Karpathy又封神:掀翻RAG成品
知识第一次,能像代码一样利滚利。前OpenA 创始团队成员、特斯拉前 AI 高级总监 Andrej Karpathy,提出一个狠招:别再用 RAG 检索你的知识库,让大模型把它「编译」成一座持续生长的活 Wiki。两个多月,他在GitHub屠出 5000+ star。
收藏不等于拥有,高亮不等于理解。
那些凌晨两点让你心潮澎湃的深度好文,那些在Obsidian里拉出的密密麻麻的双向链接,那些在Notion里精心排版的数据库,都是躺在笔记软件里的「赛博木乃伊」。
图谱看似壮观,实则早已腐朽。
这是整个信息过载时代的系统性失败。
现Anthropic工程师、前OpenAI联合创始人、Tesla前AI总监Karpathy,看不下去了,扔下一枚炸弹。
传送门:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
他没有宣布新模型,没有发布新框架,他只是说:把你的笔记当成不可变源代码,让LLM做编译器。
两个月过去,这份文档已经在Obsidian、Claude、Cursor社区掀起一场静默却剧烈的迁移。
有人已经把自己的Wiki扩展到上百页、数十万字。
自动化插件开始出现。学术研究者、独立创业者、终身学习者正在集体转向一种全新的知识生产关系。
RAG的黄昏
信息搬运救不了你的思想
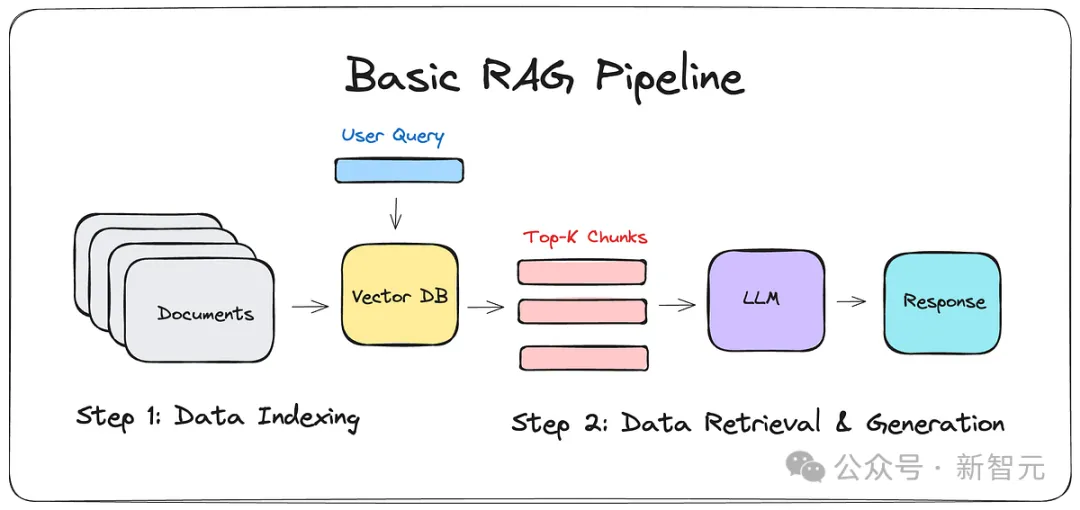
在LLM-WIKI出现之前,主流的解决方案是RAG(检索增强生成)。
简单说,就是给大模型配一个「翻找员」:当你提问时,它去你的笔记里搜几个片段,然后拼凑出一个答案。
听起来很美,但用过的人都知道那种「卖家秀」与「买家秀」的落差。
它只是搬运工:RAG只能处理局部,无法理解全局。
它能告诉你第5篇笔记提到了A,但它无法告诉你这500篇笔记共同指向的底层逻辑。
它会「人格分裂」:如果你半年前认为A是对的,昨天却写笔记反驳了A,RAG往往会陷入自我矛盾,吐出一堆逻辑混乱的废话。
图谱腐烂:手动维护的知识链接,就像没有自动清理功能的代码。日子久了,断头链接随处可见,检索效率呈指数级下降。
Karpathy的直觉非常犀利:搜索和检索是人类无能的表现。我们需要的是「共识」,是「结构」,是「真相」。
把知识当源代码
让LLM当编译器
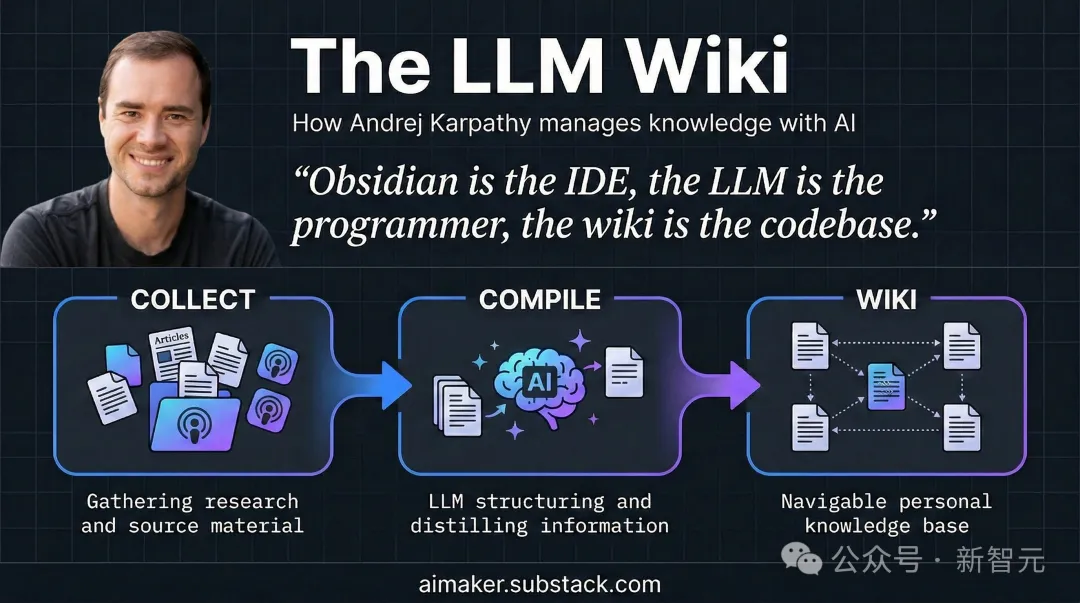
Karpathy的答案,来自一个程序员每天都在做、却从没往知识上想过的动作:编译。
你写好一段源代码,不会每次运行程序都重新读一遍代码。
你把它编译成一个二进制文件,编译这一次很费劲,但之后每次运行都飞快。编译的成本,被之后成千上万次使用摊平了。
知识为什么不能这么干?
Karpathy说,把你的原始笔记当成不可修改的源代码,把LLM当成编译器,让它一次性把这堆乱七八糟的材料「编译」成一个结构化、互相链接的Wiki。
每加一篇新材料,AI就做一次融合:更新相关的条目页、修订综述、把新数据和旧结论打架的地方标出来、顺手加固或挑战已有的判断。
关键的差别在这里:知识被编译一次,然后持续保鲜,而不是每次查询临时重建。
等你来提问的时候,交叉引用早就在那了,矛盾早就被标过了,综述早就反映了你读过的一切。
你不会每次跑程序都重编译一遍源代码。那为什么每次提问,都要让AI重读一遍你的笔记?
认知生产关系的根本转移
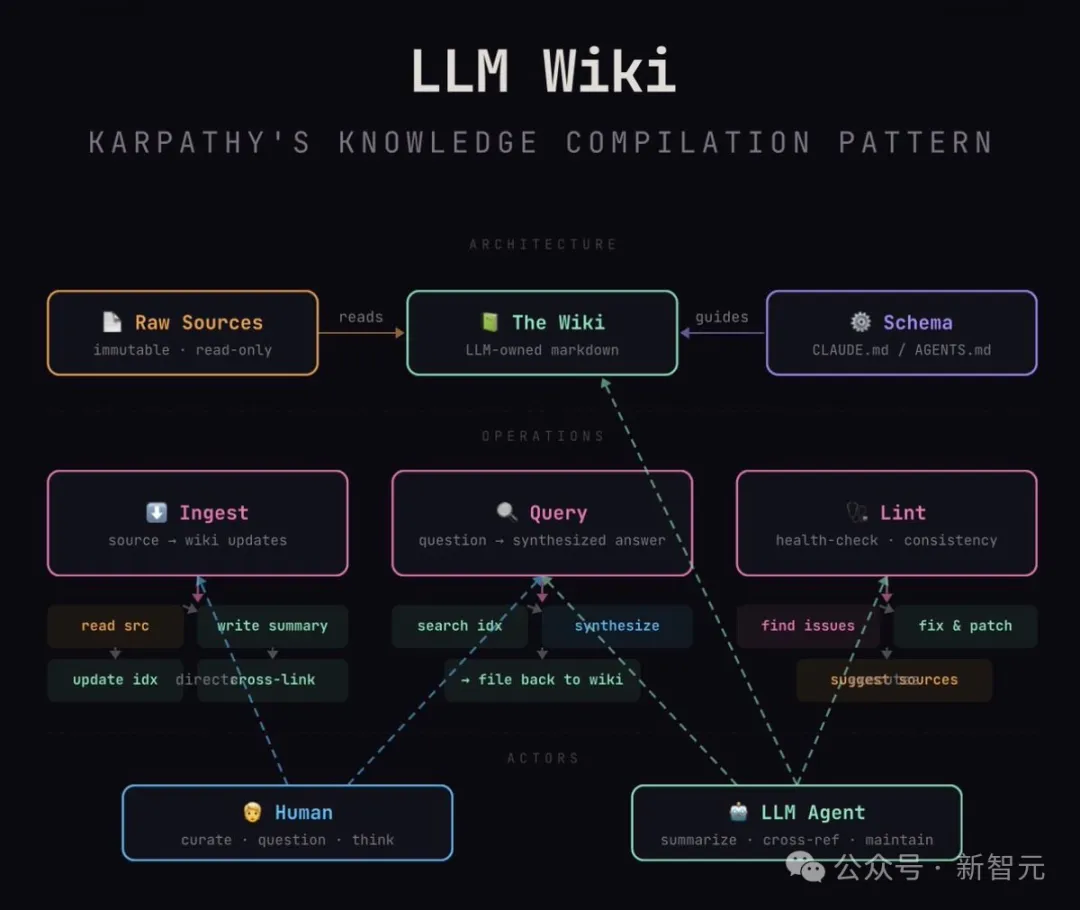
在他的LLM-WIKI框架里,笔记不再是死文字,而是「源代码」。
大模型不再是查字典的翻译官,而是「编译器」。
这套架构极其精妙地实现了三层解耦:
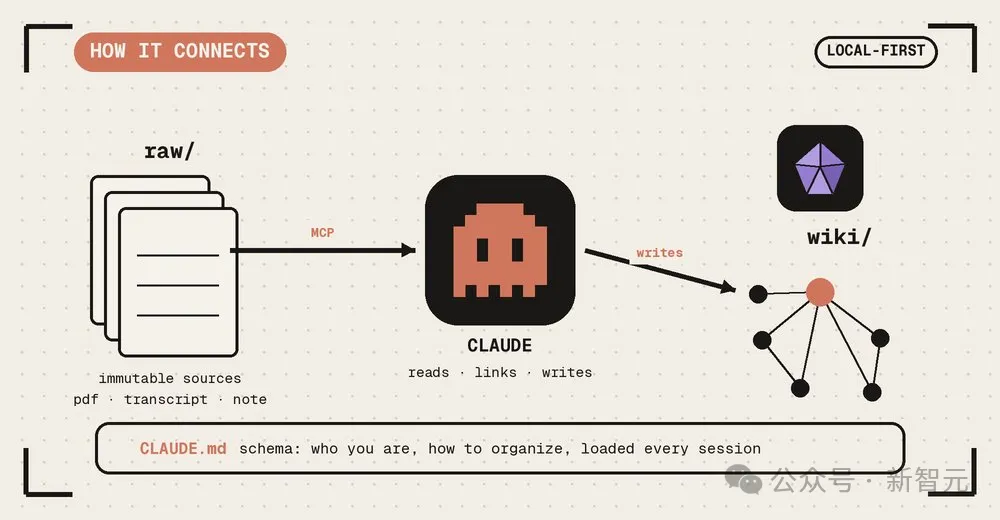
1、Raw层(原始素材):这是你的灵感原矿。你随手记下的感悟、剪辑的文章、会议纪要。它是「不可变」的,保持了人类输入的原始性和不洁感。
2、Schema层(知识宪法):这是你写给AI的「军规」。比如你规定:每一个人物词条必须包含「动机、局限性、关键成就」;每一个技术栈必须说明「优缺点」。
3、Wiki层(编译成品):这是AI全权维护的区域。它根据你的Schema,把那堆乱七八糟的Raw编译成结构化、交叉链接、逻辑自洽的百科页面。