一文看懂大语言模型——斯坦福CS229之小白版孤独大脑
1. 开场白与课程概述
本段总结: 介绍了构建大语言模型的五个核心要素(架构、训练算法、数据、评估、系统)。讲者指出,虽然学术界痴迷于模型架构,但在实际工业界中,数据、评估和系统工程才是决定模型成败的关键。
大家好,今天我们将探讨如何构建大语言模型(LLMs)。简单回顾一下,LLMs 指的是大家最近常听到的那些聊天机器人,比如 OpenAI 的 ChatGPT、Anthropic 的 Claude、Google 的 Gemini 以及 Meta 的 Llama。今天,我们将揭秘它们到底是如何运作的。
在训练 LLM 时,有五个关键组件至关重要:
架构(Architecture):LLM 是神经网络,你需要决定使用什么架构。目前大家都在使用 Transformer 或其变体。
训练损失与算法(Training Loss & Algorithm):你将如何训练这些模型。
数据(Data):这是你用来训练模型的素材。
评估(Evaluation):你如何知道模型是否在朝着目标取得进展。
系统(Systems):在现代硬件上高效运行这些庞大模型的方法。现在的系统层面比以往任何时候都重要。
大多数学术界的研究(包括我职业生涯的大部分时间)都集中在架构和训练算法上,我们总喜欢发明新架构。但老实说,在实践中真正起决定性作用的是另外三项:数据、评估和系统。这也是工业界投入最多精力的地方。因此,今天我不会过多讨论 Transformer 的架构细节,而是重点讲解其他更重要的部分。
本次讲座分为两大部分:预训练(Pre-training)——经典的语言建模阶段,目标是让模型学习整个互联网的知识;以及后训练(Post-training)——ChatGPT 诞生以来的新范式,目标是将这些语言模型转化为真正的人工智能助手。
2. 预训练与自回归语言模型
本段总结: 预训练的核心任务是“自回归语言建模”,即通过概率分布预测序列中的下一个词。模型通过交叉熵损失函数进行训练,这等同于最大化文本的对数似然度。
首先,什么是语言模型?在宏观层面上,语言模型就是一个关于单词或 Token 序列的概率分布模型。具体来说,它建立了一个分布$P(X_1 ... X_L)$。例如,对于句子“老鼠吃了奶酪”,语言模型会评估这句话在人类对话或互联网上出现的概率。如果句子存在语法错误,或者语义不通(比如“奶酪吃了老鼠”),模型赋予它的概率就会非常低。
因为语言模型掌握了概率分布,我们可以从中进行采样,从而生成新的数据,这就是为什么它们被称为生成式模型(Generative Models)。
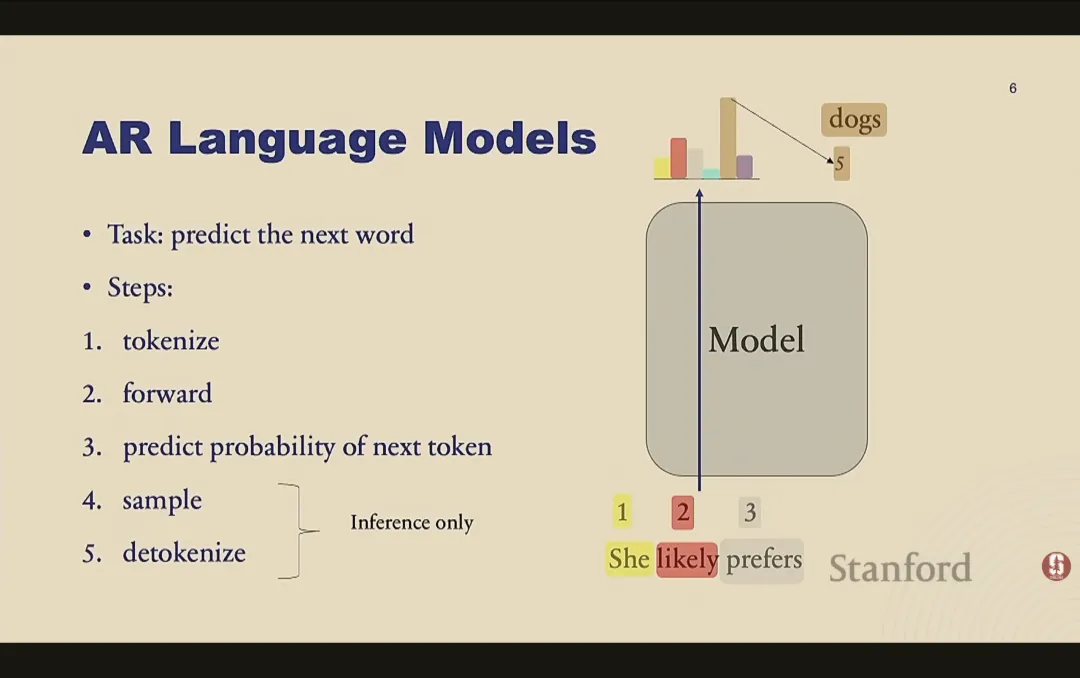
目前大家使用的都是自回归语言模型(Autoregressive Language Models)。它的核心思想是利用概率的链式法则,将整个句子的分布拆解为:第一个词的概率,乘以给定第一个词后第二个词的概率,依此类推。它的任务非常简单:预测下一个词。
在训练时,我们会把序列中的每个词嵌入(Embed)为向量,通过 Transformer 网络获取上下文表征,再通过一个线性层映射到词表大小的维度,最后用 Softmax 输出下一个词的概率分布。我们使用的训练损失是交叉熵损失(Cross-Entropy Loss),这本质上是一个预测下一个 Token 的分类任务。在数学上,最小化交叉熵损失,完全等价于最大化文本的对数似然度(Maximum Likelihood)。
3. 为什么需要分词器(Tokenizer)?
本段总结: 详细解释了分词器存在的必要性,以及字节对编码(BPE)的工作原理。分词器解决了词汇表过大和拼写错误的问题,但也带来了诸如数学计算和代码缩进理解等局限性。
很多人往往忽视了分词器(Tokenizer),但它极其重要。我们为什么不直接用“单词”或“字符”作为基本单位呢?
如果用单词:遇到拼写错误的词汇(如 Typo),模型会遇到未登录词问题,且对于泰语等没有明显空格分词的语言很不友好。
如果用字符:虽然通用,但会导致序列极长。要知道,Transformer 的计算复杂度随序列长度呈平方级增长(二次方复杂度),序列太长会导致算力崩溃。
分词器提供了一个折中方案,通常一个 Token 包含 3 到 4 个字母。目前最流行的方法之一是字节对编码(BPE, Byte Pair Encoding)。
BPE 的训练过程如下:首先将大型语料库中的所有内容拆分为单个字符,然后统计相邻字符对的出现频率。找到最常见的字符对(比如“t”和“o”),将它们合并为一个新的 Token(“to”),并赋予唯一的 ID。不断重复这个合并过程,直到达到预设的词表大小。
不过,业界越来越意识到分词器的局限性。比如在处理数学问题时,数字往往被切分成奇怪的 Token,导致模型看待数字的方式与人类完全不同,影响了推理能力。此外,代码中的空格缩进(如 Python 的 4 个空格)过去也经常被分词器错误处理,这是 GPT-4 专门重构代码分词逻辑的原因。理想情况下,未来我们希望能摆脱分词器,直接处理字符或字节。
4. 评估指标:困惑度与学术基准
本段总结: 评估语言模型的传统方法是困惑度(Perplexity),而现在学术界更倾向于使用 MMLU 等客观题基准测试。同时,评测标准的不一致和训练集污染是目前面临的重大挑战。
我们如何评估模型?在开发阶段,最常用的是困惑度(Perplexity)。
困惑度本质上是验证集损失的一种可解释转化。公式是$2$的“平均每个 Token 的损失”次方。它的直观含义是:模型在生成下一个词时,正在几个词之间犹豫不决?如果模型完美预测,困惑度为 1;如果模型完全在瞎猜,困惑度就等于词表大小。在 2017 年到 2023 年间,标准数据集上的困惑度从 70 骤降到了 10 以下,进步惊人。
然而,困惑度在横向对比不同模型时存在问题(比如 Gemini 和 ChatGPT 的词表大小不同,困惑度就无法直接比较)。因此,目前的学术基准测试(如 Helm 或 Hugging Face 闭源排行榜)通常聚合大量的 NLP 任务。
最典型的是MMLU(大规模多任务语言理解),包含了大学物理、医学等多个领域的单选题。评估方式有两种:一是计算模型生成 A、B、C、D 四个选项的对数似然度,看正确选项的概率是否最高;二是直接限制模型输出,看它生成的下一个 Token 是不是正确答案。
评估面临的巨大挑战:
评估方式不一致:不同的 Prompt 或评分脚本会导致结果天差地别。比如 Llama 65B 在不同的测试平台上,准确率能从 48.8% 飙升到 63.7%。
训练集污染(Contamination):你的测试题是否已经被混入训练集了?为了检测污染,研究人员有时会故意打乱测试题的选项顺序,如果模型依然按原顺序生成答案,说明它很可能在训练时背过这道题。
5. 预训练数据:从“脏数据”到高质量语料
本段总结: 揭露了工业界处理预训练数据的艰辛过程。通过爬取 Common Crawl、HTML 文本提取、去重、启发式过滤和模型分类,最终留下高质量的、配比合理的数据集进行训练。
大家常说“用整个互联网的数据训练模型”,这听起来很简单,但互联网其实是一个“垃圾场”。Common Crawl 作为一个主流的开源爬虫项目,包含了大约 2500 亿个网页,数据量高达 1 Petabyte。如果你随机点开一个爬取的网页,里面全是不完整的句子和杂乱的代码。
为了清洗这些数据,需要一个巨大的工程流水线:
HTML 文本提取:去除网页代码,提取纯文本,同时还要处理棘手的数学公式提取和网页头部/底部的模板内容(Boilerplate)。
过滤不良内容:剔除 NSFW(不适宜工作场所)、有害内容和 PII(个人身份信息)。
去重(De-duplication):剔除重复的论坛签名或在全网被复制粘贴了上万次的段落。
启发式过滤(Heuristic Filtering):基于规则删除低质量文本。比如检查 Token 的分布是否异常,单词长度是否诡异,或者网页是不是只有 3 个词。