Anthropic万字长文:AI正成为自己的“造物主”硅星人Pro
如果你觉得AI还只是帮你改改邮件、写写周报的小助手,那可能有点低估它了。Anthropic最近把自己家底翻了一遍,发现一个有点震撼的事实:AI正在成为自己的“造物主”。
简单说就是,从前AI怎么进化,每一步都得人盯着、人动手。但现在,Anthropic越来越多地把AI开发的工作,直接交给AI自己干。结果是:工程师每季度合并的代码量,是过去几年的8倍;超过80%的新代码是Claude写的;有些耗时几天的活儿,它两小时就干完了。更厉害的是,AI不光能干活,还能做判断。比如给一个开放的研究问题,它自己能设计实验、跑结果、找答案。在一个AI安全测试里,两个人类研究员花了一周解决了23%的问题,Claude用800小时和一万八千美元的算力,解决了97%。按照这个速度,AI能独立完成的任务时长,大约每四个月翻一倍。去年3月它能干4分钟的活儿,今年已经能干12小时的了。按照这个趋势,2027年左右,AI可能就能干人类需要好几周才能完成的事。当然,Anthropic也说了,这还不是“AI彻底自己造自己”的那一天——但那个叫“递归式自我完善”的东西,可能比大多数人想的来得快。好的一面是,科学、医疗、生产力可能会被推着跑起来。不好的一面是,如果AI真的能自己造自己,人类怎么保证还能“管得住”它,就成了一个天大的问题。这篇文章有点长,但值得看完!
以下为编译。
在 AI 发展史上的大多数时间里,人类主导了它开发周期中的每一个环节。但在 Anthropic,我们正把越来越多的 AI 开发工作委托给 AI 系统自己完成,而这正在显著加快我们的工作速度。
如果把这一趋势继续推远,并给予足够多的算力,它最终会指向一种 AI 系统:它能够完全自主地设计并开发自己的后继版本。这被称为递归式自我改进(recursive self-improvement)。我们还没有走到那一步,而且递归式自我改进也并非必然发生。但它到来的时间,可能会比大多数机构准备得更早。
借助公开基准测试,以及此前从未对外披露的 Anthropic 内部数据,Anthropic Institute 正在展示一个事实:AI 已经开始加速 AI 系统本身的开发。举一个例子:今天,Anthropic 工程师平均每个季度交付的代码量,已经是 2021—2025 年期间的 8 倍。
本文讨论的技术趋势表明,未来几年 AI 系统的能力还将大幅提升。这些趋势意义重大。能够“构建自己”的 AI,将会是技术史上的一个重大节点——它可能像 《Machines of Loving Grace》 所描绘的那样,在科学、医疗等领域为世界带来巨大的善意与进步。但完全意义上的递归式自我改进,也可能增加人类失去对 AI 系统控制的风险。如果系统真的具备完全构建其后继版本的能力,那么我们如何保障其安全、如何监控它、如何塑造它的行为,都会变得重要得多。
来自外部世界的证据
AI 模型提升的速度正在加快。它们能够可靠独立完成的任务时长,已经从更早期大约每七个月翻一倍的趋势,加速为如今大约每四个月翻一倍。2024 年 3 月,Claude Opus 3 还能完成大约相当于人类 4 分钟工作量的软件任务。一年之后,Claude Sonnet 3.7 已经能处理相当于人类约 1 个半小时的任务。再过一年,Claude Opus 4.6 已经能完成 12 小时级别的任务。[^1] 如果这一趋势延续下去,那么今年之内,熟练人员需要花上数天才能完成的任务,就可能进入 AI 的能力范围;到 2027 年,AI 系统或许将能胜任那些人类需要数周才能完成的任务。
同样的模式也出现在编码与研究基准测试上。基准测试衡量的是模型在某一特定领域中的表现,而当模型成绩接近 100% 时,我们就说该基准被“饱和”了。[^2] SWE-bench 是现实世界软件工程的标准测试之一:它会给模型一个真实的开源代码库和一份真实 bug 报告,要求模型写出能修复问题、并通过项目自身测试的代码变更。仅仅两年时间,模型就在这个基准上从个位数低分一路走到接近饱和。
CORE-Bench 测试的是模型能否复现已有研究结果,这也是其未来开展原创研究的前提。测试方式是向 AI 模型提供一篇已发表论文背后的代码与数据,并要求它重新运行全部流程,确认自己能够复现实验结论。AI 系统在 2024 年时,复现成功率大约只有 20%;而仅仅 15 个月之后,这一基准也已趋于饱和。负责长时任务能力评测的 METR 还发现,Claude Mythos Preview 已经能够工作“至少”16 小时,而且已经“触及 [METR] 在不引入新任务前提下可测量能力的上限”。
公开基准可以告诉我们很多关于系统能力本身的信息,但它们无法直接揭示 AI 系统究竟在多大程度上加速了 AI 自身的开发。要回答这个问题,我们需要来自 Anthropic 这类 AI 公司内部的一手证据。
Anthropic 内部的证据
构建一个前沿模型,大致可分为两类工作。其一是工程:编写代码、搭建基础设施、监督模型训练。其二是研究:决定要做哪些实验、解释实验返回的结果,并判断接下来该尝试哪些想法。
无论在工程还是研究上,呈现出的图景都相当一致。在工程侧,Claude 已经能够接收一个定义并不充分的问题,然后自行摸索解决路径;人类提供的是目标,但不再需要提供方法。在研究侧,Claude 已经可以在执行一个定义清晰的实验时,达到甚至超过熟练人类研究者的水平。不过,在工程和研究中,Claude 在“选择目标”时所需的判断力上,依然存在明显能力差距。这正是今天的 AI 与未来那种可以自主设计自己后继者的系统之间的差别。
在 Anthropic,员工通常会随着经验增长而接到越来越开放、也越来越重要的任务。初期,他们执行别人已经定义好的任务,比如:“导出按钮坏了,请修一下。” 随着经验增加,他们会拿到一个目标,然后自己设计实现路径,比如:“调查一下为什么网络在高负载下会变慢。” 而到了最资深的层级,他们决定的已经是“什么问题值得做”,例如:“团队下个季度应该做什么?” 我们可以借助 Anthropic 内部数据,看看 Claude 在应对这些不同类型任务方面已经走到了哪一步。
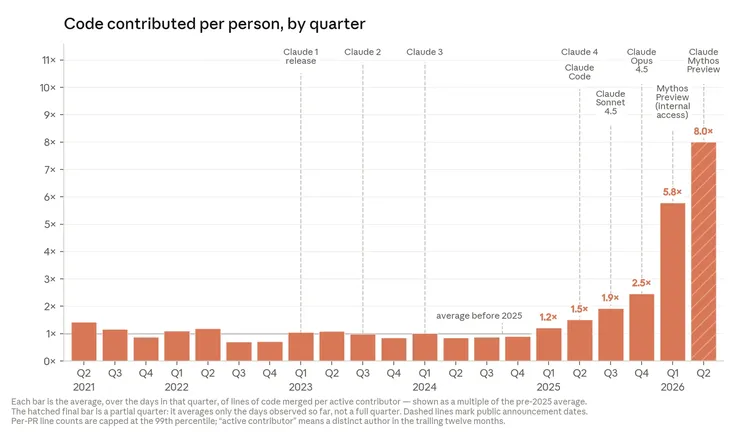
Claude 正在编写 Anthropic 相当大比例的代码。 截至 2026 年 5 月,Anthropic 代码库中合并进主分支的代码里,超过 80% 出自 Claude。[^3] 在 2025 年 2 月 Claude Code 研究预览版发布之前,这个数字还只是个位数低位。这种变化也体现在了工程师的人均产出上。Anthropic 创立最初四年(2021—2024),每位工程师每天合并的代码行数基本保持稳定;到了 2025 年,当 Claude 开始不再只是“建议代码”,而是直接“运行代码”时,这条曲线开始向上抬升;到了 2026 年,模型能够在更长时间跨度上自主工作后,斜率再次明显变陡。下面这张图展示了这两个拐点。到 2026 年第二季度,典型工程师每天合并的代码量,已经是 2024 年时的 8 倍。[^4] 原因很简单:很多代码已经由 Claude 写出,而工程师的角色转向了指挥与审阅,而不是亲手逐行敲写。
当然,需要注意的事:代码行数并不是完美指标,因为它衡量的是数量而不是质量。所以,2026 年第二季度“每位工程师每天 8 倍代码行数”,几乎肯定高估了真实生产率提升的幅度。但无论如何,它说明了一件事:速度正在加快。在 Anthropic,我们并不会按照“你写了多少行代码”来奖励员工;团队成员之所以产出更多代码,只是因为他们正在用 AI 系统写出更多代码。
代码行数的增长,也与员工对生产率显著提升的主观感受相吻合。2026 年 3 月,在 Anthropic 研究团队 130 名员工参与的一项调查中,受访者中位数估计:在“无论如何本来也会做的那些项目”上,使用 Mythos Preview 后,他们的产出大约是“完全没有 AI 可用”情况下的 4 倍。[^5] 我们预计,3 月时真实的提升幅度可能比这个数字略低。[^6] 尽管如此,我们依然认为整体结论可信,也与我们的其他观察一致:Anthropic 中相当一部分技术员工,正在以没有 AI 帮助时数倍的速度完成自己的核心工作。
我们还看到一些证据表明,Anthropic 员工正利用 Claude 去完成那些如果没有 AI,本来根本不会去做的工作,比如搭建探索性工具、或者清理那些长期被搁置的问题。举例来说,2026 年 4 月,Claude 一次性交付了 800 多个修复,把某一类 API 错误减少到了原来的千分之一。负责监督 Claude 的工程师估计,如果让人类来做,这项工作需要整整 4 年;修别人的 bug 本来就是一件缓慢、繁琐、极其消耗精力的事,而人类也很难同时在脑中维持如此庞大且陌生的上下文。
“大约一年前,我开始非常激进地推进‘Claudifying’。那是一段非常疯狂的旅程,而到现在,大概已经有 5 个月,我再也没亲手写过任何代码了。”——Anthropic员工
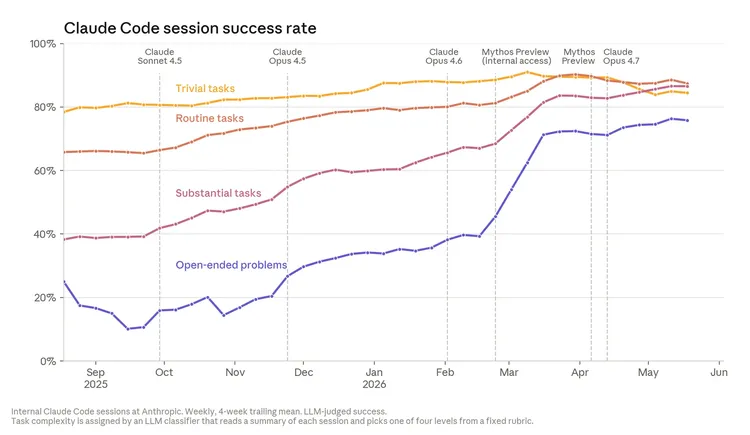
Claude 写出来的代码是“好的”,而且还在持续变好。 “好代码”包含两层含义:第一,它能正常工作;第二,它的写法要让另一位工程师能够理解、并继续在其上迭代。对第一条标准而言,证据已经很清楚。过去一年里,Anthropic 员工在任务进行过程中对 Claude 进行纠正、重定向,或直接接管的频率一直在稳步下降,哪怕是在最复杂、最开放的问题上也是如此。所谓“开放问题”,是指那些没有明确规格说明、工程师自己也不确定正确答案长什么样的问题。下图展示了 Claude 在不同难度任务上的成功率变化。Claude 已经能写出真正可运行的代码。
如何理解这张图: 会话是否成功,由一个 Claude 裁判来判断;如果 Claude Code 代理明显完成了用户任务,而且过程中不需要人为纠正,则该会话被视为成功。工作负载的变化可能导致成功率出现短期波动。
在最开放的那类任务上,Claude 的成功率到 2026 年 5 月已经达到 76%,在 6 个月内提高了 50 个百分点。举个这类任务的例子:一次常规升级导致数以万计的训练作业崩溃。一位工程师几乎只给了 Claude 一点文本信息和集群访问权限,就把实时事故交给它处理。Claude 一边检查运行中的作业,一边逐项测试环境设置,最终锁定了一个触发崩溃的隐蔽调试标志位,成功稳定复现问题,并确认了解法。大约两小时内,Claude 完成了通常需要两到三天才能做完的工作。
第二条标准,是代码是否写得足够清晰,让另一位工程师能看懂并在其上继续开发。在这一点上,人类与 AI 之间的差距依然存在,但正在迅速缩小。Anthropic 内部对此并非完全一致,但许多人认为:在 2025 年末,Claude 写的代码质量仍明显逊于 Anthropic 工程师自己写的代码;而到今天,两者已经大致持平。我们预计,在一年之内,Claude 写出的代码会更好。
这也改变了 Anthropic 审查代码的方式。如今,提交到代码库中的变更会先由一个自动化的 Claude 审阅器读取,它会在代码合并之前检查 bug、安全漏洞以及其他缺陷。利用这一工具,我们做了一次回溯分析,发现:如果过去对代码库中的每一次改动都进行自动化 Claude 审查,那么 claude.ai 过往事故背后大约三分之一的 bug,本来都可以在进入生产环境之前就被拦截下来。写下那些代码的工程师,本身已经是世界上最擅长构建这类系统的人之一。如今,Claude 已经能抓住他们遗漏的错误。
“在 2025 年末,Claude 写的代码质量还比 Anthropic 人类工程师写的差一些;今天,它大致已经达到同等水平;而我们预计,在一年内它会严格意义上超过人类。”——Anthropic员工
Claude 已经很擅长围绕别人设定的目标来跑实验。 每次 Anthropic 发布新模型时,我们都会进行同一个测试:给 Claude 一段用于训练小型 AI 模型的代码,要求它在仍通过相同正确性检查的前提下,把这段代码跑得尽可能快。目标和评估标准事先就被固定好了,所以 Claude 的任务就是通过改写代码、运行代码、计时,再重复这一过程来寻找加速方法。这相当于一个缩小版的实验研究闭环。2025 年 5 月,Claude Opus 4 相比起始代码平均实现了约 3 倍加速;到 2026 年 4 月,Claude Mythos Preview 已经达到约 52 倍。作为参照,一个熟练的人类研究员通常需要 4 到 8 小时,才能做到 4 倍。[^7] 在研究流程的这一环——也就是在定义清晰的实验里做步骤优化——Claude 在不到一年的时间里,就从“非常有帮助”跨越到了“超过人类”。