DeepSeek V4发布,黄仁勋预言成真差评X.PIN
一旦DeepSeek率先在华为平台上发布,对美国而言将是灾难性的结果"。
这里的"我国"指美国
这不是托尼说的,而是英伟达黄仁勋在某个播客上的原话。如今DeepSeek V4的出现,让老黄的预言成真了?
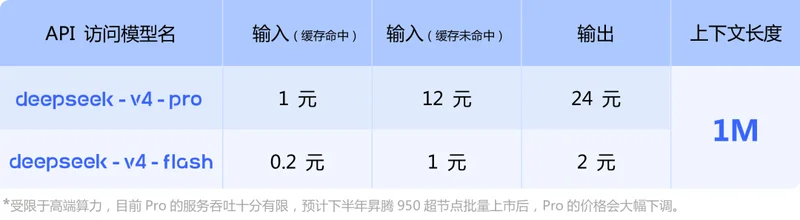
作为大家苦等了一年多的 DeepSeek 大版本迭代,只看性能差友们可能会略有失望。但 DeepSeek V4 是真便宜,价格对比国外模型直接腰斩属于是。
关于模型的具体内容,在白天的文章中已经提到,就不重复了。
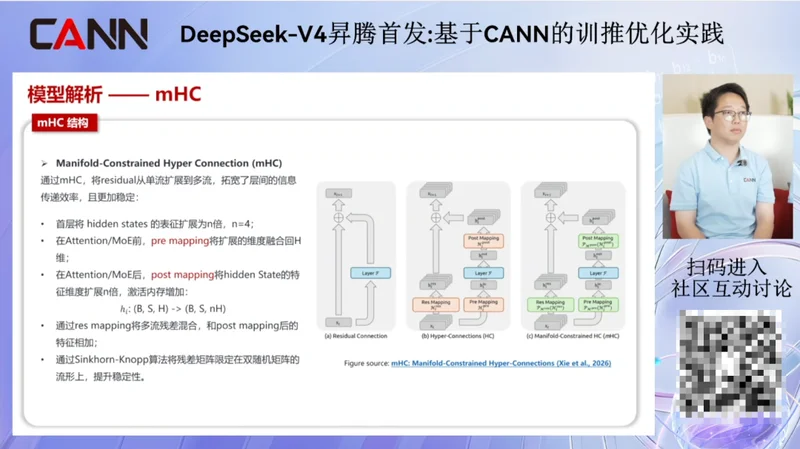
但托尼觉得,随着这次发布,意义更重大的,是深度求索选择在华为昇腾平台上进行首发,结合下午的直播,这意味着 DeepSeek 完成了在国产硬件上的训练适配。
根据网友爆料,这次最先支持国产硬件训练的是 DeepSeek V4 Flash 的后训练过程,基于国产硬件的预训练也有望在今年下半年实现。
换句话说,从今天开始,大家嚷嚷了很久的 AI 全流程使用国产硬件,一下子就实现了!
大家可以把华为的昇腾平台理解为连 AI 芯片都是国产的 AI 计算平台。
假如一年以前有人跟我说,纯国产的AI平台能够支撑一款旗舰模型的全链路研发,托尼我也不敢相信。
但现在它就是成了,这对于国产AI的发展影响是很深远的。
之前老黄没少拿这个事儿游说美国政府让自己卖货,按照老黄的意思,在 AI 军备竞赛中,从底层的电力,冷却,消防这些基础设施,到芯片、服务器等算力设施,再到软件生态和模型的架构演进,这些要素都缺一不可,样样都赢才能赢麻到最后。
AI 是一块“五层蛋糕” - NVIDIA 博客- 英伟达
而咱们的优势,无疑是祖国强大的基建能力,以及充足的人才储备。这些能让我们打造出很多高性价比的模型。
但不得不承认,我们的芯片制程离世界顶端,确实有些差距。好在 AI 需要的芯片,打的是规模战、集群战。所以工程师们想了些办法,来解决制程上的不足。
一来,虽然制程工艺有限制,但芯片可以在不计成本的情况下,通过暴力堆规模,来提升算力。而在配套的内存上,国产也有自研 HBM(高带宽内存),来保证带宽没有瓶颈。
二来,虽然单颗芯片性能有限,但架不住量大管饱啊,把大量的芯片利用起来,组合成一个"计算中心",塞进机柜里,其实就是这两年火热的超节点。
超节点的概念就是英伟达提出的,老黄也做了相应的布局,NVL72 系统把 72 个Blackwell GPU 集成到一个液冷机柜中,达成了约 180 PFLOPs 的 FP16 算力。
而国产芯片们想要堆出近似算力,就需要拿出更多的芯片。所以去年华为昇腾拿出了 384 超节点,通过 12 个机柜,每个机柜 32 张卡,硬是堆出 300 PFLOPs 算力,接近 NVL72 的两倍了。而今年差评更是在 MWC 现场看到了华为最新的 Atlas 950,也就是 8192 卡互联的超节点。
可最严重的一环,其实是生态。
托尼不得不承认,老黄是真有远见的。20年前,英伟达就开始为了 CUDA 生态埋伏笔,甚至牺牲掉了 GeForce 游戏显卡的利润,导致有一段时间差点在和 ATi/AMD 的竞争中死掉。
但英伟达成功熬到了黎明。所以差友们能看到,现在几乎所有 AI 相关的基础模型和优化都基于 CUDA 来运转、后起的 GPU、TPU 等 AI 计算生态都要向它低头。
甚至包括之前 DeepSeek 亲手打造的护城河之一:PTX 底层语言优化,也是为了把NVIDIA GPU 的性能榨干,让模型效率更高,从而让 DeepSeek 模型更有性价比。
也因此,对于国内来说,在制裁的大背景下,不论是华为昇腾的 CANN,还是摩尔线程的 MUSA,目前还要做对 CUDA 的兼容性支持,来让开发者能更快适应自家芯片。
但咱们也不能一直活在别人屋檐下。构建属于自己的软件生态,迫在眉睫。所以最近几年托尼也开始看到像 TileLang 这类由中国主导的生态项目,尝试在不同的方向构建出属于自己的护城河。
就是这些项目对于 CUDA 生态来说,并没有什么伤筋动骨的攻击性。