绕开对齐税,奥数暴涨:推理是最后累赘?量子位
传统认知默认:随着网络深度单调递增,思考结果也会变得更准确。
各类开源自回归大语言模型(LLM)的生成,也总是从最后一层输出。
然而,来自Qwen团队、清华大学、南洋理工大学的最新研究成果打破了这一固有假设。
他们揭示了一个普遍存在的“猜想-精炼-扰动”(Guess-Refine-Perturb)动态过程:
模型的中间层往往已经凝聚了最精准的推理语义,而对齐post-training(如 RLHF/DPO)则会在最末几层强加低秩steering扰动,使输出分布向通用、高频的“安全词”倾斜。这种现象被称为“对齐税”(Alignment Tax)。
为应对此种情况,研究团队提出了一种无训练、即插即用的解码策略——Confident Decoding(置信解码)。
实验表明,该方法在Dense和MoE架构上均可取得显著增益,在极难的科学、数学、代码评测集上实现明显的性能增长,且端到端wall-clock延迟增加不足 2%!
灵魂拷问:最后一层,真的总是最好的吗?
大模型在生成下一个Token时,标准做法(Standard Decoding)是将最后一层的隐状态经过Normalization和Unembedding映射到词表。这种方法暗含了一个底层假设:模型层数越深,表征能力越强,最后一层是模型内部计算与最终输出之间的“自然且最优接口”。
然而,真的是这样吗?
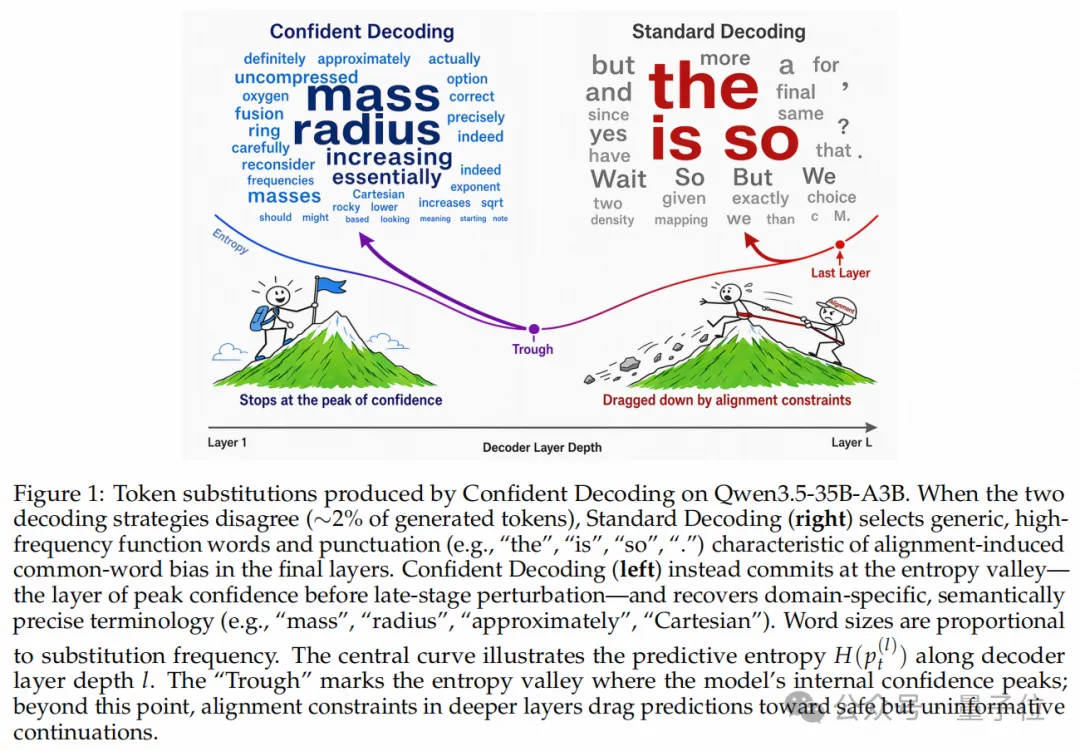
在处理复杂的数理问题时,模型的中间层(熵谷Trough处)其实已经胜券在握,其内部高度确信应该输出mass(质量)、radius(半径)、Cartesian(笛卡尔)等领域内高精度、强语义的词汇。
然而,一旦进入最末几层,受到对齐约束(Alignment Constraints)的强行拉扯,模型在最终层往往屈服于那些泛泛的高频功能词或标点,如the、is、so等。这种现象在复杂推理中导致了致命的“规划-语用权衡”(Planning-Pragmatics Tradeoff):模型内部明明算出了正确的推理路径,却在临门一脚的表达上被带偏了。
为了探究这一底层机理,研究人员深入解构了LLM前向传播过程中残差流(Residual Stream)的动力学特征,量化分析了两个核心指标:
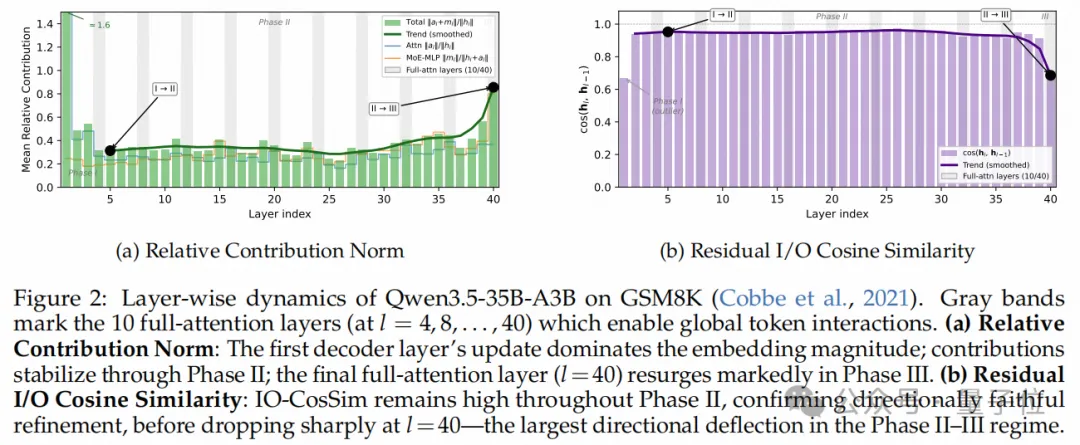
相对贡献模长(Relative Contribution Norm):刻画每一层对残差流的写入强度。
残差输入输出余弦相似度(Residual I/O Cosine Similarity):刻画每一层更新的方向保真度(Directional Fidelity)。
令人惊讶的是,模型的前向传播呈现出极其稳固的三阶段演流规律:
阶段I:猜想(Guess,浅层区,l≤0.15):写入强度极高(Norm Ratio约1.6),方向发生剧烈偏转。模型在极高的不确定性中迅速构建初始的潜在表征。
阶段II:精炼(Refine,中间层,0.15L≤l≤0.95):写入强度骤降并保持稳定(0.23-0.57),而方向相似度极高(0.91-0.97)。这意味着中间层在沿着一条稳定的语义轨迹进行方向保真的增量修正,不断融入上下文。
阶段III:扰动(Perturbation,最末几层,l≥0.95):在最后一层,写入强度反弹,同时方向相似度出现断崖式下跌。这一显著的方向性偏转表明,最末层引入了一个结构上不可忽视、且方向不一致的更新,部分重写并污染了阶段II辛辛苦苦精炼出的推理语义。
机理剖析:“对齐税”与“对齐安全护栏”的博弈
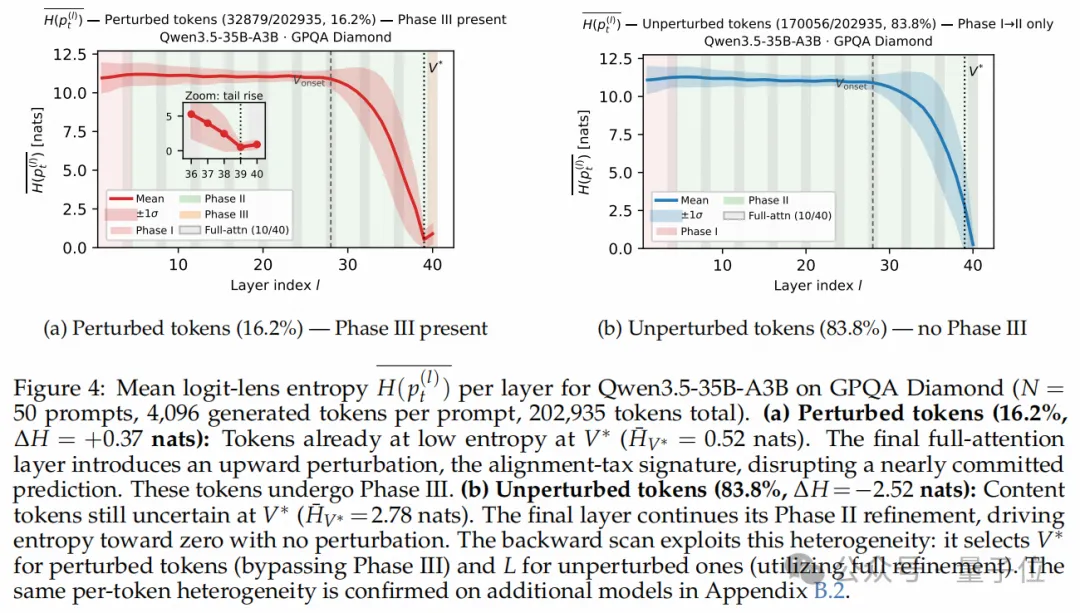
如上图(a)所示,在对Qwen3.5-35B-A3B进行Token级别的追踪时,有16.2%的Token表现出了显著的预测熵(Entropy)在末级回升的特征。这群Token恰恰是推理走向崩溃的“重灾区”(即发生了阶段III扰动)。而其余83.8%的Token(上图(b))则没有表现出扰动,末层依然在老老实实做精炼。
因此,一种理想的提取机制必须是Token自适应(Token-adaptive)的:既能在perturbed token上绕过阶段III,又能在unperturbed token上完整利用最后一层的精炼能力。
破局之法:Confident Decoding(置信解码算法)
为了捕捉这一动态边界,研究团队引入了“熵谷”(Entropy Valley)的概念。既然预测熵(Shannon Entropy)越低代表模型的内部确定性越强,那么扫描靠近末尾的隐层,寻找第一个局部熵最低点,就能近似地锚定模型在受到扰动前的“最自信、最纯净”的语义状态。
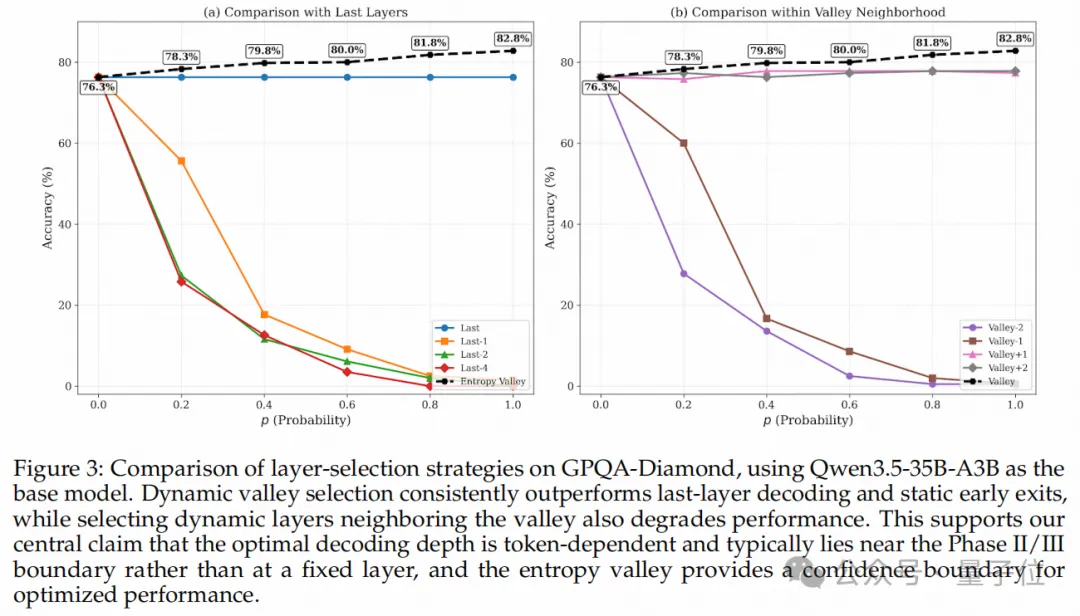
下图提供了与传统算法的鲜明对照。静态提早退出(Static Early Exit)策略由于对所有Token一刀切,会粗暴地掐断困难Token必需的计算量,导致推理正确率雪崩。而基于熵谷(Entropy Valley)的动态选择策略不仅能保持极高准确率,甚至显著超越了标准最后一层输出。
下面是Confident Decoding的核心执行逻辑:
在每一代Token生成步:
模型依然完整执行所有L层的正向传播(这保证了KV Cache、Attention Kernel的行为完全不受干扰,具有工程兼容性)。
从最后一层L开始,沿着一个近末端的候选窗口C,逆向扫描(Backward Scan)预测熵H1。
同时一旦发现熵值不再随着层数变浅而严格单调下降(即遇到了第一个局部熵谷),便立刻冻结选择,将该层计算出的Logits送入Sampler。
理论保证:极小极大最优性(Minimax Optimality)
团队将动态层选择建模为一个最优停止问题(Optimal Stopping Problem)。在数学上证明了(Theorem 1),在投影噪声有界的前提下,这种保守逆向扫描机制能严格将选择层控制在对齐扰动发生前的区间内。它充当了一个确定性的过滤器,消除了对齐税带来的无界风险,同时将投影噪声的惩罚控制在渐进可忽略的界内。这也是为什么该算法天然具备“哪怕无益,损失也在可控范围内”的性能下界保证。
实验结果:全面激活模型的隐藏推理天花板
研究团队在Dense(Gemma-4)和高稀疏MoE(Qwen3.5、gpt-oss)等多种主流架构、不同参数量级上进行了大面积的横向评测。评测集涵盖研究生级科学难题(GPQA-Diamond)、多学科前沿评测(HLE)、奥林匹克级数学难题(Omni-MATH)、代码生成(LiveCodeBench v6)、安全对齐(Air-Bench 2024)以及长文本(LongBench v2)等。