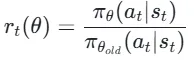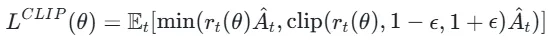强化学习70年小冰的奇思妙想
这是一场持续 70 年的演化,每一次迭代都彻底重构了强化学习(RL)的使命与边界 —— 从最初的「试错学习数学化」,到如今驱动大模型对齐、自主演化的核心引擎,RL 的进化史,就是一部智能体「从环境中学习、从反馈中进化、从个体走向群体」的史诗。
第一幕 萌芽与奠基(1950s-1980s):试错本能,能否被严谨数学化?
行为主义心理学早已证明「试错是生物学习的本能」,但在早期AI界,主流观点坚信「智能=精确的逻辑推理与监督学习」,而无明确标签的试错学习是「不严谨的野路子」,既无法被形式化,更难被实现工程落地。
1. 生物学源头与硬件初探
1898年,桑代克通过「猫的迷笼实验」提出效果律:带来利好结果的行为会被强化,带来负面结果的行为会被弱化——这是强化学习最本源的思想雏形。1948年维纳的《控制论》为「反馈闭环」提供了理论根基;1954年,明斯基造出了史上第一个人工强化学习系统SNARC,用硬件实现了老鼠走迷宫的试错学习,证明了试错机制可以在人工系统中复现。
2. 数学框架的奠基
1957年,理查德·贝尔曼提出马尔可夫决策过程(MDP)与贝尔曼方程,第一次为「序贯决策问题」建立了严谨的数学框架:把「智能体的试错学习」,转化为「最大化长期累积奖励的最优策略求解」。这一突破让RL彻底脱离了心理学的经验范畴,拥有了坚实的数学根基。但致命局限随之而来:基于贝尔曼方程的动态规划,需要完全已知的环境模型,且计算复杂度随状态空间指数级增长,维度灾难直接锁死了它的实际应用。
3. 无模型RL的理论闭环
1959年,IBM的阿瑟·塞缪尔在跳棋程序中首次提出「强化学习」一词,用时序差分(TD)的雏形实现了自学习,击败了人类跳棋冠军,第一次证明了RL的工程可行性。1980年代,被称为「RL之父」的理查德·萨顿与安德鲁·巴托,系统性构建了时序差分(TD)学习框架,完美融合了蒙特卡洛方法的「无模型」与动态规划的「自举」优势,解决了「无需完整轨迹、无需已知环境」的核心难题。1989年,克里斯·沃特金斯提出Q-Learning算法,严格证明了离策略场景下的收敛性,为无模型RL画上了理论闭环,现代强化学习的学科框架正式成型。
这个阶段的RL,是「理论上的天才,工程上的孤儿」。萨顿与巴托在学界的边缘化坚守,终于让RL从心理学的附属品、最优控制的分支,成长为独立的学科。但表格型RL只能处理离散、小规模的状态空间,面对图像、语音等高维真实输入完全无能为力。函数近似与收敛性的核心矛盾,将RL拖入了长达十余年的寒冬。
第二幕 寒冬与坚守(1990s-2012):函数近似,为何让RL从收敛走向发散?
表格型RL的收敛性理论完美无缺,但真实世界的状态是无限连续的,必须用函数近似(如神经网络)拟合价值函数。然而RL的三大核心要素「函数近似+自举+离策略」组合在一起,会直接打破算法的收敛性保证,甚至导致彻底发散。RL陷入了「要么理论完美但毫无用处,要么能用但理论崩塌」的两难绝境。
1. 昙花一现的巅峰
1992年,杰拉尔德·特萨罗的TD-Gammon横空出世,将TD学习与单隐层神经网络结合,在西洋双陆棋上击败了人类世界冠军,这是RL与神经网络的第一次成功结合,学界一度以为RL的春天已经到来。但很快,现实泼了冷水:这个成功完全无法复现——在围棋、机器人控制等更复杂的场景中,神经网络+RL要么训练完全崩溃,要么效果远不如传统表格算法,甚至连最基础的收敛都无法保证。
2. 寒冬里的理论补全
主流AI界对RL的热情迅速冷却,顶级会议上RL论文占比不足5%,大量研究者转行。但坚守者们没有放弃,他们从根源上重构RL的优化逻辑:2000年前后,萨顿等人证明了策略梯度定理,将RL的优化目标从「拟合价值函数」转向「直接优化策略本身」,从根源上避开了价值函数近似的误差累积,Actor-Critic框架正式成型;2002-2005年,自然梯度、LSTD、最小二乘策略迭代等方法相继提出,针对性解决策略梯度方差大、步长难以选择的核心痛点,为后续深度强化学习的爆发埋下了理论伏笔。
这个阶段的RL,像个身怀绝世理论却无处施展的天才。算力的局限让深层神经网络无法落地,浅层函数近似无法处理高维输入,人工特征又彻底限制了RL的通用性。RL在寒冬中等待契机—而2012年AlexNet在ImageNet上的封神,深度学习的全面爆发,终于为RL带来了破局的曙光。
第三幕 深度革命爆发(2013-2019):范式重构——RL+DL,能不能实现端到端的感知-决策闭环?
深度学习解决了「高维原始输入的特征提取」难题,RL解决了「序贯决策的长期优化」问题,但两者的结合天生就是不稳定的:深度学习的非凸优化,叠加RL的自举与离策略特性,会导致价值函数严重过拟合、Q值爆炸、训练彻底崩溃;同时,策略梯度算法存在高方差、低稳定性、步长难调三大顽疾,连续动作空间的探索效率极低。TD-Gammon的失败近在眼前,所有人都在问:深度与RL的结合,到底能不能走通?如何解决训练稳定性、样本效率、动作空间适配三大核心难题?
破局与封神之路:核心算法深度拆解
这一阶段是深度强化学习(DRL)的黄金六年,所有经典算法均围绕「稳定训练、降低方差、提升效率、适配场景」展开,每一种算法都是对上一代缺陷的针对性修正,形成了清晰的技术演进链:DQN(价值-based,离散动作)→ TRPO/PPO(策略-based,稳定优化)→ DDPG/TD3/SAC(Actor-Critic,连续动作)→ AlphaGo/AlphaZero(博弈融合)。
1. 开山之作:深度Q网络(DQN,2013/2015)——解决高维输入+训练崩溃
核心痛点:传统Q-Learning用表格存储Q值,无法处理图像等高维状态;直接用神经网络拟合Q值,会出现时序相关性(样本非独立同分布)、目标移动(自举导致优化目标不停波动)两大致命问题,训练直接发散。
经验回放池(Experience Replay):把智能体与环境交互的(s,a,r,s')四元组存入缓存池,训练时随机批量采样,彻底打破样本时序相关性,同时实现样本复用,大幅提升样本效率;
目标网络(Target Network):搭建两个结构一致、参数不同的CNN网络—在线网络(实时更新)负责选动作,目标网络(每N步同步在线网络参数)负责计算Q目标值,固定优化目标,避免自举带来的误差循环累积;
网络架构:采用AlexNet同款卷积层,直接输入Atari游戏原始像素(84×84灰度图),输出所有离散动作的Q值,实现端到端感知-决策。
成果与局限:
49款Atari游戏全面超越人类专业玩家,标志DRL正式诞生;但仅适用于离散动作空间,连续动作(如机器人关节控制)无法枚举;存在Q值过估计、探索效率低、易陷入局部最优等问题。
2. 策略优化革命:TRPO(2015)——解决策略梯度步长失控、策略崩溃
传统策略梯度梯度方差极大,训练震荡剧烈;一旦策略更新步长过大,会导致策略性能断崖式下跌,甚至彻底崩溃,且无理论保证单调性提升。
核心创新:提出信任区域策略优化(TRPO, trust region policy optimization),用KL散度约束限制新旧策略的差异,保证策略更新是「小步稳健迭代」,从数学上证明策略性能单调非递减。
核心思想:在新旧策略KL散度不超过阈值的约束下,最大化策略期望奖励,避免激进更新毁掉模型;
技术难点:采用共轭梯度法+线搜索求解带约束的优化问题,引入重要性采样修正离策略偏差;
优势:训练稳定性极强,适用于高维连续动作空间,理论收敛性完备;
缺陷:计算复杂度极高(二阶优化),显存占用大,训练速度慢,难以工程化落地。
3. 工业级基线:PPO(2017)——TRPO的轻量化平替,兼顾稳定与效率
核心痛点:TRPO效果好但太笨重,无法适配大规模训练和工程场景,急需一款「简单、稳定、高效」的通用策略算法。
颠覆性简化:抛弃TRPO复杂的KL约束,PPO(近端策略优化,proximal policy optimization)改用裁剪代理目标函数,用一阶优化实现近似信任区域效果,代码极简、训练超快、兼容性拉满,至今仍是DRL工业界标配。
裁剪比率约束:定义重要性采样比率,
将其限制在[1-ε,1+ε]区间(ε通常取0.2),防止策略更新过猛;
代理损失函数:
其中At是优势函数(衡量动作优于平均策略的程度);
兼容多场景:支持在线/离线训练、离散/连续动作、多核并行采样,适配大模型、机器人、游戏等几乎所有DRL场景。
优势对比:相比TRPO,训练速度提升10-100倍,显存占用大幅降低,效果接近甚至超越TRPO;解决了策略梯度高方差、不稳定的核心痛点。
4. 连续动作王者:DDPG→TD3→SAC——RL从虚拟走向现实
这三个算法是深度强化学习针对连续动作空间的完整演进闭环,全称与核心定位如下,它们的诞生彻底解决了「RL 如何走进真实物理世界」的核心难题 —— 机器人控制、自动驾驶、工业优化等场景的动作输出都是连续值(如机械臂的关节角度、油门刹车的力度),而此前的 DQN 只能处理离散动作,传统策略梯度在连续空间采样效率极低,这条演进链正是 RL 从虚拟游戏走向真实世界的核心跳板。
(1)DDPG(2016):深度确定性策略梯度,「极致功利主义者」
全称 Deep Deterministic Policy Gradient,DDPG 的理论根基是 2014 年 DeepMind 团队提出的DPG(确定性策略梯度定理),DPG 定理第一次严格证明:确定性策略的梯度,等于 Q 函数对动作的梯度的期望,无需对动作空间做积分,无需大量采样,计算量直接下降几个数量级。
DDPG 采用经典的 Actor-Critic 双网络架构,两套网络均配套「在线网络 + 目标网络」:
Actor 网络:确定性策略网络,输入状态 s,直接输出唯一的确定性动作 a=μ(s),目标是最大化 Q 值;
Critic 网络:价值网络,输入状态 s 和动作 a,输出 Q 值 Q (s,a),目标是最小化 TD 误差,拟合真实的动作价值;
双目标网络:Actor 和 Critic 各有一个冻结的目标网络,每隔固定步数同步在线网络的参数,固定优化目标,避免自举带来的误差循环;
经验回放池:与 DQN 一致,打破样本时序相关性,实现样本复用。
DDPG 解决了连续动作空间的从 0 到 1,但天生带有三大绝症,导致它的训练被学界戏称为「炼丹术」——10 次训练 9 次崩,收敛全靠运气:
Q 值严重过估计:Critic 网络会持续高估动作的价值,一旦 Q 值失真,Actor 网络就会学习到错误的最优动作,策略直接跑偏;