腾讯工程师重构Swap子系统腾讯科技
Linux 内核的 Swap 子系统自诞生以来,数十年间代码复杂度持续累积,逐渐成为内存管理子系统中公认的复杂地带。然而,来自腾讯的内核工程师 Kairui Song 以一系列系统性的重构方案,彻底扭转这一局面。
自2025年 Linux 存储、文件系统、内存管理与BPF峰会上首次亮相以来,腾讯服务器操作系统 TencentOS 内核研发工程师 KairuiSong 主导的Swap现代化工程,历经了多个阶段的演进:swap table 的引入(已合并进 Linux 6.18)从根本上替代了沿用多年的 XArray 结构,带来 5%~20%的性能提升;swap map 的移除(面向 Linux 7.1)进一步统一了 Swap 元数据管理,节省约 30% 的元数据内存开销;而将整个 Swap 子系统重新构建于更为清晰、高效的数据结构之上的宏大目标,正逐步从设想变为现实。
这项持续了18个月的工作在 Linux 内核社区引发了广泛关注。LWN.net 知名作者、Linux 内核文档核心维护者 Jonathan Corbet 专门撰写了连续三篇深度分析文章("Modernizing swapping" 系列),逐篇解析 Kairui 及其协作者(Chris Li 等)所做工作的技术细节与及其深远影响——这在 LWN 的报道传统中,是对一项内核贡献极高规格的认可。
本文对 Corbet 的三篇文章进行了系统翻译与整理,以期将这项重要的内核技术进展完整呈现。
一、引入swap table
内核的 Swap 子系统是一个复杂且常被忽视的庞然大物,但它也是内存管理子系统的关键组成部分,对整个系统的性能有重大影响。在 2025 年的LSF/MM/BPF(Linux 存储、文件系统、内存管理和 BPF)峰会上,Kairui Song 提出了一个简化并优化内核交换代码的方案¹。该工作的第一部分²(由 Chris Li协助)成功进入6.18 版本内核,开启了整个 Swap 子系统现代化的序章。
1.1 虚拟内存与匿名页换出
在虚拟内存系统中,内存不足时必须通过页面回收来应对,在必要时需要将内存内容写入持久化后备存储。对于文件页面来说(也就是 page cache),文件本身即为后备存储。但匿名页(anonymous pages)——也就是用于存放进程的堆、栈及各类数据结构的数据区,天然不存在这样的后备存储。这正是 Swap 子系统存在的意义:当匿名页所占用的物理内存需要被回收时,Swap 子系统为其提供写出目标。换出(swapping out)将不活跃(或访问频率低)的页面推送到持久化存储介质,从而释放内存,腾出空间当前活跃使用的工作负载。
1.2 Swap子系统快速入门
然而完整地描述内核的 Swap 子系统确实会很冗长;其中有着巨量的随着时间逐渐积累起来的复杂问题。以下是 Linux 内核 Swap 子系统在 6.17 版本下的简述。
Swap 子系统支持使用一个或多个 swap 文件,可以是存储设备上的独立分区,也可以是文件系统内的普通文件。内核中,可用的 swap 文件由 struct swap_info_struct³ 描述,通常以简单整数索引来引用(内核中每个swap_info_struct拥有一个独立的 type 作为标识符——其实这也是个历史遗留问题,这里的 type 更应该叫作id或index)。每个 swap 文件内部被划分为页面大小的槽(page-sized slots),所有 Swap 文件上的任意槽位都可以使用 swp_entry_t⁴ 类型来索引到。
这个 longval 被分为两个字段:高六位是 swap 文件的索引号(也就是上文提到的type),其余部分是文件内的槽位编号(在 swap 文件内部的偏移量)。内核提供了一组简单的函数⁵ 用于创建 swap entry 并获取相关信息。
需要注意,上述为架构无关的通用格式。各体系结构还有其架构相关的变体,用于避免与页表项(PTE)格式产生冲突。好奇的读者可参阅x86_64 宏⁶,两种形式之间可以进行转换。在 Swap 子系统内部,统一使用架构无关版本。
1.2.1 换出流程简述
当内存管理子系统决定回收一个匿名页时,它就会选择一个 swap 槽位,将该页内容写入该槽位,然后将对应的 swap entry(以架构相关格式)存入页表项(PTE)。swap entry 存储在PTE中时,其格式是不包含PTE所定义的"present" 位的,因此下次访问该页时将触发缺页异常(page fault)。内核识别到 swap entry 后,分配新的物理页,从 swap 文件读取内容,并相应更新 PTE。
现实中的流程远比上述复杂。例如,将页面写入 swap 文件需要时间,在写完之前该页无法被真正回收。因此,回收决策做出时,该页首先被置入 swap cache(与文件映射页使用的 page cache 高度类似)。页面位于 swap cache,也就意味着已为其分配了一个 swap entry。该页本身仍驻留于内存的这段时间便会与该 swap entry成为绑定关系,用于处理各种同步和反向查询等操作。例如若写入过程中发生缺页异常,该页可被迅速重新激活(reactivated)。内核在等待页面完成回写后,才可以真正将其释放。同时也有类似于ZRAM这样的快速设备,其上的回写极其迅速因此这里的等待操作会更简洁。
1.2.2 address_space 与 XArray
如同内核文件系统需要维护 page cache 中每个页面的状态,swap 子系统在处理分配 swap 槽位和IO以外,也需要追踪 swap cache 中每个页面的状态。在 6.18 之前的内核中,swap 子系统维护了一个名为swapper_spaces⁷ 的结构,复用文件系统常见的address_space⁸ 结构从而维护了Swap地址空间(此处文件的内部偏移和swap 文件的槽位偏移非常接近),从而直接维持了 swap 后备存储与页面之间的映射关系,并提供一组在 RAM 与后备存储间移动页面的操作集。这里复用的好处之一,就是使很多 page cache 相关代码也能直接作用于 swap cache。
因此长期以来,swap cache 与 page cache 共用 XArray 数据结构作为其核心数据结构。XArray可以存储每个槽位的当前状态,每个槽位状态可以是:
空,Xarrayentry为NULL
槽位已分配,且页面仍驻留于 RAM:XArray entry 为指向该页(更准确地说,是包含该页的 folio)的指针
槽位已分配,但页面已释放,数据只存在于Swap文件中。在这种情况下,Xarray entry包含“影子”信息,供内存管理系统用于检测换出后快速错误进入的页面。(有关此机制的概述,请参阅这篇2012 年的文章⁹)
此外,每个swap文件并非只有一个 address_space 结构和XArray¹⁰。相反,swap文件会被划分为 64MB 的块,从而将数据分散到多个 XArray 上,减少Xarray锁竞争提升大型系统的可扩展性。
1.2.3 Swap Cluster
Swap 子系统还引入了另一层管理机制:每个 swap文件内部被划分为若干 swap cluster(由struct swap_cluster_info¹¹描述,通常大小为 2MB)。swap cluster 使 swap 文件的管理具有更好的可扩展性:系统中每个 CPU 维护一个本地cluster,相关 swap entry 可完全在 CPU 本地管理,只有在 cluster 级别的分配或释放时才需跨 CPU 访问。更早时Swap子系统还会给每个CPU分配一个更细粒度的槽位缓存,这一设计已经随着swap cluster的进一步优化和简化而移除。
Swap cluster 减少了对全局 swap map 的扫描,但对特定槽位状态的读写仍需访问对应的 XArray。
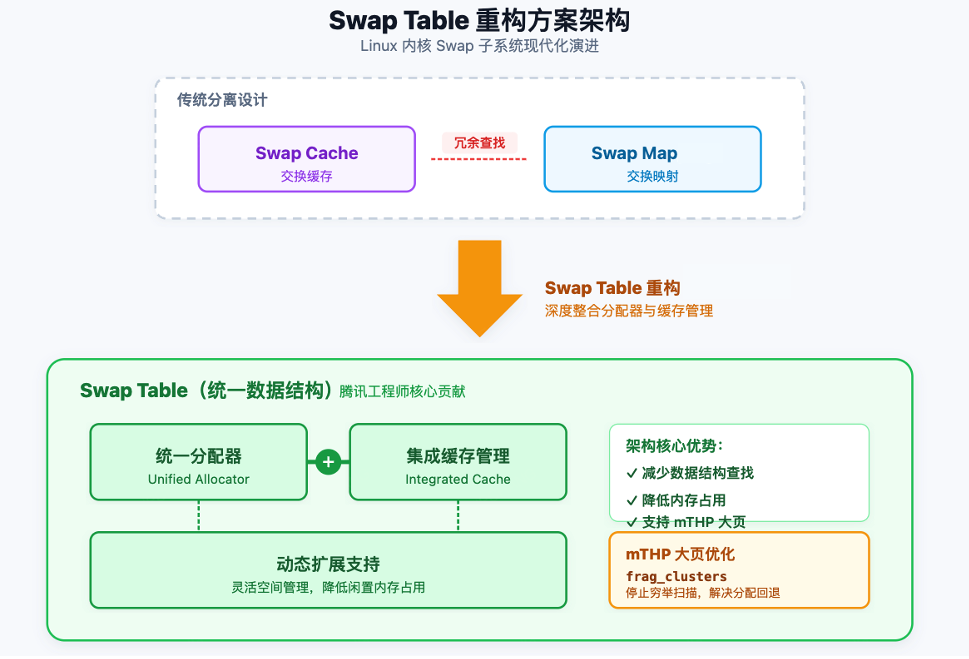
1.3 The Swap Table
有了上述背景,便可深入理解 6.18 的改动。
注意到,Swap 子系统处理 swap entry时就已经能得知其所属的swap cluster。若将所有状态信息(包括Swap cache)随 cluster 一并存储,便可消除 XArray,代之以使用更简单和高性能的C 数组。将整个Swap cache的管理局部化,简化,从而提升可扩展性。
因此,SwapTable第一阶段补丁集增强了 swap_cluster_info 结构;6.17 之后的版本结构¹²新增了一个数组指针:
新的table 数组被设计为在多数体系结构上恰好占用一个物理页,并采用动态分配,只有一个cluster被真正使用时才会分配,以此在 swap 文件未满时可减少 swap 子系统的内存占用。数组中的每个条目均为一个swap table entry,其直接描述 swap文件中某个槽位的状态。Swap 代码进行了大量重构以使用这一全新的核心数据结构。大多数内核内部 API 只需极少甚至无需改动便可兼容。
如此以来,内核此前所采用两套独立的聚簇机制( address_space和swap cluster),现在统一为单一聚簇方案,进一步降低了锁争抢的同时,简化了代码和设计。原本每 64MB 一个的 address_space 结构体数组也已移除,XArray 不再需要,swap地址空间操作可由单一结构体swap_space¹³ 的单一结构提供。
根据 Kairui 的测评,第一阶段工作就可以“在基准测试和工作负载测试中,吞吐量、RPS 或构建时间性能提升高达约 5-20%”。这一性能提升主要源于消除 XArray 查找,以及通过在更小粒度上管理 swap 空间所带来的竞争减少。
二、删除Swap Map
Swap map 是当前持续推进的 swap 改进工作的第二个核心目标。乍一看,当前内核中的 swap map 是非常轻量和简单的数组,存储在 struct swap_info_struct 中:
该数组中,Swap 设备中的每个槽位对应一个字节。每个字节存储的值是指向该槽位的引用数量。不论分配给该槽位的页面是否驻留在 RAM 中,每一个指向该槽位的页表项(PTE)都会贡献一个引用计数。
当然,swap系统错综复杂,情况自然不会那么简单——Swap map里每个entry都预留一些特殊bit。其中对本文最重要的是第 6 位(0x40),称为 SWAP_HAS_CACHE,用于表示某个槽位所对应的页面是否还在内存里。在某些时间窗口内,swap slot 可能已被分配,但尚未有页表项引用它,此时引用计数为零。SWAP_HAS_CACHE bit 用于区分这种状态与 slot 未被分配的状态。
这个标志还被用作位锁(bit lock)同步。内核常常需要并行地多次尝试换入同一页面(或进行操作)。在这种情况下,竞争线程会以SWAP_HAS_CACHE bit作为同步信号,成功设置这一bit的线程才能进行工作。这引发了不少问题:Swap 代码中有大量延迟重试循环(例如¹⁴)或其他work around。
Swap map中还有一些其他特殊值;例如 0x3f:SWAP_MAP_BAD,表示底层存储槽不可用。更特殊的是0x3e:SWAP_MAP_MAX表示引用计数超过了swap map可承载范围。Swap map使用byte作为基础单位,因此只能支持最大为 62的引用计数。这带来了一个问题:当大量任务共享一个匿名页面时,引用计数很容易超过这个值。处理这种情况的方式则更是非常繁琐。
每次 swap slot 的引用计数递增时,都必须检查是否溢出。发生一溢出时,另一个预留标记位0x80(COUNT_CONTINUED)将被置位。Swap map 中的计数将被清零,并分配一个新的物理页,为引用计数提供更高的 8 位。该新页通过关联 page 结构中的 LRU 链表头链接到原swap map页。如果溢出页中的条目再次发生溢出,就继续分配一个页面追加到链表中。
考虑低位仍旧保留在swap map中,大部分引用计数操作不需要走到额外页面里,这样的设计尚可接受。当引用计数较低时(这也是常见情况),这种设计提供了最小的内存开销和不错的性能。
2.1 Swap cache bypass 与 SWAP_HAS_CACHE
正如我们提到的,swap cache的用途之一是持有追踪槽位与页面之间的关系,这在换入换出IO过程中相当重要。如果对一个已换出的 folio 发生了缺页中断,就需要分配一个新 folio 并从 swap 文件中读取其内容。读操作往往需要一定时间,因此该 folio 会被加入 swap cache,直至读取完成才会从中移除,竞争的进程看到该页面便可直接复用和避免忙等待或重复IO。通常,swap子系统还会尝试预读(readahead),预读页面同样缓存于swap cache。