Karpathy内部Claude.md泄露新智元
Karpathy入职Anthropic仅五周,内部实战版10条Claude.md军规意外流出——比GitHub上18万星的4条社区版狠了一倍还多。
前OpenAI大神Andrej Karpathy,入职Anthropic才五周。
昨天,他团队里的人,把他真正在用的那份Claude.md配置文件,发了出来!
然后全网炸了。
推特在传,群里在传,各种社媒都在传。
有人说,从第一条消息开始,差别就很明显——有了这份文件,Claude终于不再跟你对着干,而是完全按你需要的方式工作。
甚至有人表示,「它解决了我们几乎所有当前的任务。」
但这份泄露的文件,可不是之前全网Star爆炸的那个GitHub仓库——它是一份全新的、更狠的内部版本。
十条军规:逐条拆解
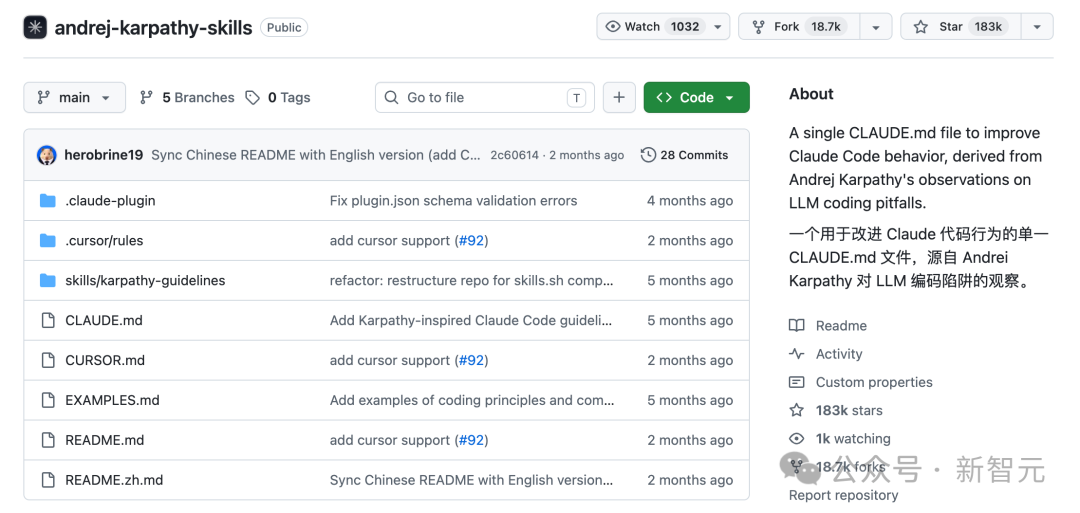
此次泄露的Claude.md不是GitHub上那个18.3万颗星的karpathy-skills仓库。
今年1月26日,Karpathy在X上发了一条长帖,吐槽AI写代码时反复踩的坑:悄悄做假设、过度工程化、乱改不该改的代码、缺乏明确的成功标准。
第二天,开发者Forrest Chang就把这些吐槽提炼成了4条行为准则,做成了那个GitHub仓库——4条规则,65行文本,三个月破10万星。
然而,这次泄露的文件,完全是另一个level!
5月19日Karpathy入职Anthropic预训练团队后,他在内部实战中不断迭代自己的Claude.md。
五周后,团队里有人把这份真正在用的配置发了出来。
打开一看——不再是4条规则,而是一份排版成学术论文格式的十条军规,标题叫:
「CLAUDE.md: Field Notes on Getting a Language Model to Write Code You Will Not Rewrite」
副标题更妙:「A Short List of Rules, Earned by Watching the Same Mistakes Twice」——看够了同样的错误犯两遍,才攒出来的规则。
比之前那4条,多了整整6个全新章节。
这6个章节,才是Karpathy在Anthropic内部真刀真枪干出来的精华。
摘要里一句话就点明了核心:这份文件存在,是因为语言模型写代码时会犯可预测的错误。不是随机错误,而是同样的错误,一遍又一遍。
贯穿每一条规则的核心都一样:模型擅长生成看起来合理的代码,但不擅长发现「看起来合理」跟「真的对」之间的差距——这份纪律,得从过程中来。
接下来,我们来详细拆解这是条军规:
第一条:先读再写(Read Before You Code)。Karpathy说,模型写出烂代码最大的原因,是它根本没读你的代码库就开始动手。
先读,不是扫一眼;去看要改的文件,把已有的模式照搬过来,把import看清楚——弄明白项目实际依赖什么,而不是凭空去猜axios当所有人都在用fetch。
第二条:先想再敲(Think Before You Code)。 搞清楚你要做什么,再动手。
他举了个精准的例子:「添加认证」其实是五件不同的事,把它们列出来、说明取舍。
如果真的搞不懂,那就停下来问——而不是用一段看着像那么回事、实际上一跑就崩的代码来糊弄过关。
第三条:极简主义(Simplicity)。 写能解决眼前问题的最少代码,不是能解决所有未来版本的最少代码。
测试标准:如果某样东西被抽象出来的唯一理由是「以防万一」,那你就过度构建了。
第四条:精准手术(Surgical Changes)。 diff应该和任务一样小。
没让碰的别碰,匹配已有代码风格,不要顺手重排格式——一个格式化器跑一遍,会把真正重要的三行改动埋在三百行无关变更里。
判断标准:你能为每一行改动找到和用户需求的直接关联吗?找不到,就撤回。
接下来6条,才是这次泄露真正炸裂的部分——全是Karpathy在Anthropic内部跟Claude贴身肉搏后新攒出来的:
第五条:验证(Verification)。 你觉得能跑的代码和真正能跑的代码之间,隔着一条叫「测试」的鸿沟。
修bug的时候,别上来就改代码。先把这个bug「录」下来——写一个能把它稳定复现的测试用例。然后再去修。
修完跑一遍,测试通过了,才算真修好了,而不是你「觉得」修好了。
别只测那些鸡毛蒜皮的小事,要测那些真会在用户面前炸掉的场景。如果某样东西你怎么都测不了,别偷懒跳过——那不是测试的问题,那是代码本身设计得有问题。
第六条:目标驱动执行(Goal-Driven Execution)。 堪称整份文件的灵魂。
动手写代码之前,先把「做完了」长什么样说清楚——而且得是能验证的,不能是一句「搞定就行」。
比如老板说「加个验证」,这话太模糊,AI听了会自由发挥。你得翻译成:「用户邮箱没填或者填错了,要弹出明确的报错提示,而且这两种情况都得测过。」
活儿要是分好几步的,先把计划列出来——别让AI闷头干了一小时,你回来一看方向就是错的。
第七条:调试(Debugging)。 东西坏了,去查,别猜。
读完整的报错和堆栈跟踪,先复现问题再动手改,一次只改一个地方。
第八条:依赖管理(Dependencies)。 每一个依赖都是你无法控制的永久代码。