陶哲轩First Proof二期结果出炉量子位
陶哲轩又发成绩单了。
由他主导的First Proof项目第二批评测结果出炉。
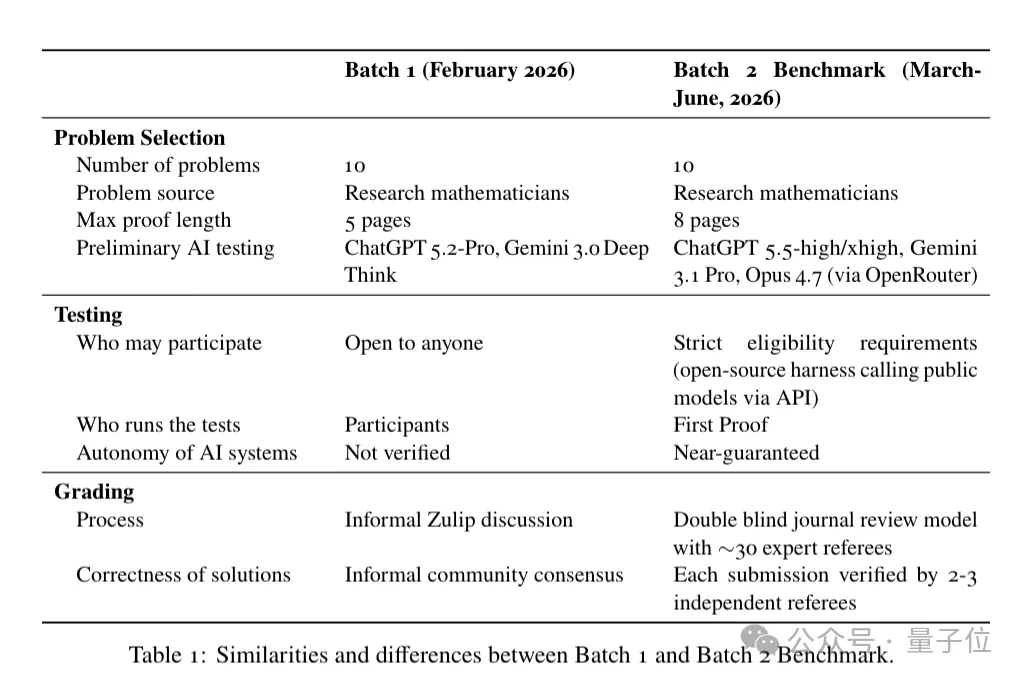
本次评测延续了项目核心规则:选取10道从未在网络、期刊上公布过解法的前沿研究级数学新题,交由AI系统作答。
但相比第一次评测,本次测试进一步提高了标准。
评测全程采用专业的双盲同行评议机制,经专家评定,最终有7道题的AI解答达到学术发表标准,
其中,解得最漂亮的Problem 5——
一道关于随机偏微分方程的问题,AI提出的解法跟人类完全不同,推导得出了比人类解法更强的中间结论。
双盲同行评议
这次的题目是来自数学家真实研究中的新问题。
本次的问题覆盖了可计算理论、离散几何(和经典的莫比乌斯带猜想相关)、离散概率、度量几何(本次测试里AI全军覆没的难题)、随机偏微分方程、格论、组合拓扑、拟阵与热带几何、代数组合、冯・诺依曼代数十大方向。
和First Proof项目第一次评测一样,每一道问题都从未在网上或期刊上公开过证明。
出题人包括Larry Guth这样的顶尖数学家。
第二轮测试相比此前最大的升级,是引入了双盲同行评议机制。
不再让参赛方自己测试,全部由项目组统一操作;还找了30位数学专家像期刊审稿一样盲审打分。
评审只能看到提交的证明稿件,不知道作者到底是AI还是人类。
所有证明按照人类数学论文标准进行审核,并分为四档:
Essentially Flawless(基本无瑕疵):逻辑严谨,几乎不用修改就能直接发表;
Minor Revisions(小修):数学逻辑没问题,只是写错引用、表述啰嗦、小笔误;
Major Revisions(大修):大方向没错,但核心步骤有漏洞,需要专家花大力气补全;
Reject(拒稿):思路错误、关键证明造假、完全答非所问。
参与本次第二轮评测的共有4套AI系统。
System A:IMProofBench
该系统以GPT-5.5 Pro作为核心底座,同时兼容调用GPT-5.5、Gemini 3.1 Pro预览版、Claude Opus 4.7多款大模型协同运算。
System B:UCLA Moonshot Harnes
由加州大学洛杉矶分校团队研发,出自陶哲轩团队之手,该系统统一基于GPT-5.5 Pro搭建。
System C:OpenAI ChatGPT 5.5 Pro
OpenAI官方原生模型,测试过程中开启最高等级推理模式。
System D:Princeton Momus
这是普林斯顿大学团队推出的推理系统,也是本次评测中备受关注的一套方案,其底层依托Gemini 3.1 Pro预览版运行。
本轮测试采用“一题单次作答、无额外交互”的规则,所有系统在统一标准下完成答题。
成本最低8美元
综合39份有效AI解答的评审结果来看,在全部10道难题里,有7道题目出现了达到发表标准的解答,也就是拿到“近乎完美”或“小幅修改即可发表”的评级。
其中苏黎世联邦理工的System A 表现亮眼,在P5随机偏微分方程这道难题里,跳出人类常规思路,用全新方法完成证明,推导出更强的结论。
除此之外,第三题离散概率、第九题代数组合中,部分AI也给出了和人类解法截然不同的原创论证。
面对有成熟文献参考的题目,AI 优势更为明显,比如和经典莫比乌斯带猜想相关的P2离散几何题,三套AI都沿用已有研究思路顺利作答。
组合拓扑、格论等题型上,多套AI也交出逻辑完整的答卷,仅存在行文、格式等小问题。
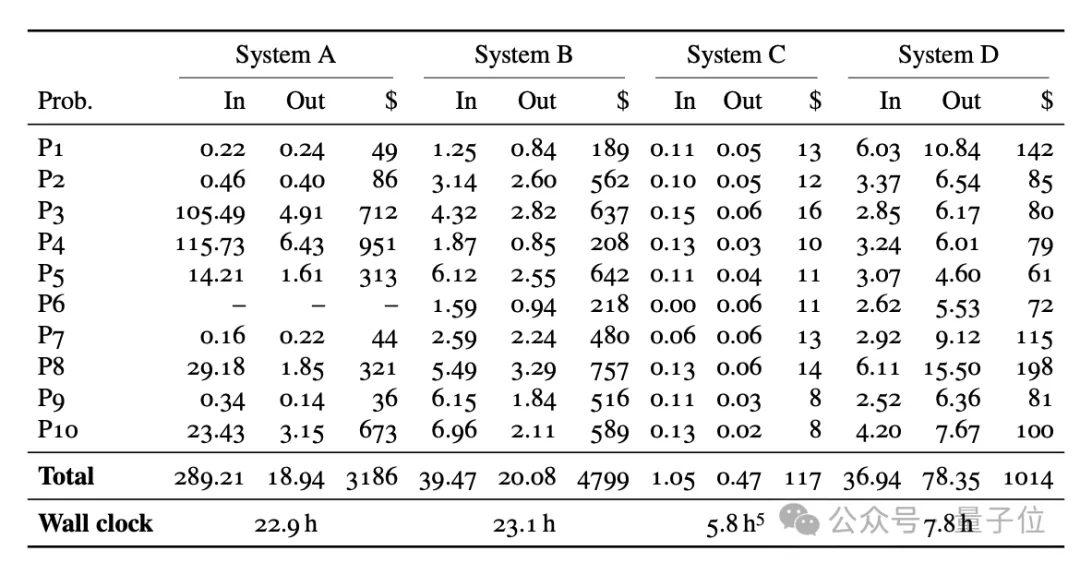
本次评测还统计了四套AI的调用成本与耗时,云服务器总成本不足35美元,可忽略不计,但模型调用费用差距悬殊。
OpenAI原生ChatGPT 5.5 Pro性价比最高,10道题总花费117美元,最便宜的8美元,最贵的也就16美元……
该模型运行5.8小时,耗时最短,但原创能力偏弱;
普林斯顿团队系统花费1014美元、运行7.8小时,投入产出比较低。
解题能力最强的苏黎世联邦理工团队系统总费用达3186美元,单题最高花费951美元,运行时22.9小时;
陶哲轩所在UCLA团队系统成本最高,共计4799美元,运行23.1小时,虽稳定性尚可,却未实现能力突破。
陶哲轩自己也认为本轮整体表现未达预期,现存问题将作为后续优化方向。
同时,后续安排也已经明确,8—10月将开展First Proof项目第三批正式评测,评测规则沿用第二批次标准。
只能说,First Proof——
AI数学最严厉的母亲……