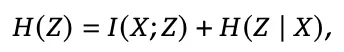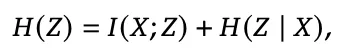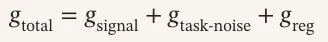李飞飞团队最近在做这个波动智能
最近的 AI 研究圈有一个明显的风向变化。大家不再满足于“让大模型说得对”,而是开始追问“让大模型想得对”。尤其是当 LLM 被塞进多轮交互的Agent 框架里,模型不再是一次性输出答案,而是要像人一样观察、思考、行动、再思考。这个过程一旦进入强化学习(RL)阶段,训练就变成了一场“推理质量的持久战”。
李飞飞团队最近在做的,就是把这场持久战里最隐蔽、最危险的问题挖了出来。
01 为什么RAGEN‑2值得被重写一遍
过去几年,Agent 训练的稳定性几乎完全依赖两个指标:奖励(reward)和熵(entropy)。奖励代表结果好不好,熵代表推理过程是不是多样。大家默认这两个指标稳定,就意味着模型训练健康。
RAGEN‑2 的出现,直接把这套逻辑掀翻了。
研究团队告诉我们:熵其实是一个非常迷惑人的幻觉。模型的推理过程可以在“熵看起来很正常”的情况下,悄悄地、系统性地崩溃。你看到的是模型在认真“思考”,但它实际上已经不再听输入了,只是在重复一套固定模板。
这就是 RAGEN‑2 提出的核心问题:推理崩溃(Reasoning Collapse)。
为了抓住这种隐蔽的崩溃,研究团队提出了两个关键工具。一个是互信息代理(MI Proxy),用来判断模型的推理是否真的依赖输入。另一个是信噪比理论(SNR View),用来解释为什么 RL 会把模型推向“模板化推理”。
这个项目的团队阵容也非常豪华。核心来自 Northwestern University,联合了斯坦福(李飞飞、Yejin Choi、Jiajun Wu)、Microsoft、Oxford、Imperial、UIUC等机构。
项目主页在这里,可以看到完整资料与代码:https://ragen-ai.github.io/v2/
02 推理崩溃是什么?为什么以前没人发现?
推理崩溃这个词听起来有点抽象,但它其实描述的是一种非常直观的现象:模型看起来在认真思考,但它的思考内容和输入毫无关系。
就像你问一个人“今天上海天气怎么样”,对方却每次都回答“让我一步一步想清楚这个任务”。你会觉得他在思考,但其实他根本没在听你说什么。
RAGEN‑2 就是把这种“假思考”现象系统性地揭露出来。
传统指标的盲点:熵只能看到“内部多样性”
为什么以前没人发现推理崩溃?因为大家一直盯着熵。
熵 H(Z|X) 这个指标,只能看到“同一个输入内部,模型的推理是不是多样”。如果模型在同一个输入下生成了很多不同的推理链,熵就会很高。
问题是,熵完全不知道这些推理链是不是真的和输入有关。
这就导致一个非常危险的情况: 模型的熵看起来很健康,但它的推理已经完全脱离输入,进入一种“模板化自言自语”的状态。
研究团队用一句非常关键的公式解释了为什么熵不够:
熵只是右边的第二项。真正衡量“推理是否依赖输入”的,是互信息I(X;Z)。
也就是说,熵高不代表推理好,甚至可能掩盖推理正在崩溃。
模板崩溃的定义:高熵 + 低互信息
RAGEN‑2 把这种现象命名为“模板崩溃(Template Collapse)”。
它的特征非常鲜明,推理链条看起来很丰富 但不同输入之间几乎一模一样 模型像是背了一套“万能推理模板”,无论你问什么,它都先来一句:“Let me think step by step…”或者“I need to solve this task carefully.”
这些句子看起来像推理,但它们完全不依赖输入。
这不是偶然,而是多轮 Agent RL 的系统性失败模式。
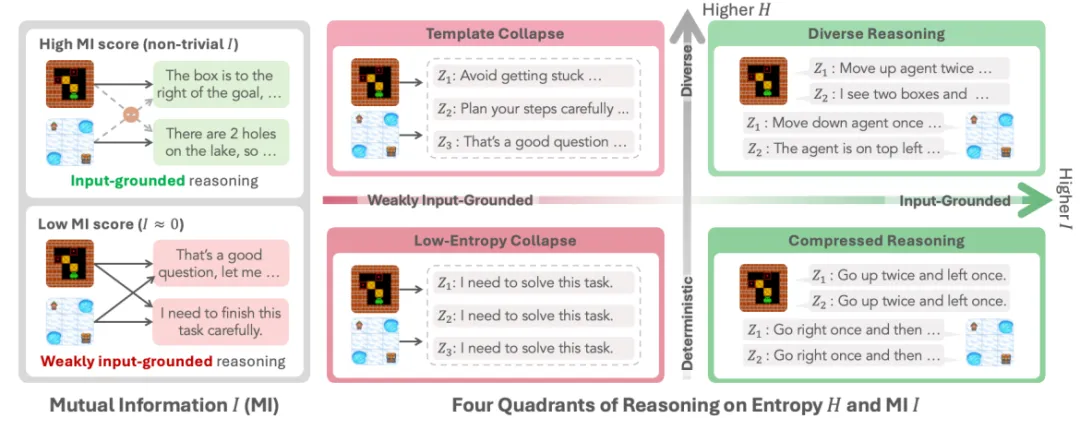
四象限推理状态图:熵 × 互信息
研究团队把推理状态分成四种,特别直观。
当熵高、互信息也高时,模型的推理既多样又依赖输入,这是理想状态。
当熵高、互信息低时,就是模板崩溃。模型看起来在思考,但其实在“背稿子”。
当熵低、互信息高时,模型推理很依赖输入,但过于确定,像是死记硬背。
当熵低、互信息也低时,就是完全退化,模型既不多样也不听输入。
这四种状态里,最危险的就是模板崩溃,因为它最容易被熵“伪装”成健康状态。
图1|左:输入驱动推理适应当前状态;模板推理在不同的输入中产生几乎相同的响应。右:四种推理机制,沿两个轴进行描述:条件熵𝐻(𝑍 | 𝑋) (在输入多样性范围内)和相互信息𝐼(𝑋; 𝑍) (输入依赖性)。
03 RAGEN‑2:互信息视角重构推理质量
如果说 RAGEN‑2 的第一重贡献是“发现问题”,那么第二重贡献就是“重新定义什么叫推理质量”。过去我们太依赖熵了,觉得推理多样就代表模型在认真思考。但 RAGEN‑2 告诉我们,推理多样不等于推理有效,甚至可能是推理正在崩溃的假象。
真正能衡量推理质量的,是互信息 MI。
这一点在研究中被用一个非常经典的信息论公式点破了:
这行公式的意义非常直白。 左边是推理的总熵,右边分成两部分。
H(Z|X) 代表“同一个输入内部的多样性” I(X;Z) 代表“推理是否真的依赖输入”,过去大家只看H(Z|X),也就是“推理是不是多样”。 但真正重要的是 I(X;Z),也就是“推理是不是听输入的”。
这就像你看一个学生写作文,写得花里胡哨不代表他理解题目。 MI 才是判断他有没有读懂题目的关键。
RAGEN‑2 的贡献,就是把 MI 从理论里拉出来,变成一个可以在训练中实时监控的指标。
MI Proxy:如何在训练中实时估计互信息?
互信息本身很难直接算,因为推理链是高维离散序列。 RAGEN‑2 的聪明之处在于,它没有硬算 MI,而是设计了一套“互信息代理指标”,用训练过程中的数据就能估出来。
核心方法叫 In‑Batch Cross‑Scoring。
简单说,就是把每条推理链 Zᵢ,k拿去和所有输入 Xⱼ做一次“匹配度评分”,看看它到底更像是从哪个输入生成的。
如果推理真的依赖输入,那么 Zᵢ,k在自己的输入 Xᵢ上得分最高。 如果推理已经模板化,那么它在所有输入上得分都差不多。
研究团队把这个评分拆成两个量:matched:推理在真实输入上的 log‑prob ;marginal:推理在所有输入混合上的 log‑prob。
这两个量的差值,就是互信息的影子。
基于这个思想,研究团队提出了两个主力指标。
Retrieval‑Accuracy 看推理链能不能“认回自己的输入”。 如果模型崩溃,这个准确率会掉到随机水平。
MI‑ZScore‑EMA 把 matched − marginal 做成连续指标,再加上 z‑score 和 EMA 平滑。 更稳定,也更适合训练监控。
最关键的是,这些指标不需要额外模型,不需要额外推理,训练过程本身就能算出来。
这让 MI 从一个“理论概念”变成了一个“工程可用的监控信号”。
MI与任务性能的强相关性
RAGEN‑2 的实验里有一个非常震撼的发现。
MI 和最终任务成功率的相关性非常高。 熵和任务成功率的相关性不仅低,甚至是负的。
换句话说,熵越高,任务可能越差。 这就像你看到一个人说话越来越流利,但内容越来越离谱。
这说明熵不仅不可靠,还可能误导训练判断。 而 MI 才是那个真正能告诉你“模型有没有在认真思考”的指标。
RAGEN‑2 在这里做的事情,本质上是把“推理质量”从一个模糊概念,变成了一个可量化、可监控、可优化的指标体系。
04 推理崩溃的根因:SNR(信噪比)机制
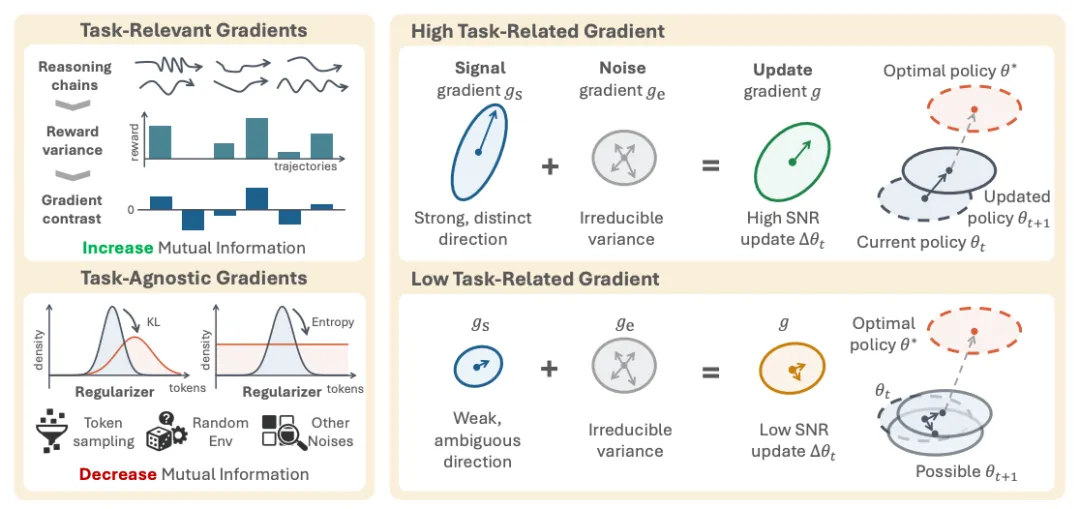
如果说 MI Proxy 是“诊断工具”,那么 SNR 理论就是“病因分析”。 RAGEN‑2 的第三个重大贡献,就是解释了为什么 RL 会让模型推理崩溃。
这部分是研究团队最有洞察力的地方。
图2|RL更新的信噪比(SNR)示意图。左:总梯度分解为任务梯度(随着输入奖励方差的增加而锐化)和正则化梯度。正确的高奖励方差产生强任务梯度和更好的收敛性(高信噪比);低奖励方差使正则化梯度占主导地位,产生不稳定的更新和输入无关的推理(低信噪比)。
关键发现:奖励方差决定任务梯度强度
研究团队的实验发现非常清晰。
当一个输入的奖励方差高时,模型能从不同轨迹里学到有用的信号,任务梯度强,推理自然会依赖输入。
当奖励方差低时,模型几乎学不到什么有用差异,任务梯度弱,正则项(KL + 熵)就会成为主导力量。
这就导致推理被“推向模板化”。
高奖励方差 → 强任务信号 → 推理依赖输入 低奖励方差 → 任务信号弱 → 正则项主导 → 推理模板化。
这就是推理崩溃的根本诱因。
梯度分解:任务信号 vs 任务噪声 vs 正则噪声
研究团队把 RL 的梯度拆成了三部分:
gsignal 是真正有用的任务信号, gtask-noise 是采样噪声, greg 是 KL 和熵正则项。