跑分第一,推理暴跌——Claude Opus 4.7上线新智元
Opus 4.7发布48小时,口碑两极撕裂。官方榜单并列全球第一,逻辑推理公开测试却从94.7%暴跌到41.0%。token消耗涨了35%,旧接口直接报错,用户集体控诉「更贵、更蠢、更爱顶嘴」。Anthropic到底升级了什么,又搞砸了什么?
「4.6根本没法用,4.7的消耗速度像核反应堆一样。」
Opus 4.7发布后,一位Reddit用户在Anthropic官方帖子下的留言。
不是玩梗,是真心话。
一篇「Claude Opus 4.7是严重倒退,不是升级」的Reddit帖子迅速冲上3000赞。
还有人晒出截图,说4.7连strawberry里有几个字母都答不对。
更别说「擅改简历编造学历和姓氏」,回复用户「我懒得做交叉验证」,以及「三问就撞限额」这些网友热门槽点了。
《Pragmatic Engineer》作者Gergely Orosz试用之后,形容这个模型「出人意料地带攻击性」,然后宣布放弃,换回了4.6。
这边骂声还没散,那边一组数据却指向了相反的方向。
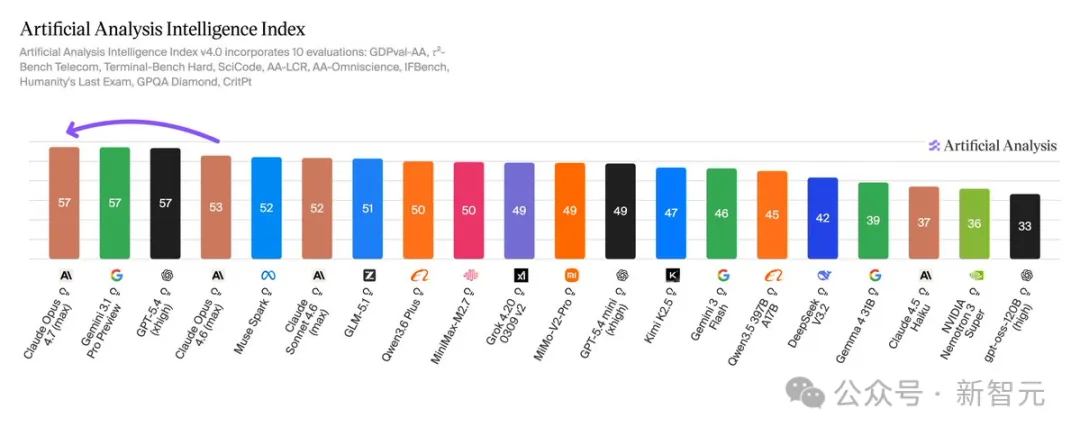
Artificial Analysis给Opus 4.7的Intelligence Index打了57分,和GPT-5.4、Gemini 3.1 Pro并列全球第一。
创业者Jeremy Howard形容它是「第一个真正懂我在工作时到底在做什么的模型」,Y Combinator CEO Garry Tan正在拿它做项目。
还有网友说,Claude Opus 4.7 已实现通用人工智能(AGI)。
同一个模型,有人看到了AGI的影子,有人觉得自己的工作流炸了。
上线两天,Opus 4.7就把AI社区撕裂了。
用户为什么炸了?
拆开看,用户的怒火集中在三个点上,每一条都戳中了重度用户的命门。
第一,代码能力断崖式下滑。大量开发者反馈,从4.6升级到4.7之后,之前能稳定完成的编程任务开始频繁出错。
而且都是日常工作流里的核心操作:代码补全变迟钝,上下文理解出现退化,复杂逻辑链的推理明显变弱。
代码能力是Opus系列的王牌,现在王牌出了问题,反弹自然最猛。
一位Reddit用户说,他用一个已知答案的长重构任务做回归测试,结果模型自信地改挂了3个原本在4.6下能通过的测试,只能回滚。
评论区涌入上百条类似经历。
第二,推理质量的倒退。
不是速度慢了那么简单,是思考深度出现了可感知的退化。以前能一步到位的复杂问题,现在需要反复追问、手动引导。
这个剧本AI行业并不陌生。去年GPT-4 Turbo闹出的「降智」风波几乎一模一样:跑分提升了,体验却下来了。
第三,花更多钱,体验更差。
Opus本身就是Anthropic最贵的模型。
重度用户每月的API账单不是小数目。花了更多的钱、升了更新的版本、得到的却是更差的体验,愤怒就不只停在技术层面。
benchmark更强了
但用户不买账
面对反弹潮,Anthropic的回应速度不算慢。
Anthropic在官方迁移指南中指出,Opus 4.7 相比4.6存在若干行为变化,同时也强调,Opus 4.7仍是其当前综合能力最强的通用可用模型,在长周期智能体任务、知识型工作、视觉任务和记忆任务方面表现尤为出色。
Artificial Analysis的多维评测结果也摆在那里,Opus 4.7在数学推理、多语言理解、长上下文处理,多个维度的得分创下新高。
Artificial Analysis评测显示,Opus 4.7(max)以57分并列榜首,与Gemini 3.1 Pro Preview、GPT-5.4并列。
GitHub上的NYT Connections Extended基准测试也给出了顶级排名。
Anthropic的逻辑并不难理解:大模型迭代必然涉及能力再分配。有些维度提升了,有些维度就可能出现回退,这是工程上的取舍。
但用户不看这个,只看自己手里的活干不干得动。
Anthropic没有调价,每百万token的单价和Opus 4.6、4.5完全一样。
但官方迁移指南里写道:新分词器(tokenizer)在处理相同文本时,token用量大约可能达到原来的1.0倍到1.35倍。
什么意思?你昨天用4.6跑一段prompt花10美元,今天换4.7跑同一段prompt,可能要花11到13.5美元。