3B激活参数,干翻GPT-5.4和Opus4.6量子位
龙虾上车,一直有个问题,端侧不智能,云端有延迟。
复杂任务需要推理,推理需要参数,参数多了放不进车机,能放进去的又太弱,这个循环几乎无解。
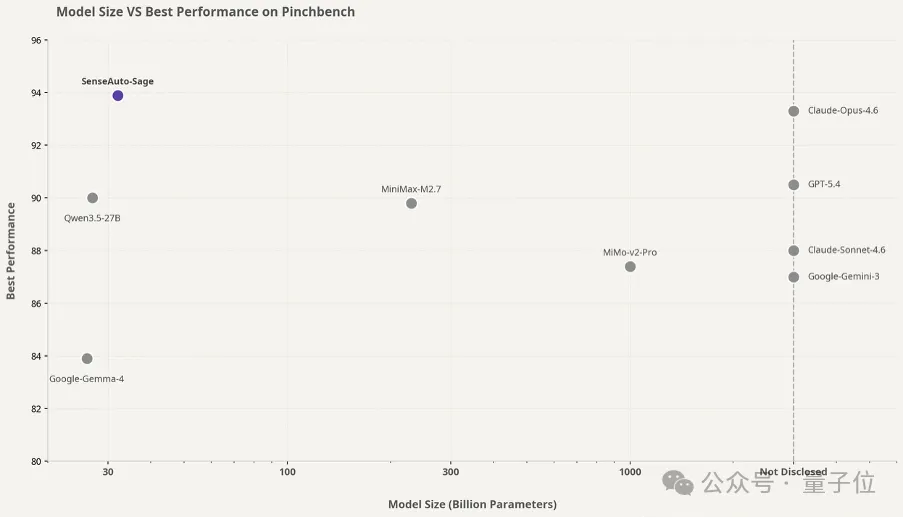
刚刚,商汤绝影发布Sage,一个32B总参数、激活参数只有3B的端侧多模态大模型,突破了这一问题,首次将云端级智能体能力落地端侧。
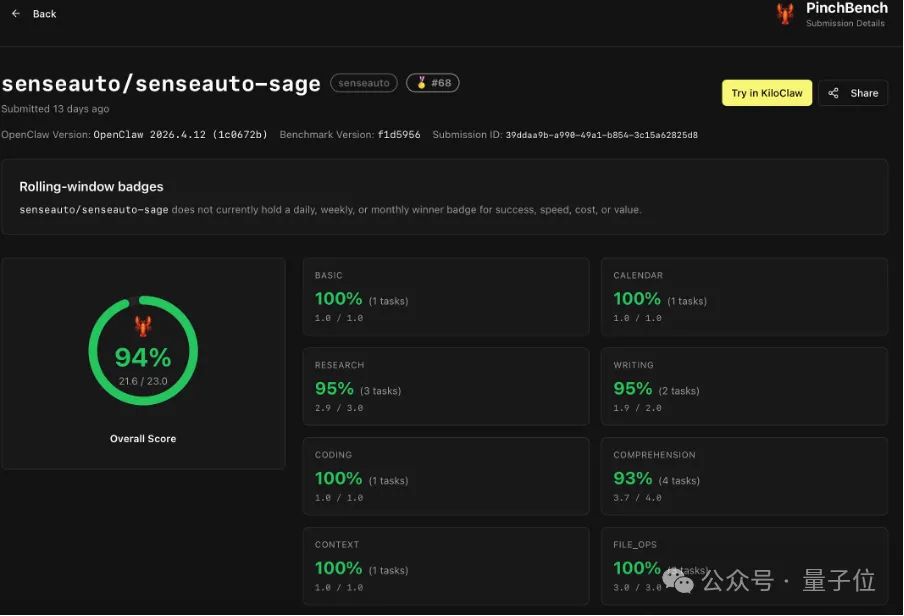
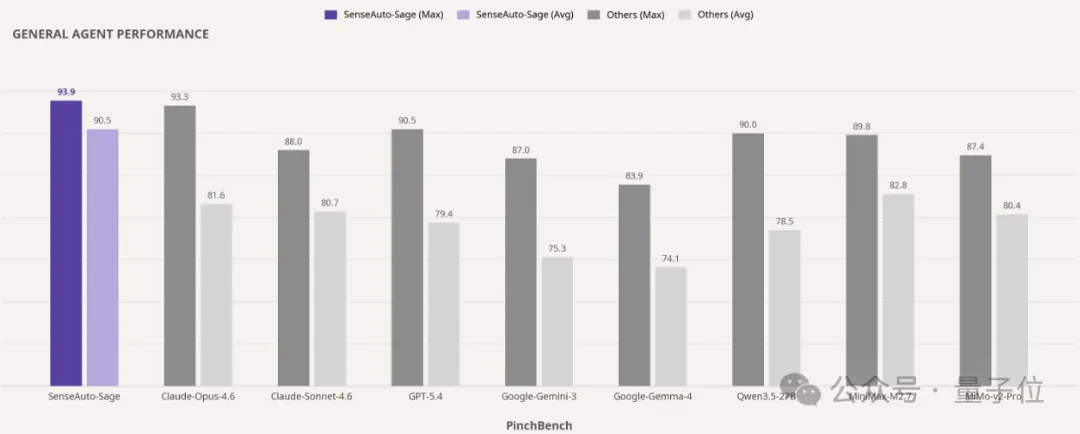
它在公开Agent评测基准PinchBench上拿到了94%的最佳任务完成率,超过Claude Opus4.6(93.3%)、GPT-5.4(90.5%),以及一众参数规模远比它大的云端旗舰模型,并且已在英伟达OrinX端侧平台实现部署。
作为端侧智能体基座,Sage可以接入OpenClaw、Hermes等主流Agent框架,为更多端侧智能体落地提供核心支撑,可覆盖出行、家庭等全场景。
3B激活参数超越大参数量模型
在公开Agent评测基准 PinchBench 中,Sage端侧大模型最佳任务完成率达到94%,超越Claude-Opus-4.6(93.3%)、Claude-Sonnet-4.6(88.0%)、GPT-5.4(90.5%)、Google-Gemini-3(87.0%)、Google-Gemma-4等一众前沿模型。
这里的榜单,PinchBench是龙虾之父PeterSteinberger推荐的公开Agent评测基准。
作为面向真实Agent工作流的评测榜单,PinchBench不依赖固定不变的静态题库,而是随着公开任务库持续扩充和版本迭代不断演进。
其公开任务库覆盖写作、研究、编码、分析、邮件、文件处理、日程管理、记忆与技能调用等典型场景,重点考察模型在工具调用、多步推理和任务闭环执行中的综合能力。
PinchBench要求模型完成真实任务执行,综合衡量成功率、速度与成本,测试周期更长、资源消耗更高,单任务token消耗可达数十万量级。
模型在PinchBench上的表现,更能反映它在复杂真实场景里的综合能力。
北京车展期间,商汤绝影将推出搭载Sage的SageBox,作为整车的模型接入硬件。
两大黑科技,让座舱从“听懂指令”到“说到做到”
Sage端侧大模型在PinchBench跑赢一众国际主流云/端大模型的背后,是商汤绝影围绕Sage后训练阶段自研的两项关键技术:SCOUT和ERL。
以SCOUT和ERL为核心的后训练技术体系,一项让模型「学得又快又省」,一项让模型「做事不出错」,解决了车载大模型从「能听懂指令」进化到「能独立办成一件复杂的事」这个卡了很久的问题。
SCOUT:让大模型学复杂任务,省60%算力
SCOUT(Sub-Scale Collaboration On Unseen Tasks,分级协同学习框架)技术重点解决大模型学习复杂出行场景任务时成本高、试错慢的问题,在复杂任务能力注入过程中可节省约60%的GPU小时消耗。
很多任务涉及空间规划、设备联动、多步决策,直接让大模型自己试错,既慢又烧算力。
SCOUT的思路是把「探路」和「学习」拆开,先派一个轻量小模型在任务里跑一遍,把走得通的路径筛出来,再把这批高质量经验喂给大模型。小模型探路,大模型吸收,训练成本下去了,真实用车场景的技能也掌握得更快。
ERL:让模型自己擦掉错误步骤,任务成功率提升20%
已被机器学习顶级会议ICLR2026收录的ERL(Erasable Reinforcement Learning,可擦除强化学习)技术,聚焦复杂任务链路中的错误识别与纠偏。
用户在真实使用中提出的需求,往往需要模型跨多个步骤完成推理和执行,中间一旦某一步出现偏差,整个任务流程就可能失效。
ERL让模型能主动识别推理过程中的错误步骤,就地擦掉,在原位重新生成,阻止偏差往后扩散。这项技术让Sage在多跳复杂推理基准上较此前SOTA取得显著提升,装车后Sage在复杂任务上的完成率提升了20%。
SCOUT和ERL两项技术前后协同共同推动Sage从语言大模型演进为能够独立完成复杂任务的智能体。
叠加一体化多模态架构与原生训练数据的优势,Sage在能力、成本与量产可行性之间取得了平衡,为打造智能体中枢提供了核心AI支撑。
端侧跑出全球领先能力
如果说PinchBench 94%的任务完成率证明了Sage能办成复杂的事,那么真正决定座舱体验的,是模型在各个专业维度上是不是都够用、够稳、够聪明。
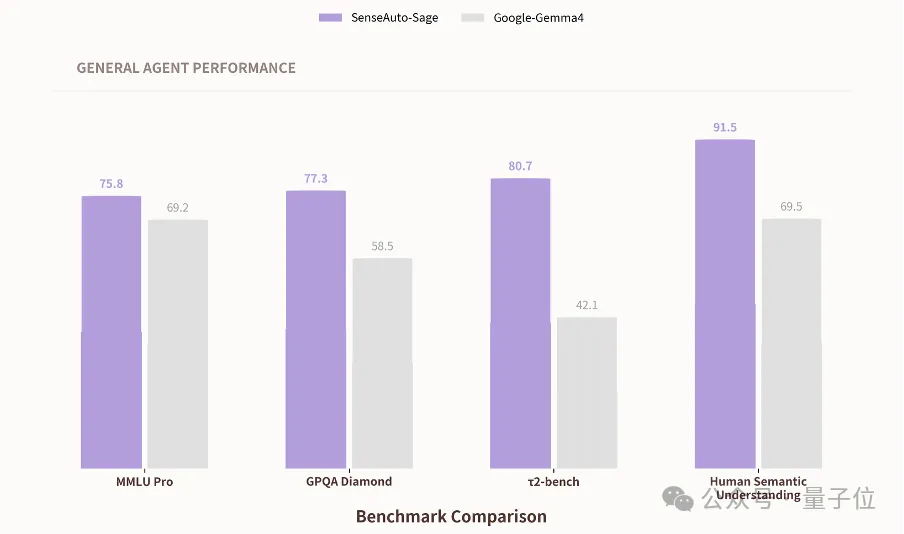
不同能力维度的公开基准上,Sage全面领先本月最新发布的同量级端侧旗舰模型Google-Gemma4,把端侧模型的能力天花板抬到了一个新的水位。
MMLU Pro(跨学科专业知识)测试中,Sage获76分,领先同级端侧模型约10%,证明端侧模型具备云端级通用知识密度;GPQA Diamond(研究生级专业推理)测试中,Sage获得77分,提升33%,凸显复杂推理深度;
Human Semantic Understanding(座舱语义与视觉理解)测试中获91分,提升32%,依托原生数据建立独特优势。
在重点考察任务执行能力的τ2-bench(工具调用与任务闭环)基准上,Sage以80分的成绩相较Gemma4实现38%的提升,接近翻倍领先。
这项基准专门评估模型调用工具、走完多步任务的实战能力,也是区分会聊天的模型与会办事的智能体的关键分水岭。τ2-bench上近一倍的领先,直接印证了Sage作为端侧智能体基座在真实任务执行环节上的绝对优势。
从专业基准到场景体验
这些专业能力落到真实车舱,转化为一组直接影响用户体验的指标:Sage场景推理精度超过90%,长链路工具调用、逻辑规划、环境感知任务成功率分别达92%、89%、94%,复杂指令遵循率提升40%。
在OrinX平台部署下,Sage可实现首字响应(TTFT)约0.5秒、单Token推理延迟(TPOT)低至0.03秒、生成吞吐达到80tk/S,平均任务时长优于主流API模型,为座舱智能体提供稳定、实时、可持续在线的运行能力。
模型可以一次性解析用户的复合指令,自动联动空调、影音、导航等车载系统完成任务闭环;结合传感器对乘员状态与路况的感知,还能主动提供儿童模式、智能路线调整等服务。
Sage不再是“被动唤醒、单次响应”的语音助手,而是一个真正懂场景、会思考、能服务的出行伙伴。