DeepSeek塞进苹果本儿,实现“龙虾自由”字母AI
在agent时代最贵的是什么?是token。
一些重度agent使用者,一个月用掉几亿token,账单小几万块钱也是常有的事。
然而现在开始,有这么一个开发者他开源了一个本地方案,一台苹果笔记本就能部署,也就是说,你从此实现了“龙虾自由”,跑再多任务,也不会再为token付出一分钱了。最关键的是,他用的还是DeeSeek V4 Falsh。
几天前,antirez在GitHub上发布了一个项目,叫ds4。
这是一个专门为DeepSeek V4 Flash写的推理引擎。一共几千行C代码,可以让DeepSeek V4 Flash这个模型在128G内存的苹果电脑上跑起来。
开发者antirez,本名Salvatore Sanfilippo,是意大利程序员,同时他也是开源数据库Redis的原作者。Redis后来成为全球互联网基础设施里最常用的内存数据库之一。
往好的方面去想,DeepSeek影响力足够大,吸引到了圈内顶流的程序员,但是坏的方面是,DeepSeek这回真的免费了。
任何开发者都可以用ds4,去把DeepSeek V4 Flash装进自己的MacBook Pro里,本地跑代码、本地读上下文、本地做agent任务,而这一切的一切,不需要给DeepSeek付1分钱。
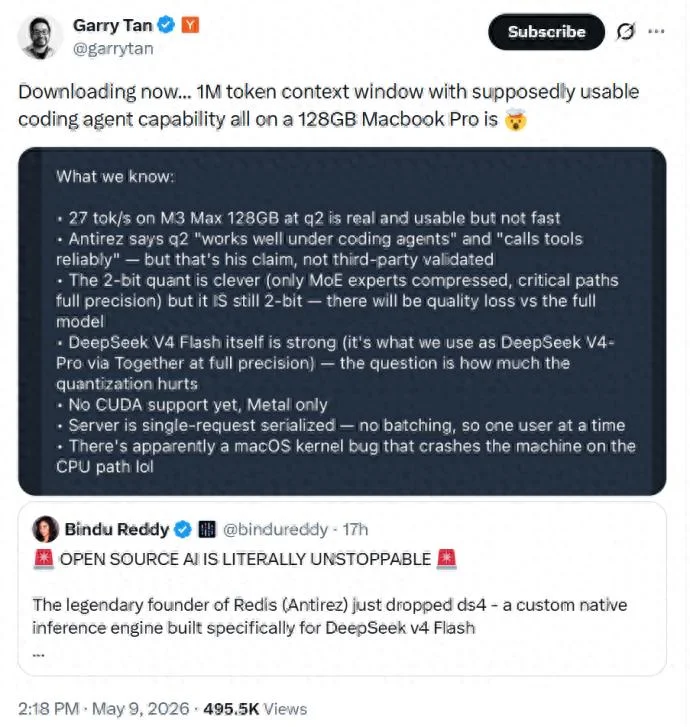
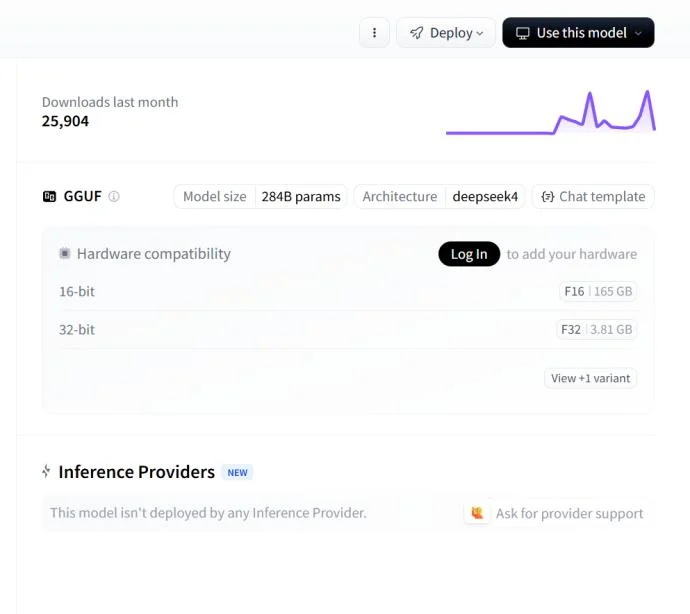
虽然DeepSeek V4 Flash本身开源,可FP16精度的原始模型要吃掉284G内存,显存需求更是高达160G。
因此,想运行它,你至少得有两张英伟达A100 80GB、一条512GB DDR5 ECC内存,以及一个4TB NVMe SSD。总成本50万人民币。
而现在,一台3万块钱的MacBook Pro就能跑。
那antirez为什么偏偏选中DeepSeek V4 Flash呢?
原因是DeepSeek最适合被“塞进本地电脑”。
它有284B总参数,足够大;但每次推理只激活13B参数,又不像传统大模型那样沉重。
它支持100万token上下文,适合编程助手这种长任务;同时KV cache压缩得足够狠,给本地内存和SSD留下了操作空间。
DeepSeek V4 Flash刚好站在了这样一个神奇的平衡点上,既大到值得折腾,又小到能被塞进苹果笔记本里。
YC的CEO Garry Tan在X上转了这条消息,只打了一行字:正在下载……100万token上下文窗口,可用的编程助手能力,全在一台128GB的MacBook Pro上,太疯狂了。
ds4究竟是什么?
先说结论,ds4不是一个模型,它是一台“专用发动机”。DeepSeek V4 Flash是车,苹果电脑是路,ds4负责把这辆原本更适合跑在云端的大车,改到本地机器上能跑、能接API、还能被coding agent调用。
过去大家想在自己电脑上跑大模型,普遍用的都是llama.cpp这个工具。它的好处是什么模型都能跑,Llama、Qwen、DeepSeek全都支持。
可问题就是,什么都能跑,就意味着什么都跑不到最快。为了照顾所有模型,llama.cpp必须做很多妥协,性能上不可能做到极致。
antirez的想法正好相反,他才不管别的模型死活,他就专门伺候DeepSeek V4 Flash这一个,把它优化到极限。
他一共做了3件事。
第一件事,是不对称的2-bit量化。
DeepSeek V4 Flash的架构是MoE(Mixture of Experts),284B总参数里,每次推理只激活13B,这13B是路由挑出来的若干个专家子网络。
就像一个工具箱里有284把工具,每次只拿出13把来用。这284B里面,有一大堆“备选专家”占了90%以上的空间,但它们不是每次都用,只是候补。
antirez的做法是,只对这批routed experts做激进的2-bit量化,up和gate矩阵用IQ2_XXS,down矩阵用Q2_K,而模型里所有关键路径上的组件,包括shared experts、projections、routing网络,全部保持原始精度不动。
也就是说,antirez把这些“候补专家”狠狠压缩,压到只剩原来1/4的大小,但那些每次都要用的核心组件,一点都不动,保持原样。
这是一种不对称的压缩策略,砍掉体积大头,保住质量命脉。
第二件事,是把KV Cache搬到SSD上。
DeepSeek V4 Flash支持100万token的上下文,这相当于你可以把一整本小说扔给它,它能全记住。
但这么长的上下文,意味着AI在工作时要不停地回头翻看前面的内容。为了让这个“回头翻看”的动作不至于慢到卡死,AI需要把这些内容暂存在一个叫“缓存”的地方,方便随时调用。
以前的做法是把这个缓存放在内存里。内存速度快,AI每次生成一个字都要频繁查这个缓存,所以必须放内存。
但问题是,如果让128GB内存的MacBook Pro跑DeepSeek-V4 Flash,光缓存就能把内存吃光,模型本身都没地方放了。
所以antirez的做法是直接把缓存扔到硬盘(SSD)上。ds4把一部分KV状态做成可落盘、可恢复的缓存,让长提示词和agent反复续写时,不必每次从头处理。
这听起来有点离谱,因为硬盘比内存慢多了。
然而现代Mac SSD足够快,适合做KV缓存持久化和恢复。加上DeepSeek V4 Flash本身对缓存做过压缩,读写量不大,所以硬盘完全顶得住。
结果就是内存省出来了,100万token的超长对话真的在一台MacBook上跑起来了。
不过这不等于128GB MacBook可以毫无压力地把100万token全部拉满。
按照ds4自己的说明,2-bit模型本身已经要占掉大约80GB级别的内存,真正日常使用时,100k到300k上下文会更现实一点。
第三件事,是纯Metal原生路径。
antirez把所有优化都押在苹果电脑的GPU上。
因此他专门为苹果芯片写了一套代码,让DeepSeek V4 Flash能在苹果电脑上跑得飞快。
至于CPU,并不是这个项目的重点。README里也写得很直白,CPU模式目前还不稳定,甚至可能触发系统崩溃。antirez进一步表示,如果有人真想走这条路,后续大概还得靠社区来补救。
在M3 Max 128GB的MacBook Pro上,实测速度是每秒能生成26个字左右。M3 Ultra 512GB的Mac Studio上能跑到每秒36个字。
不算快,但写代码、调试这些日常工作完全够用。
更有意思的是,antirez是独自一人通过GPT-5.5完成的整个这个项目。
利好DeepSeek
根据外媒报道,DeepSeek目前正在寻求高达73.5亿美元的融资,梁文锋现在就处在这个关键的转折点上,用商业叙事取代DeepSeek过往的技术叙事。
那投资人看什么?不只是看模型跑分,不只是看API调用量,更看生态位和不可替代性。
一个海外知名开发大佬,愿意为你的模型写专用引擎,这本身就说明DeepSeek在海外有着一定的生态地位。
过去一年,中国开源模型的出海叙事里,主流衡量标准是benchmark,MMLU、HumanEval、SWE-bench,一串又一串的数字。
但有人愿意围绕你做二次工程,才代表你的模型被认可了。Anthropic用千问做实验,Cursor蒸馏Kimi,这种认可比分数更值钱。
antirez不是AI圈里那种什么新模型都要试一遍的博主
他选一个模型,然后还要花几周的时间去写专用推理引擎、做特制量化、搭HTTP服务层、做agent集成测试,显然是他认为DeepSeek值得。
这就变相等于,一个有信誉的第三方,在用自己的时间和名声给DeepSeek-V4背书。
说到国产模型出海,目前我能想到的路有两条。
一条是API被调用。你提供服务,别人付费使用,你是service provider,客户是consumer。
这条路很直接,也很现实,别人可以随时切换,你无时无刻都得对抗你的竞品,从性能到价格。
另一条是模型被改造。有人把你的权重拿走,做量化、做蒸馏、做专用runtime、做本地部署、做agent工具链。在这条路里,你的模型成了材料。
材料和服务的区别在于,材料会被嵌入到别人的工具链里,然后就很难被换掉了。
举个例子,某个开发者把ds4集成到自己的coding agent里,写了一堆配置文件、调试脚本、自动化流程。他的团队成员也都习惯了这套工具,公司的代码库里到处都是基于DeepSeek本地推理的调用。
这时候如果要换成别的模型,就不是“改个API key”那么简单了,而是要重新适配引擎、重写脚本、重新培训团队习惯。成本太高,大概率就不换了。
这就是“被嵌入”的粘性。
ds4把DeepSeek V4 Flash嵌进了Metal原生本地推理这个场景。截至发稿,Hugging Face上antirez那个deepseek-v4-gguf仓库,就已经有25000次下载了。
每一次下载,都意味着有人在自己的机器上跑起了DeepSeek,粘性也就这么一点一点的建立起来了。