LeCun:关于大模型的下一步Datawhale
Yann LeCun 大家一定不陌生——图灵奖得主、CNN 之父、深度学习三巨头之一。
他的观点散落在各种访谈和推文里,零碎又常被断章取义。所以这次,我们把 LeCun 的判断系统梳理了一遍,连成一条线,看看在他眼里,LLM 接下来该往哪走。
这篇是 Datawhale DIY-LLM 开源项目的拓展篇,带你看看大模型这条路本身能走多远。 文章有点长,大家可以慢慢读~
项目地址:https://github.com/datawhalechina/diy-llm
1. LLM不是终点,但不会消失。它会长期作为"语言与知识接口层"存在,是智能系统的"语言皮层",而非完整大脑。
2. "下一词元预测 + 规模化"很难通向通用智能。核心缺口是两个:预测行动后果的能力,以及基于搜索的多步规划。
3. VLA在当前范式下已接近失败。LeCun直接判断"VLA pretty much seen as a failure",核心原因是可靠性不足、数据依赖过重、泛化脆弱。
4. 世界模型的关键不是"画出世界",而是"在抽象表征空间预测可控后果"。水瓶类比精准揭示了像素级预测的无效性。
5. JEPA的价值在于把学习目标从重建细节转向可预测的语义状态;其成败关键在于防止表示坍缩。当前最有前景的路径是SIGReg方向。
6. LLM本质上不安全,且这一问题在当前范式下无法根本修复。目标驱动AI(Objective-Driven AI)才是安全可控智能体的正确架构方向。
7. 开源生态最终会赢得平台战争。Tapestry联邦训练机制是LeCun对主权AI问题的工程回应。
8. 未来更可能是双系统分工:LLM负责语言与知识交互,世界模型负责理解物理世界与规划行动。
一、为什么LLM不是终点?
LeCun的观点从一开始就很明确:LLM本身并没有问题。 它们已经成为许多实用AI产品的基础设施,我们每天都在使用这些系统,包括他自己也在使用。但他认为,LLM的成功并不意味着它们就是通向通用智能(AGI)的正确路径。
这一判断与许多相信“大规模语言模型持续扩展能够逐步逼近通用智能”的研究者存在明显分歧,其中包括部分来自Google和OpenAI等研究人员。
在LeCun看来,单纯依靠下一词预测和大规模语言建模,并不足以产生类人级智能,甚至难以达到许多动物所具备的那种智能水平——即理解世界、预测行动后果以及进行长期规划的能力。因此,LLM是一种极其成功且有价值的技术,但更像是未来智能系统中的一个重要组件,而非最终答案。
读到这里,你可能已经想反驳了:"LLM明明能推导数学公式、能解释物理定律、甚至能辅助科研——这难道不算'智能'?"
这个反驳非常合理,也是整个争论的核心所在。LeCun并不否认LLM的表现令人印象深刻,但他认为"表现好"和"真正智能"之间存在一个关键的“裂缝”——而正是这道”裂缝“,决定了LLM能走多远。
这道”裂缝“究竟在哪里?我们在第2小节展开分析。
1.1 有意义但不是正确的路线
为什么说路线本身可能是错的? 考虑一个简单的日常场景:“我需要洗车,洗车店离我家100米远。我应该走路去吗?”
图 1 ChatGPT-5.5的回复
GPT-5.5的回答(图1)建议走路去,理由是100米很近、省油省折腾——整个回答听起来头头是道,却将'车必须被开进洗车店'这一最基本的物理前提降格为边缘性的例外。它解决的是一个不存在的问题。
对于我们来说,这个问题几乎不需要思考:你要洗的是车,车必须被开到洗车店才能洗,所以答案是开车去。
但不少的LLM会抓住”100米很近”这一表层线索,建议你”步行“——它在做token级别的预测,而没有理解”洗车需要把车带到现场”这一隐含的物理约束。
这个例子虽然简单,却暴露了LLM的结构性盲区:它缺乏对真实世界物理约束的内在建模能力。但是,这并非我们通常所说的”幻觉”(hallucination)问题,而这里的问题更深层:模型缺少”物理世界中的事物如何相互作用”的内部表征,它只能在语言符号的统计规律中寻找答案。
幻觉通常指模型编造不存在的事实,例如虚构论文、错误引用或捏造数据等问题。
从LeCun等研究者的视角来看,目前的一些改进(比如tool调用、Prompt改进等方法)本质上仍是在现有框架下不断优化模型的表现,而不是改变模型学习和理解世界的方式。就像是给汽车换上更好的轮胎和更强的发动机一样,它们确实能让LLM跑得更快、更稳、更远,但汽车原本的工作原理并没有发生改变。同样,这些方法能提升LLM的表现能力,却无法解决一个更根本的问题:LLM学到的主要仍然是语言符号之间的统计规律,而不是现实世界的运行规律。
一些研究者也注意到了这一问题,开始尝试通过多模态训练来突破纯文本学习的限制。一方面,主要是让模型同时学习文本、图像、视频甚至音频,希望它能够从这些数据中接触到更多关于现实世界的信息,而不仅仅是人类对世界的文字描述;另一方面,近期在高质量文本数据逐渐成为稀缺资源的背景下,多模态数据也被视为新的训练来源。
然而,在LeCun等研究者看来,问题的核心并不只是数据量是否充足,而在于模型是否能够从这些数据中学习到世界的结构、因果关系以及行动后果。即使拥有更多模态的数据,如果训练目标仍然只是预测观测数据本身,也未必能够形成真正意义上的世界模型。
那么,为什么会认为这是一个架构层面的问题,而不仅仅是模型规模还不够大、数据还不够多、数据模态有限的问题呢?要回答这一点,我们需要先思考一个更基础的问题:LLM为什么会如此强大,而让LLM变得强大的,会不会也是限制其本身的?
1.2 LLM为什么会成功?
LeCun认为,LLM能在语言任务上取得巨大成功,一个关键原因在于语言本身是由有限数量的离散token组成的。
这意味着模型的预测目标非常具体:给定已有的文本,从固定大小的词表中预测下一个token的概率分布。这个目标是可计算的,损失函数也是明确的。
在训练过程中,LLM通过阅读海量文本,学习token之间的统计关系和结构模式。LLM十分擅长解决规则明确、可客观验证的领域——数学答案可以代入检验,代码可以直接运行,这让模型在训练时能获得清晰准确的反馈信号,从而被更有效地纠偏和强化。然而,表现出色并不等于真正理解。模型更可能是通过反复见过大量相似模式,习得了一种模式化的解题能力,而非真正理解了数学规律或代码逻辑。就像一个做了十万道例题的学生,解题很厉害,但如果你问他"为什么这个方法成立",他可能说不清楚。一句话总结就是:“知道怎么做 ≠ 理解为什么"。
那么,LLM是如何通过训练泛化到解决不同类型问题的?
LLM本质上是一个巨大的神经网络。预训练阶段,通过反复的前向传播与反向传播梯度更新,将数据中的统计规律逐渐编码进权重空间。而中训练、后训练等阶段,则主要是在这个基础上调整模型的输出分布——让它更符合人类期望的回答风格、价值取向或特定任务需求。
打个比方:预训练像是在一块空地上建造了一座拥有海量藏书的图书馆;而后训练则更像是培训图书馆员,让其知道该怎么回答读者的问题、哪些话该说哪些话不该说——书的内容基本不变,改变的是服务方式。
一些研究发现,LLM在生成回答时,还能够通过链式推理(CoT)或结合显式搜索机制(如MCTS)等方法,表现出一定的推理路径搜索能力。提到搜索能力,这虽很容易让人联想到AlphaGo Zero,但二者之间存在一个根本性的限制值得注意:
为什么不能直接把AlphaGo Zero的方法复刻到LLM上?
AlphaGo Zero的核心优势在于:有明确且可执行的围棋规则作为环境,每一步都能获得真实反馈,最终胜负可以明确验证决策质量,并通过自博弈不断优化策略,整个过程完全不依赖人类棋谱。
而LLM面对的大多数现实任务,根本不存在这样清晰的规则、状态转移和反馈信号。即使引入搜索机制,也很难稳定判断哪条推理路径是"正确的"——这是两者难以直接类比的根本原因。
总结来看,LLM的成功建立在两个支柱上:大规模高质量的人类文本数据,以及通过反向传播不断优化权重的训练机制——模型正是在这个过程中,学会了借助统计规律泛化到各类问题的解法。
然而,这一成功路径本身也埋下了它的限制。自OpenAI提出Scaling Law以及DeepMind的进一步完善以来,业界形成了一个主流共识:模型规模越大、数据越多,能力就越强。既然成功高度依赖数据,那当数据本身开始触及上限,这条路还能走多远?
1.3 规模化或已触及天花板
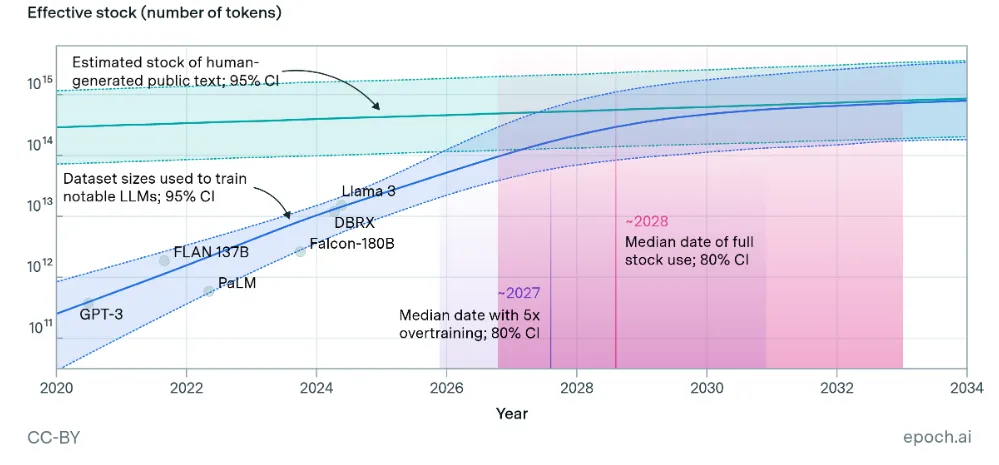
LeCun分析LLM的发展瓶颈时指出,高质量的人类文本数据正在逐渐接近极限。虽然互联网每天仍在持续产生新的内容,但真正适合训练前沿大型语言模型(LLM)的高质量公开文本并不是无限的。
根据Epoch AI的估算,目前可用于训练的大规模高质量公开人类文本数据约为300万亿Token,其95%置信区间约为100万亿至1000万亿Token。研究者进一步指出,如果未来模型继续采用“过训练”策略,即使用更多数据来提高推理阶段效率,那么高质量公开文本库存甚至可能更早被充分利用。