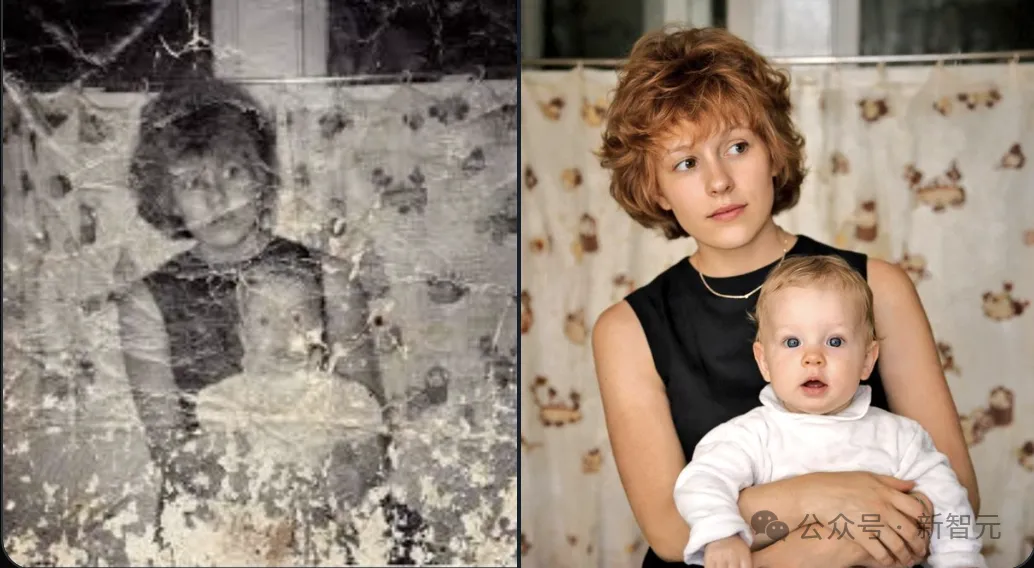奥特曼「红色警戒」5个月后,GPT Image 2屠榜新智元
被Google按了半年头,OpenAI终于祭出一记反杀。GPT Image 2上线12小时,就登顶Arena文生图榜,领先Nano Banana 2达241分。Arena官方称,这是Image Arena文生图排行榜迄今最大的分差。
发布当天,三榜通杀。
GPT Image 2上线12小时,Text-to-Image(文生图)、Single-Image Edit(单图编辑)、Multi-Image Edit(多图编辑)三个分榜全部登顶。
Arena官方原话:「a clean sweep」(全胜)。
文生图主榜,GPT Image 2 1512分,Nano Banana 2 1271分。241分差距,Arena史上最大。
「没有任何模型曾以这种差距统治过Image Arena」,Arena官方表示。
在Image Arena所有盲测对决中,GPT Image 2的胜率是93%:100张图配对盲选,93张人们选了OpenAI那张。
「如果把DALL-E看作洞穴壁画,把Images 1.0视为古代艺术,那么Images 2.0就是文艺复兴」。
OpenAI在发布会开场中这样介绍Images 2.0,奥特曼更是将它称作跨代升级:
这好像一下子从GPT-3跃升到了GPT-5。
OpenAI官方API文档对Images 2.0给出了一个最高级的评价。
但真正的故事,并不在数据里。
被Google压了半年
OpenAI总算扳回一局
时间倒回2025年8月。
Google放出了Nano Banana。这个在Gemini里嵌入的图像生成模型,在C端瞬间引爆。
三个月后的Q3财报会上,Google CEO Sundar Pichai亲口披露了一组数字:Gemini月活,从7月的4.5亿涨到10月的6.5亿。
Google Labs负责人Josh Woodward称,这一增长很大程度上来自Nano Banana带动的图像生成热潮。
11月,Google再发Nano Banana Pro。文本渲染能力惊艳,AI图像第一次能把字写对,OpenAI在C端被反超。
11月18日,Google再补一刀。Gemini 3发布即登顶LM Arena,1501分,首个突破1500的前沿模型。
这一月底,奥特曼对全公司发了一份「红色警戒」(code red)的内部备忘录。
据The Information报道,奥特曼私下告诉员工,Gemini 3可能给OpenAI带来经济逆风。Yahoo Finance后续披露:code red之下,OpenAI暂停了AI Agent等其他产品的研发,资源全部倾斜到ChatGPT。
12月,OpenAI仓促拿出GPT Image 1.5。Arena第一,但C端没能引爆。
2026年2月,Google再补一刀,Nano Banana 2登场,Arena再度领先。
OpenAI又输了一次。
一直到4月21日,GPT Image 2上线,OpenAI这才实现反超,重新扳回一局。
画图AI将被重新定义
GPT Image 2凭什么能领先241分?
核心答案藏在架构层面。
GPT Image 2不是Stable Diffusion那一代的扩散模型。
OpenAI研究负责人Boyuan Chen称这是「revamped from scratch」(从零重构)的「generalist model」(通用模型),OpenAI的内部叫法是「图像版的GPT」。
但Chen在press briefing时拒绝公开承认它具体是扩散还是自回归架构。
外界普遍把它理解为「带推理规划的图像生成系统」:画之前先规划,再下笔。这正是GPT Image 2和上一代图像模型最大的不同。
OpenAI在官方说明里给了它一个新标签:首个具备原生思考能力的图像模型(image model with native thinking capabilities)。
画之前先想、画完自己检查、需要时联网搜索资料、一次能产出8张前后连贯的图。
这不是画笔,是会思考的视觉助理。
Arena榜单分项数据显示:
文字渲染(Text Rendering)单项,GPT Image 2比前代涨了316分;卡通动漫和人像各涨296分;3个产品/3D/写实分类,整体在+247到+277分区间。
文字渲染是2025年11月Nano Banana Pro首次解决的问题,但当时准确率94%。GPT Image 2把它推到了99%。
OpenAI发布会现场演示:让GPT Image 2画一碗米饭,其中只有一粒米上写有模型名字。
具体到能力展示,OpenAI总裁Greg Brockman在自己的X账号上做了示范。
第一个案例,老照片修复。
褪色发黄的家庭老照片,一个提示词,立刻变身高清彩色版。
OpenAI官方API文档里那句「high-fidelity image inputs」(高保真图像输入),说的就是模型对原图细节的保留能力:输入端能精确读取褪色的、破损的、模糊的老照片细节,输出端才能重新渲染出清晰版。
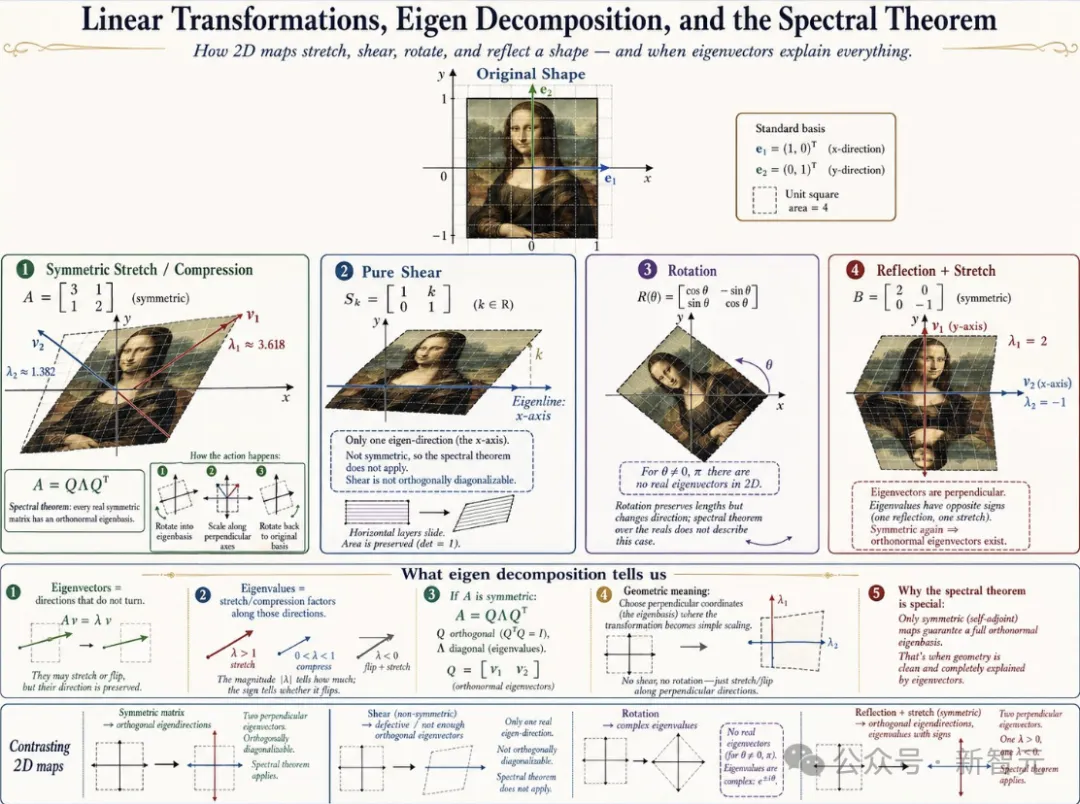
第二个案例中,Brockman转发了用户@doodlestein的一组测试图:用同一个复杂提示词让GPT Image 2画一张数学解释图。
他评价说,即便是复杂提示词,GPT Image 2也能生成风格各异的图。
@doodlestein 测试GPT Image 2用同一个提示词画一张线性代数解释图。模型一口气画出4个完全不同的版本:同样是Mona Lisa+特征向量教学,每个版本的构图、配色、信息密度完全不同。