Yann LeCun押注 10 亿美空:LLM的新架构啥样?NeuroPrior AI LTD
这篇文章我们将讨论另一条同样重要、但理论重心与工程路径明显不同的路线 ——LeCun 所倡导的以世界模型、联合嵌入预测与表征学习为核心的新 AI 架构。
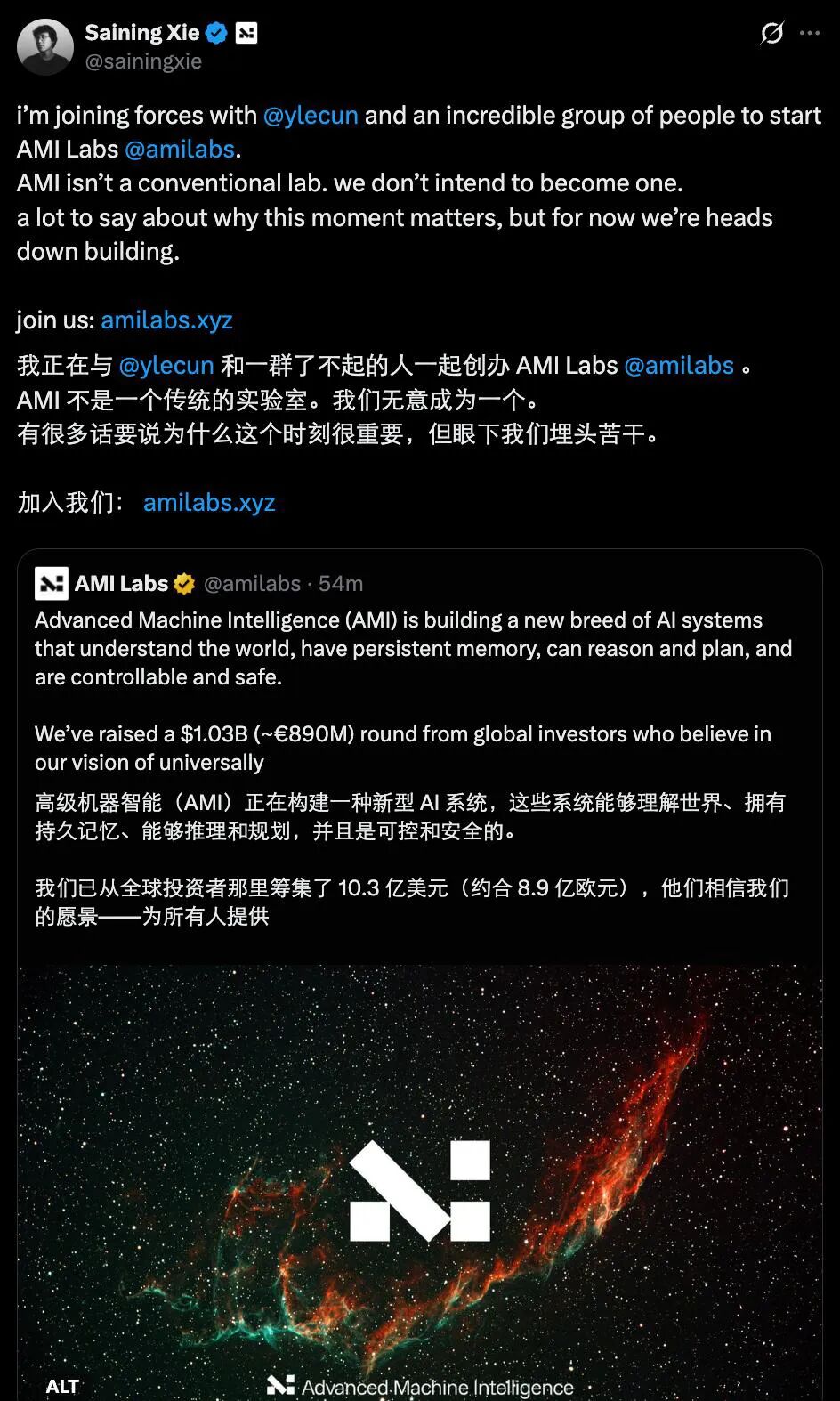
图灵奖得主 Yann LeCun 作为联合创始人和执行主席深度参与、由华人科学家谢赛宁(DiT 共同作者)共同创立的 AMI Labs,已经完成高达 10.3 亿美元的种子轮融资,以 10.3 亿美元级别的融资规模,AMI Labs 几乎是以资本市场罕见的方式,正式在技术路线上向当前的 LLM 范式发起正面挑战。
单纯依赖 “堆算力、堆数据” 的扩展路径,是否真的能够抵达可规划、可理解、可行动的通用智能。
当前的生成式人工智能几乎被 “大语言模型=通用智能” 这一叙事所主导,但以 LeCun 为代表的另一条路线始终在质疑:仅靠在词元层面做自回归预测,是否足以得到真正理解世界、能够长期规划、能够在现实环境中行动的智能体?
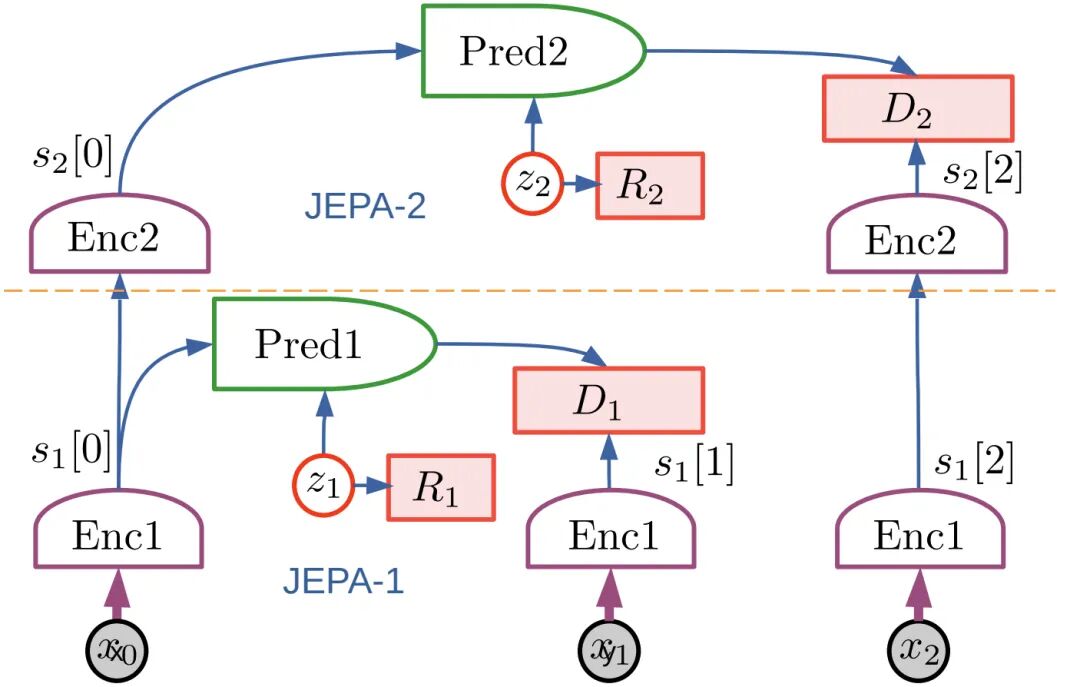
围绕这一问题,一种新的技术构想逐渐成形:不再把 “生成下一像素、下一帧、下一个词” 当作智能的核心,而是让系统在抽象表征空间中学习世界的稳定结构、可预测约束与行动后果,再把语言、规划与控制建立在这一层之上,这一路线当前最具代表性的实现,就是 Joint-Embedding Predictive Architecture(JEPA)及其向视频世界模型发展的分支。
一、为什么大语言模型不够好
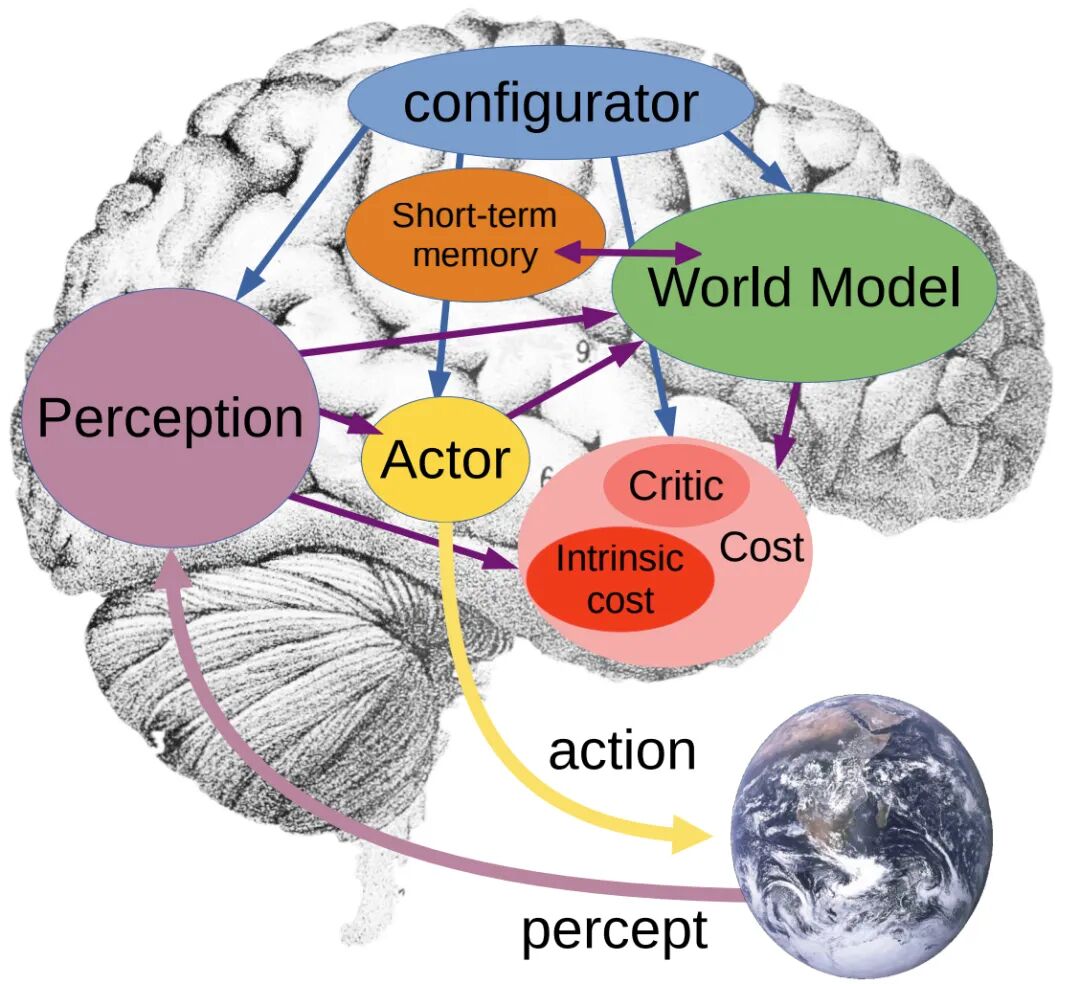
这套新架构的出发点并不是否认大语言模型的工程价值,而是指出:语言预测擅长压缩人类已经写出来的知识,却并不自动等价于对物理世界、因果结构、身体行动与长期目标的真正掌握,根据《A Path Towards Autonomous Machine Intelligence》这篇立场论文,如果机器要像动物或人类那样学习,它至少需要同时具备三类能力:对世界状态形成层级化表征、在多个时间尺度上做预测与规划、以及在不完全可观测、不完全可预测的环境中选择行动,这一定义本身已经把问题从 “生成语言” 转向了 “学习世界模型”。
从这个角度看,当前主流生成式模型有两个根本局限。
第一,它们通常在数据空间直接建模,也就是在像素、声波或词元上逼近条件分布;
第二,它们往往把训练目标与最终智能目标混在一起,然而现实世界不是静态语料库,而是一个高度多模态、部分可观测、充满分叉的动力系统,给定同一时刻的世界状态,下一时刻可能出现多个同样合理的结果,若模型被迫在原始像素上给出一个确定答案,它最容易学到的不是 “未来为什么会这样”,而是 “把多种可能平均起来”,这正是早期视频预测模型经常输出模糊结果的重要原因。
二、核心判断
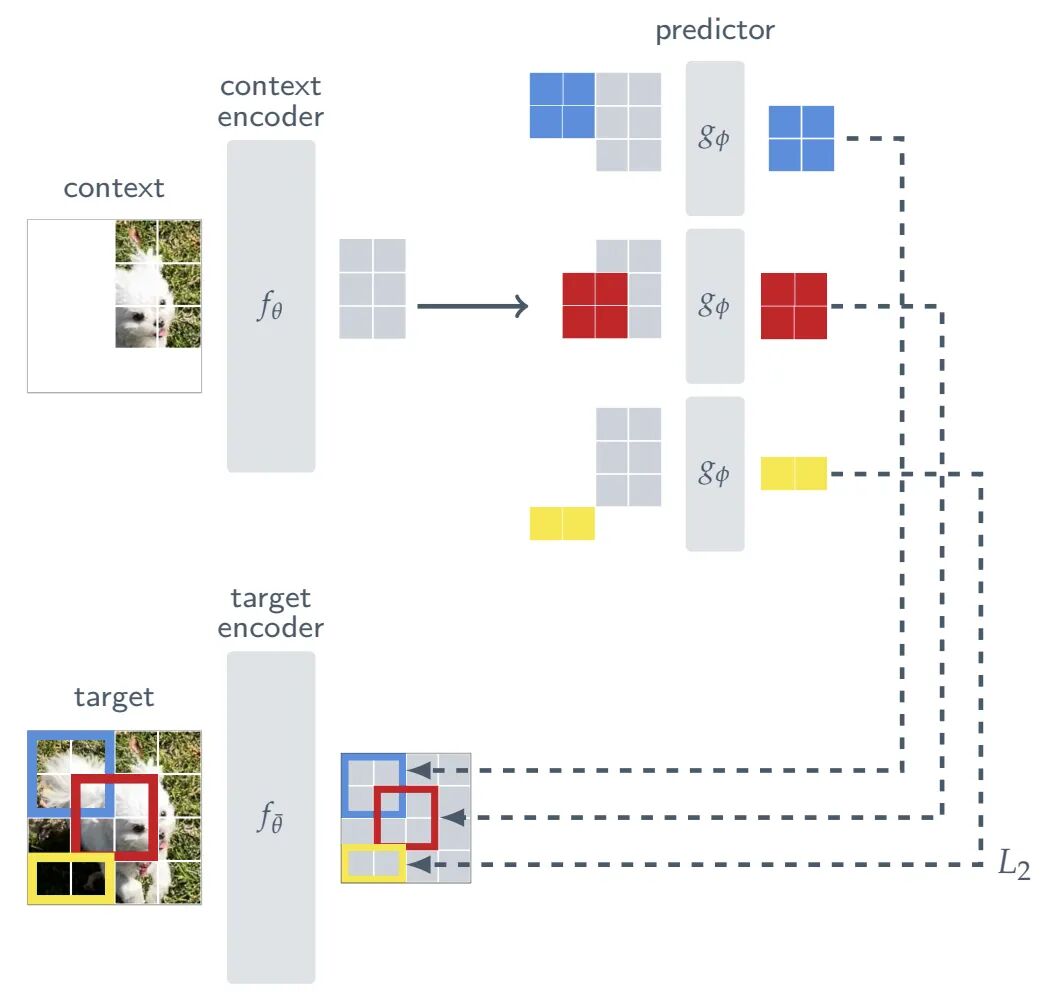
这一路线并不否认生成本身,而是否定 “在最低层数据细节上穷举生成” 应当通向智能的主路线,其核心判断是:智能系统首先应学会预测那些真正可预测、真正与任务相关的抽象结构,而把高频细节、偶然噪声、不可约随机性留给潜变量、下游解码器或专门的生成模块去处理,I-JEPA 论文对此说得非常明确:它是一种 “非生成式(non-generative)” 的自监督方法,其做法不是重建图像像素,而是从图像的一部分上下文去预测同一图像中其他区域的表征;为了让模型学到语义级信息,目标块必须足够大、上下文必须足够分布式,换句话说,模型并不是去记住每一个像素,而是逼自己抓住 “这个区域大致是什么、和周围结构的关系是什么、下一步哪些变化值得预测”。
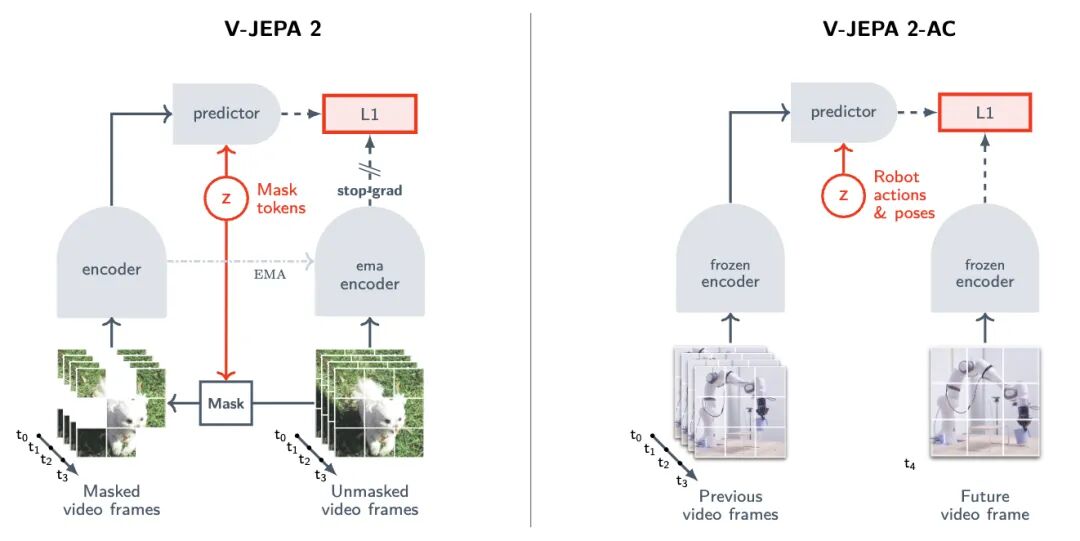
到了视频版本,这一点更被放大,V-JEPA 的官方介绍把它定义为一种 “非生成式模型”,它在抽象表征空间中预测被遮蔽的视频片段,而不是直接补像素;这样做的目的,是让模型把计算资源集中到高层概念信息,而不是耗费在对下游任务不重要的细枝末节上,官方解释里用了一个非常直观的例子:如果视频里出现一棵树,系统真正需要把握的是 “场景中有树、树在怎样运动、树与其他对象的关系如何”,而不是预测每一片叶子的微小抖动。