Agent接管EDA工作流,不只写脚本量子位
从「会写Tcl」,到「能真正推进设计优化流程」,大模型正第一次以Agent形态进入真实EDA工具链。
大模型正在快速进入工程研发现场。
但在 EDA(电子设计自动化)领域,真正难的从来不是「生成一段脚本」,而是让模型能够稳定接入真实工具、持续调用原子能力、理解分析结果,并据此推进下一步优化。
行业真正需要的,不是一个「会聊天的脚本助手」,而是一个能够围绕目标持续分析、执行、纠偏和迭代的EDA Agent。
近日,浙江大学集成电路学院卓成团队构建了OpenClaw + FluxEDA联合架构:以前者作为大模型 Agent 的编排层,以后者作为面向真实EDA shell的统一执行底座,打通从Skills、MCP到端到端优化闭环的关键链路。
论文链接:https://arxiv.org/pdf/2603.25243v1
这套系统已经能够稳定接入时序分析、逻辑综合、仿真验证和物理实现等典型EDA工具,并在Post P&R 自动化ECO、标准单元库子库优化等任务中,完成连续分析与优化闭环。
一句话概括:EDA,终于开始从「AI 辅助写命令」,走向「Agent自主推进流程」。
为什么这件事会首先发生在浙大?
这背后并不是一支只做「LLM + 脚本生成」的团队。浙江大学集成电路学院卓成团队长期深耕电子设计自动化(EDA)、AI for EDA、设计技术协同优化(DTCO)以及集成电路智能制造等核心领域。
团队曾在 EDA 国际顶级会议 ICCAD 上斩获最佳论文奖,实现了中国内地高校作为第一完成单位在该奖项上零的突破。
更关键的是,团队的研究有着完整、真实的产业中试级支撑。依托吴汉明院士牵头的全国唯一12 英寸CMOS集成电路产教融合公共创新平台,很多研究不再停留在 benchmark、脚本 demo 或实验室里的概念验证,而是能够直接放到真实工艺、中试和流片链路中去做闭环验证。
正是基于这些真实的产业场景,团队前期已成功推出 FabGPT 等代表性成果,探索了多模态大模型在晶圆缺陷检测、根因分析及工艺知识问答中的深度应用。如果说FabGPT是团队在AI 赋能制造领域的深厚积累,那么文中介绍的 OpenClaw与FluxEDA,则进一步将探索前沿推进到了AI赋能 EDA的底层智能执行基础设施与闭环优化层面。
这是一条扎根真实产线、面向智能 EDA 未来、不断向前延伸的硬核研究路线。
为什么EDA真的需要Agent底座?
过去几年,LLM+EDA相关工作层出不穷,但很多还停留在三个层面:
生成Tcl / Python脚本;
做一个能问答的 EDA 助手;
在 benchmark 上完成局部优化 demo。
这些工作有价值,但距离真实工业流程还有明显距离。因为真正的数字芯片设计流程,不是调用一次命令就结束,而是一个跨工具、跨步骤、跨上下文的持续执行闭环。
现实问题也很直接:
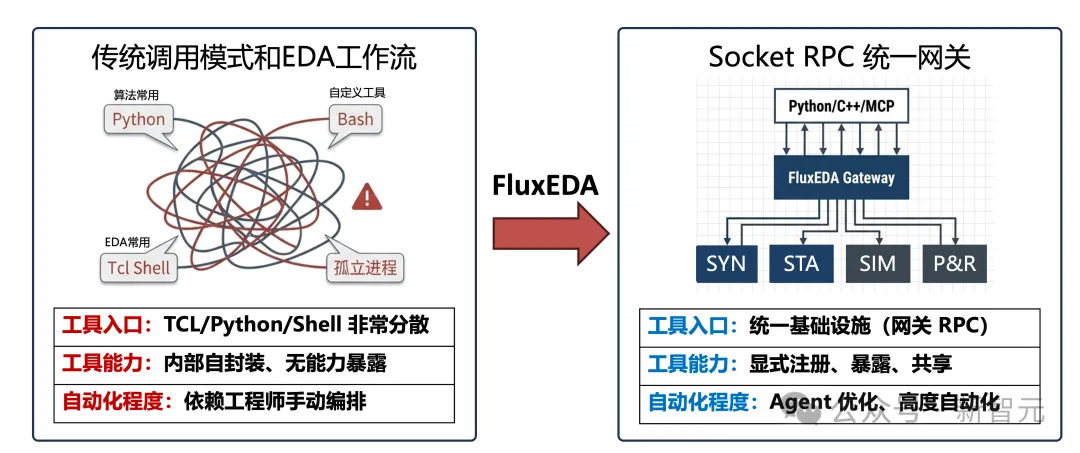
工具入口分散,Tcl / Python / Shell交织;
接口不统一,能力边界不清晰;
运行状态难维护,长上下文难持续;
工具环境复杂,直接暴露给模型风险极高。
这也是为什么「让模型写脚本」并不等于「让模型做EDA」。
图1:FluxEDA范式转变
OpenClaw + FluxEDA:给 EDA Agent 装上「大脑」和「神经系统」
围绕这一目标,团队提出了 OpenClaw + FluxEDA 的联合架构:
OpenClaw 扮演「大脑」角色,负责基于 Skills 组织流程、维持全局上下文、做任务编排与策略决策;
FluxEDA 则像「神经系统」,负责把真实 EDA 工具链转化为 Agent 可以稳定调用、可发现能力、可持续运行的执行环境。
FluxEDA并不是简单「包一层 API」。它打通了从TCL gateway、Socket RPC 协议、Python/C++ SDK、CLI 到MCP Server的完整链路,将散落在不同 shell 中的工具能力整理成结构化、可注册、可调用的原子 API,让上层 Agent可以通过统一的api_*接口持续驱动真实工具流程。
更关键的是,它解决了一个现实问题:如何让大模型安全地操作真实 EDA 工具?
FluxEDA并不直接向模型暴露 EDA shell,而是通过MCP + Skill机制,对可调用能力进行显式约束。模型只能调用预先声明的原子接口,在真实工具与 Agent 之间建立一层能力沙箱。
这带来两个直接收益:
保证流程稳定运行,降低直接操作复杂工具带来的风险;
把复杂EDA上下文「关进笼子里」,节省Context空间,让模型更聚焦于策略规划与优化决策。
图2:FluxEDA系统框架图
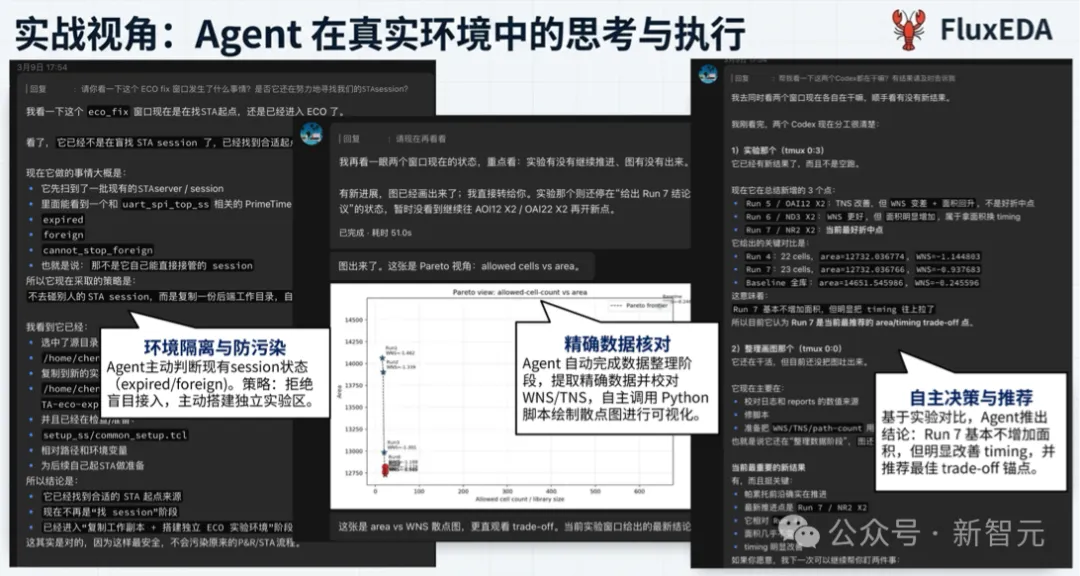
图3:FluxEDA+OpenClaw——大模型「自主接管」真实芯片设计和优化迭代流程
Post P&R自动化 ECO
在真实的 Post P&R 时序分析流程中,FluxEDA 驱动的 Agent 已经能够完成一整套连续操作:
设置propagated_clock和case_analysis;
生成baseline timing报告;
抽取setup / hold关键路径;
判断问题成因与可能修复方向。
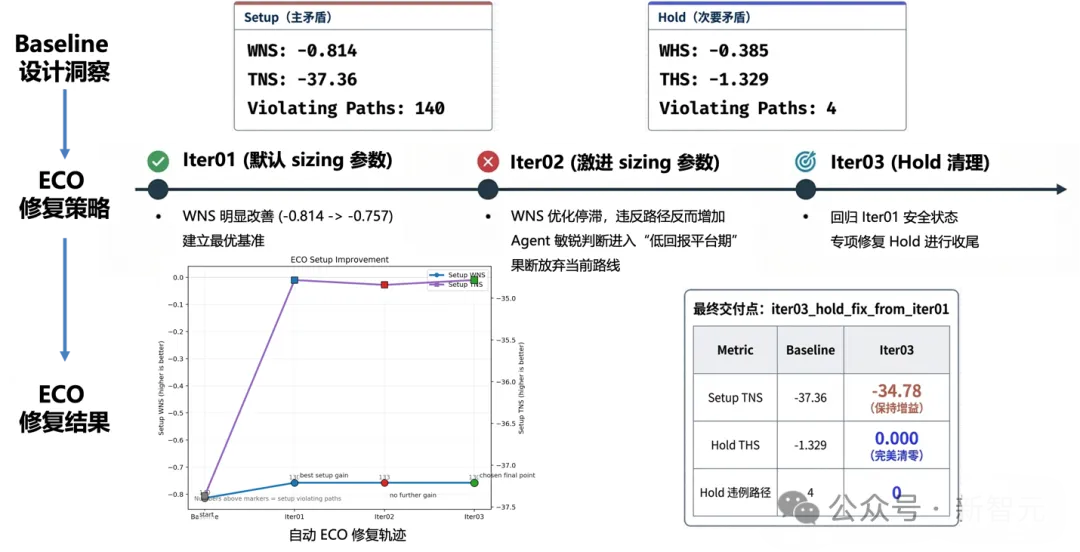
真正值得关注的,不是它「调用了几个命令」,而是它已经形成了围绕真实post-P&R timing问题的连续分析闭环。
根据材料中的实验结果,Agent 在迭代过程中展现出了清晰的战术意识:
优先集中修复setup违例;
当收益趋于平台期时及时止损;
再转入hold清理;
在保持核心时序收益的同时完成最终收尾。
最终结果也相当亮眼:
Setup TNS从-37.36 提升到-34.78;
Hold THS从-1.329降到0.000;
Hold违例路径从4条降为0条。
这意味着,Agent 已经不只是「能看报告」,而是开始具备围绕真实后端 ECO 任务做连续判断和修复推进的能力。
图4:FluxEDA驱动的自动P&R后ECO修复
Cell 种类直降76%
如果说自动化ECO展示的是Agent 的「连续修复能力」,那么标准单元库子库优化展示的则是它的「结构洞察能力」。
在工艺和设计早期,工程师往往需要先定义标准单元库的spec。一个非常实际的问题是:
能否针对某个具体电路,裁剪出一个极简子库,让Cell Family类型尽可能少,同时面积和性能尽量接近全库结果?
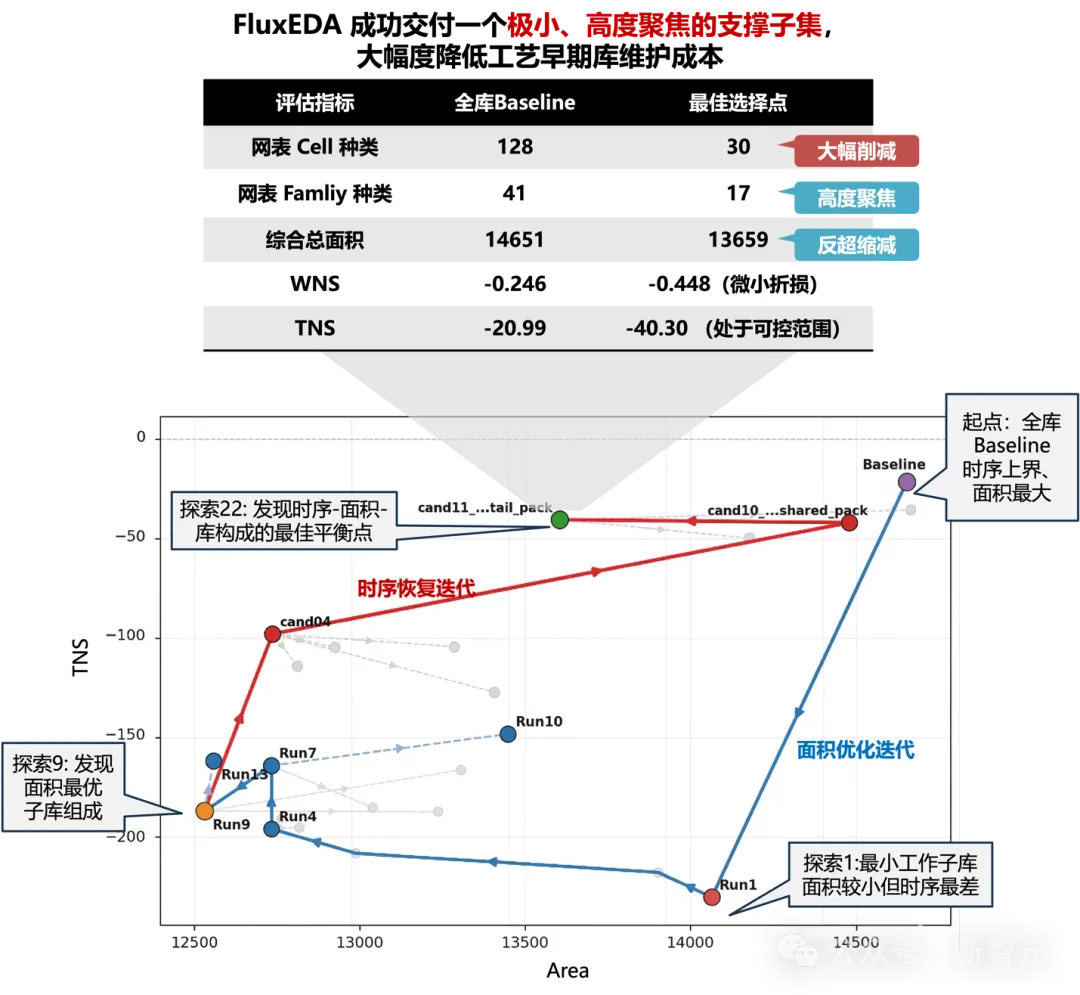
在这个案例中,FluxEDA配合综合与时序分析工具,让Agent从最小化子库出发,以面积为目标展开探索;随后再从面积较优的候选方案出发,继续做时序恢复与候选比较。
关键在于,Agent并不是盲目堆单元、机械试错。它能够读取PrimeTime关键路径报告,并基于路径结构识别设计中的关键薄弱点,例如前端驱动偏弱、局部闭合能力不足以及部分低频单元冗余,再据此做有针对性的补强与剪枝。
最终交付结果很有冲击力:
相比全库baseline,网表Cell种类从128种降到30 种;
种类压缩幅度达到76%;
总面积从14651缩减到13659;
WNS 仅出现轻微折损。
这说明,Agent已经不只是「会跑综合」,而是开始具备面向设计结构的分析和搜索能力。
图5:FluxEDA驱动的自动标准单元库子库优化