菲尔兹给数学和AI的一封信:压缩即是全部AI-lab学习笔记
2017 年 6 月,Google Brain 的八个人把一篇论文扔上了 arXiv。
标题狂得不像论文:《Attention Is All You Need》。
九年过去了,这个标题成了 AI 史上最著名的七个单词。基于它的 Transformer,撑起了 ChatGPT、Gemini、Claude、DeepSeek、万亿市值、一代人的焦虑。
2026 年 3 月 27 日,又一篇论文悄悄上了 arXiv。标题只有七个单词,格式一模一样:
Compression is all you need: Modeling Mathematics
看到这个标题,任何做 AI 的人都会下意识笑一下——"又一个蹭热度的"。点开作者一栏,笑容消失。
Michael Freedman。
这不是什么 ML 工程师。这是 1986 年菲尔兹奖得主,四维庞加莱猜想的证明者,过去二十年微软 Station Q 的灵魂人物,当今在世的数学家里戏份最重的那一批。
他在写 AI?不是。他在告诉所有搞 AI 的人:你们一直在用的那个词"压缩",其实比你们想象的要深得多。
这篇文章不是《Attention Is All You Need》那种工程突破。它是一封信——一位数学家,用他毕生训练出来的直觉,回答了三个困扰人类上千年的问题:
人类究竟是怎么构建数学知识的?
人类做的数学,和形式化的"纯逻辑数学",本质区别是什么?
未来的人类数学家,到底该怎么和 AI 协同工作?
他给出的答案,只有一个词:压缩。
今天这篇文章,就把这封信翻译给你。
第一章:Freedman 是谁
先说清楚为什么这个人开口说话,AI 圈必须听。
1981 年,三十岁的 Freedman 在加州大学圣地亚哥分校解决了四维庞加莱猜想——这个问题悬了 77 年。三维版本让 Perelman 在 2006 年拿到菲尔兹奖(他拒绝了);五维以上早在 60 年代就被解决。唯独四维——卡在最要命的那个维度——是 Freedman 攻下来的。
1986 年,柏克莱,国际数学家大会。Freedman 领走了菲尔兹奖。
1997 年,Freedman 做了一件数学家很少做的事——从学术界出走。微软给他开了一个几乎是为他量身定做的部门 Station Q,目标只有一个:用数学家的思路造拓扑量子计算机。他当了主任,一干就是二十五年。
2023 年,他回到哈佛 CMSA(数学与应用中心),换了一个身份:思考 AI 和数学的关系。
所以当 Freedman 这个人在 2026 年 3 月扔出一篇叫《Compression is all you need》的论文——这不是某个追热点的研究员,这是一个一辈子在数学内部看世界的人,突然转身跟所有人说:
"我看清楚了一件事。你们要听吗?"
第二章:一个让所有人尴尬的事实
Freedman 论文的切入点,是一个数学界人尽皆知、但几乎没人能解释的尴尬事实。
先建立两个概念:
形式数学(Formal Mathematics, FM):所有合乎逻辑规则的推演。
人类数学(Human Mathematics, HM):人类真正写下、收录、引用的那部分数学。
FM 的空间有多大?假设你有 n 个基础符号,组合出来的"合法推演"是指数级——n 上百以后就超过了整个宇宙里的原子数。
HM 呢?从欧几里得到今天所有数学家加起来写过的定理,约百万量级。Lean 4 的 MathLib 收录其中约 14 万条。
两个数字并排写
FM:> 1080
HM:~ 105
中间隔了 75 个零。
人类数学,是形式数学这个宇宙里一粒尘埃都不到的小角落。
而且——为什么是这一粒?
FM 里有无穷无尽的"合法但无聊"的定理。比如:"对任意整数 n,n + 0 = n","对任意整数 n,n + 0 + 0 = n","对任意整数 n,n + 0 + 0 + 0 = n"……每一条都合法,每一条都无意义。人类数学家从来不写这些。
一百年来这个问题有过无数个哲学回答:"美""简洁""有用""深刻"——都是词语的游戏。没有一个是数学答案。
直到 Freedman 2026 年给出了第一个能算的回答:
因为 HM 是 FM 里那个"可压缩"的子集。
第三章:压缩——先站在日常地面上
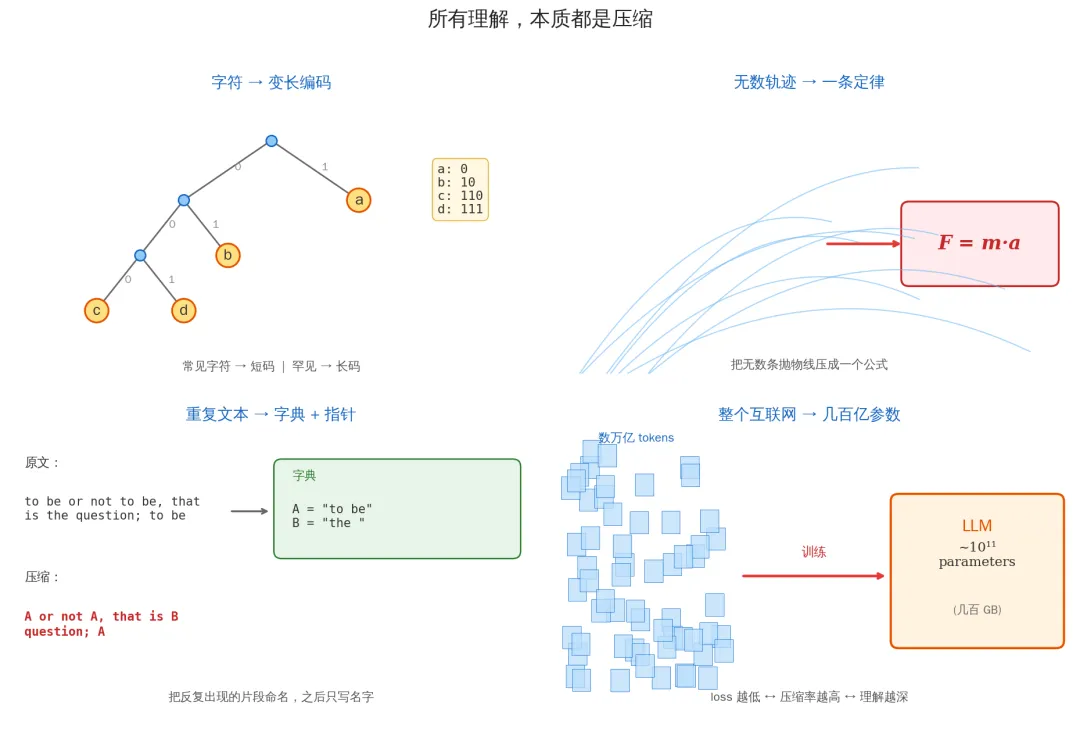
Freedman 说的"压缩"是什么意思?先别想数学,先想几个你已经懂的例子。
例子一:Huffman 编码
你家猫叫小花。照片里出现最多的动作是"睡觉"(4000 次),其次"吃饭"(3000)、"抓沙发"(2000)、"发呆"(1000)。
固定 8 位编码:80000 位。Huffman 编码:"睡觉→0;吃饭→10;抓沙发→110;发呆→111"——19000 位。压缩率 4 倍,没有丢失任何信息。
只要事物分布是不均匀的,就存在压缩。
例子二:牛顿三定律
宇宙里每一秒都在发生无数次的运动:苹果落地、月亮绕地、弹簧振动、子弹出膛、潮汐起落……你想记录所有这些运动,需要多少信息?
你只需要记住 F = m·a,外加两条(惯性、反作用),就能重新生成上面所有运动。
牛顿三定律是一个几十字符的程序,它编码了经典力学的全部。
例子三:zip 文件
"to be or not to be, that is the question; to be"——把反复出现的"to be"和"the"命名成 A、B,之后只写名字。这是 LZ77 算法(zip / gzip / PNG 的底层),1977。
例子四:大型语言模型
喂整个互联网给 LLM——几万亿字、几百万小时文本。训练完得到几百亿参数的模型(几百 GB)。它能生成类似训练集里的任何内容。
这件事,用信息论的语言说叫:LLM 就是互联网的一次有损压缩。
DeepMind 2023 年做了一件让人血压升高的事:他们把 Chinchilla 70B 当成一个通用压缩器,用它去压缩原始字节流——不仅是文本,还有从没训练过的图像和音频。结果:
文本压缩率:比 gzip 好很多
图像压缩率:比 PNG 好
音频压缩率:比 FLAC 好
一个只训练了语言的模型,居然能压缩它从没见过的图像——因为它学到了"通用的世界结构"。
从 Huffman 的字符编码到 LLM 的几百亿参数——压缩的颗粒度越来越粗,本质是同一个。
任何"理解"的行为,本质都是找到更短的描述。
这不是比喻。这是 Freedman 论文的出发点。
第四章:Freedman 的建模——字符串和"宏"
Freedman 说的第一件事:把数学推演当成字符串。你在黑板上写证明,本质就是一串字符。所有"合法的证明字符串"排起来——就是 FM。
但数学家从来不这样写。他会说:"设 f 在 [a, b] 上连续,则 f 一致连续。"
"连续"是一段定义,展开约三行字符。"一致连续"是另一段,展开约五行。表面 20 个字,完全展开超过 100 个字符。继续挖下去——一条"短句子"背后,是一棵很深的定义树。
Freedman 给这种"名字 → 一段长字符串"的约定起了个名字:宏(macro)。
"连续" = 一个宏
"一致连续" = 一个宏
"积分" = 一个宏(调用"极限""分割""黎曼和"的宏)
"勒贝格积分" = 一个宏(调用"测度""可测函数"的宏)
"黎曼-勒贝格引理" = 一个宏(调用以上所有)
一条现代定理"完全展开"往往是亿级字符。但数学家永远只看最外层。
数学家的工作,就是不断造宏。
一位数学家的一生,可能就干了一件事——看到了一个之前没人压缩过的模式,给它起了一个名字。
高斯给"正态分布"起了名字。黎曼给"流形"起了名字。伽罗瓦给"群"起了名字。康托尔给"集合"起了名字。图灵给"可计算性"起了名字。香农给"熵"起了名字。
你今天学的所有数学,都是在站在前人造好的宏上。如果不能层层压缩,人类根本学不动数学。
第五章:$A_n$ vs $F_n$——两种宇宙
到这里一切都是直觉。Freedman 接下来要做的,是把这个直觉变成数学。
他引入两个代数对象(别紧张,用直觉讲):
A_n 像拼乐高
你有一堆乐高积木——红、蓝、绿。红拼蓝上加绿,还是先绿再蓝再红——最后模型一样。顺序无关紧要,只在乎哪些积木。
F_n 像编辫子
先压左绳再压右绳,和先压右再压左——得到的辫子完全不一样。顺序决定一切。
Freedman 的定理说了一件"漂亮得像魔法"的事:
Freedman 的核心代数发现