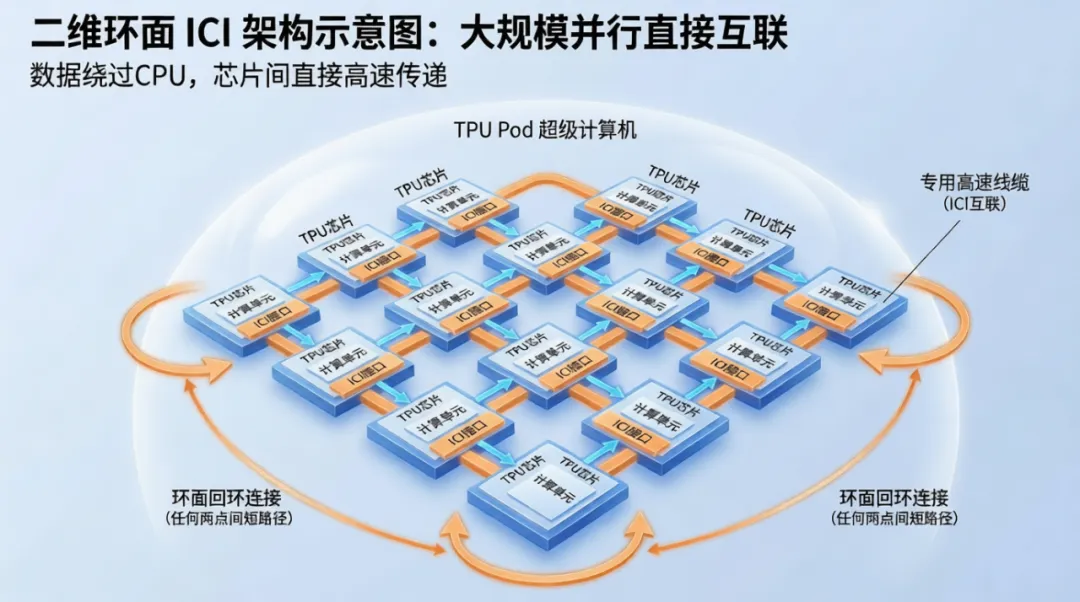
ICI不再将TPU视为独立的加速卡,而是将其设计为大规模并行计算机的节点。通信接口直接集成在了TPU芯片上,芯片A的计算单元可以直接将数据写入ICI接口,通过专用线缆直达芯片B的ICI接口,绕过了主机CPU和操作系统的干预。256个TPU芯片可以直接互联构建成一个二维环面的TPU Pod,形成一个算力高达11.5PFLOPS的超级计算机。这使得TPU不再是独立的加速卡,而是可以组成成百上千个芯片的超级计算机(Pod)。
听起来不明觉厉是不是?形象点来说,它的算力很高,如果让全地球70亿人每人拿一个计算器,每秒钟算一次乘法,我们需要19天不眠不休才能完成这个TPU Pod一秒钟的工作量。而二维环面则说明,任何两个芯片之间的距离都非常近。你可以理解成,最后一排的芯片想跟第一排芯片传递信息,就像第一排芯片向第二排芯片传递信息一样快。数据不需要绕远路,就像在一个圆圈表面上跑,永远是近路。
暂时解决了硬件问题,算法的瓶颈随即显现。
在 2017 年之前,自然语言处理(NLP)的主流架构是RNN(循环神经网络)和LSTM(长短期记忆网络)。这些模型在处理语言时,必须严格按照时间顺序进行:读取第一个字,生成隐状态,传递给第二个字,再读取第二个字……
这种时序依赖性是并行计算的死敌。哪怕你拥有10000块TPU,如果算法要求必须“做完第一步才能做第二步”,那么剩下的9999块TPU就只能在旁边闲置。这在系统工程中被称为“阿姆达尔定律”(Amdahl's Law)的诅咒。