陶哲轩谈“黎曼猜想如被证伪”51CTO技术栈
AI几乎让科学范式颠倒了!
近日,31岁获得数学界最高荣誉——菲尔兹奖、最早深度使用 AI辅助研究且爱写学术博客的陶哲轩,与Dwarkesh Patel进行了一场深度对谈。
在这场对谈中,针对AI在科学与数学领域的应用,陶哲轩提出了以下几个重磅且具有前瞻性的观点:
第一,历史上科学研究的传统范式是科学家先产生灵光一闪的“天才创意”或假设,然后收集少量数据进行验证。而当下新的科学范式是先收集海量大数据,然后利用 AI 从中提取模式,再推导出以前不存在的规律和假设。
第二,AI 已经将提出科学假设和理论的成本降低到几乎为零,现在的瓶颈不再是想不出理论,而是如何从 AI 每天生成的成千上万个理论中,识别、验证并评估出真正能推动学科发展的优质想法。
第三,我们正处于一场认知革命之中,即意识到人类智能可能并非宇宙的中心,而是存在着多种截然不同、优缺点互补的智能形式。人类需要重新评估哪些任务需要人类智能,而哪些可以外包给 AI。
第四,通过 Lean 等形式化证明语言,AI 生成的数学证明不再是抽象的逻辑流,而是可以被观察和拆解研究的“实物” 。他预见未来可能会出现一种新的数学家,对 AI 生成的巨大、凌乱的证明,他们将尝试删除部分代码来观察其是否崩溃,从而反向推导出其中的核心数学洞察和关键引理。
第五,人类数学家擅长从部分进展中累积经验,通过持续的对话和适应性改进来攻克极其深刻的难题,而目前的 AI 仍缺乏这种基于阶段性进展的“累积能力”。但AI能以极大的规模同时攻击成百上千个问题,消除自有水平线下的所有障碍。
第六,目前对解决最核心的数学难题,AI的加速作用尚不明显。但AI极大地加速了论文中图表生成、代码编写、排版和深度文献搜索等辅助性任务,使得论文变得更丰富、更宽广。
以下为对谈全部内容:
科学范式的 “倒置”:从 “数据验证理论” 变为 “数据产生理论”
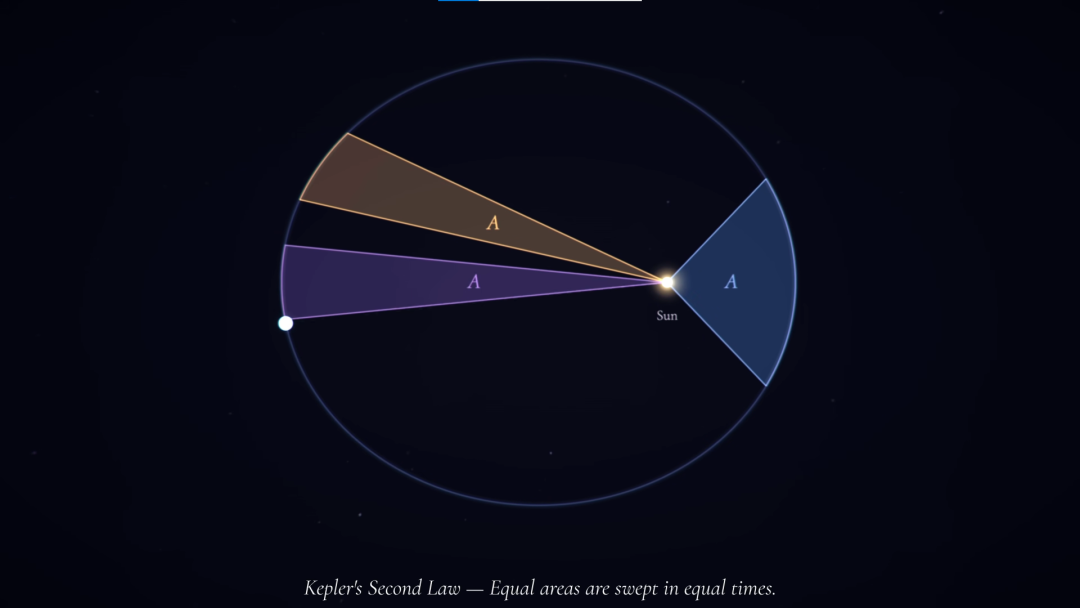
Dwarkesh:今天,我正与无需多言的陶哲轩(Terence Tao)交谈。Terence,我想请你先复述一下开普勒如何发现行星运动定律的故事,因为我认为这将是讨论数学 AI 的绝佳切入点。
陶哲轩:我一直对天文学有着业余的兴趣,也非常喜欢关于早期天文学家如何推导出宇宙本质的故事。开普勒是在哥白尼工作的基础上进行的,而哥白尼本人又是建立在阿里斯塔克斯的工作之上。哥白尼非常著名地提出了日心说模型,即太阳位于太阳系的中心,其他行星绕着太阳转,而不是行星和太阳绕着地球转。哥白尼认为行星的轨道是完美的圆。他的理论符合希腊人、阿拉伯人和印度人几个世纪以来积累的观测结果。
开普勒在学习这些理论时,观察到哥白尼预测的轨道尺寸比例似乎具有某种几何意义。他开始提出,如果你把地球的轨道嵌套在一个立方体里,那么包裹这个立方体的外层球体几乎完美地匹配了火星的轨道,依此类推。当时已知有六颗行星,它们之间有五个间隙,而恰好有五种完美的柏拉图多面体:立方体、正四面体、正二十面体、正八面体和正十二面体。于是他有了这个他认为绝对完美的理论,即你可以将这些柏拉图多面体嵌入到行星的球体之间。这看起来很契合,在他看来,上帝对行星的设计正符合柏拉图多面体的数学完美性。
他需要数据来证实这个理论。当时,世界上只有一份真正高质量的数据集。第谷・布拉赫(Tycho Brahe)是一位非常富有且古怪的丹麦天文学家,他成功说服丹麦政府资助了这个极其昂贵的天文台。事实上,那是一个完整的岛屿,他在那里对包括火星和木星在内的所有行星进行了数十年的观测,只要天气晴朗,他每晚都会用肉眼观测。他是最后一位肉眼天文学家。他拥有开普勒可以用来验证理论的所有数据。开普勒开始与第谷合作,但第谷对数据非常吝啬,每次只给他一点点。开普勒最终偷走了这些数据,他复制了数据,并不得不与布拉赫的后代发生争执。他确实拿到了数据,然后令他失望的是,他发现他那美丽的理论并不可行。数据与他的柏拉图多面体理论有 10% 左右的偏差。他尝试了各种修补方案,比如移动圆圈的位置,但都不起作用。
但他在这个问题上研究了多年,最终,他弄清楚了如何利用这些数据推导出行星的实际轨道。那是一次极其聪明、天才级的数据分析。接着他发现,轨道实际上是椭圆而不是圆,这对他来说是非常震惊的。于是他得出了行星运动的前两条定律:椭圆轨道定律,以及等面积投影定律(在相等时间内扫过相等的面积)。十年后,在收集了大量数据之后 —— 像土星和木星这样最遥远的行星对他来说是最难推导的 —— 他终于得出了第三定律,即行星完成轨道运行所需的时间与它到太阳距离的某次方成正比。这就是著名的开普勒三大运动定律。他无法解释其中的原理。这完全是由实验驱动的,直到一个世纪后,牛顿才提出了一个能同时解释这三条定律的理论。
Dwarkesh:我想抛给你的观点是:开普勒其实是一个 “高温度值” 的大语言模型(LLM)。牛顿提出了为什么行星运动三大定律必然成立的解释。当然,如你所说,开普勒发现这些定律或推导出各行星相对轨道的方式是天才之举。但在他的职业生涯中,他只是在不断尝试各种随机关系。事实上,在他写下行星运动第三定律的那本书里,它只是《世界和谐》(The Harmonics of the World)中的一个插曲,那本书通篇在讲不同行星如何拥有不同的和谐音程。他认为地球之所以充满饥荒和痛苦,是因为地球的音符是 mi-fa-mi。这全是随机的占星术,但其中却包含着平方 - 立方定律,它告诉了你运行周期与行星到太阳距离的关系。正如你详述的,如果你把这个定律加上牛顿的 F=ma 和向心加速度公式,就能得到万有引力平方反比定律。牛顿就这样推导了出来。
我认为这个故事有趣的原因在于,我觉得 LLM 可以做这类 “尝试随机关系二十年” 的事情,即便其中一些毫无意义,只要有一个像布拉赫数据集那样可验证的数据库即可。“好,我要尝试关于音符、柏拉图物体或不同几何形状的各种随机事物,我直觉地认为这些轨道的几何结构中包含某些重要的东西。” 然后其中一件事奏效了。只要你能验证它,这些经验性的规律就能推动真正的深度科学进步。
(注:在大型语言模型(LLM)中,温度值(Temperature)是一个控制生成结果随机性和创造性的超参数。说开普勒是 “高温度值” 的,是在称赞他极强的探索能力。开普勒的一生,就是在大量观测数据的 “语料库” 中,通过高随机性的尝试,最终捕捉到了那个极其罕见的正确预测。)
陶哲轩:传统上,当我们谈论科学史时,“创意生成” 一直是科学中最具声望的部分。一个科学问题包含许多步骤:你必须识别一个问题,然后识别出一个好的、有成果的问题去研究;然后需要收集数据,想出分析数据的策略并提出假设。在这一点上,你需要提出一个好的假设,然后进行验证,最后需要写成文章并进行解释。这里有十几个不同的组成部分。而我们庆祝的是那些灵光一闪的天才创意生成时刻。开普勒确实经历过许多创意的循环,其中有些并不可行。我敢打赌,有很多创意他甚至根本没有发表,因为它们根本不符合数据。这是过程的重要组成部分 —— 尝试各种随机事物并观察是否有效。但正如你所说,这必须辅以同等程度的验证,否则它就是一堆 “废料(slop)”。
我们赞美开普勒,但也应该赞美布拉赫,因为他进行了刻苦的数据收集,其精度是之前任何观测的十倍。多出的那一位小数精度对于开普勒获得结果至关重要。他使用了欧几里得几何和当时能用的最先进数学手段来让模型匹配数据。所有环节都必须参与其中:数据、理论和假设生成。我不确定如今假设生成是否还是瓶颈。在一个世纪以来的发展中,科学已经发生了变化。传统上,科学的两大范式是理论和实验。随后在 20 世纪,数值模拟出现了,你可以通过计算机模拟来测试理论。最后在 20 世纪后期,我们迎来了大数据和数据分析时代。现在许多新进展实际上是先通过分析海量数据集来推动的。你收集大数据,然后从中提取模式以推导思想。这与过去的科学运作方式略有不同 —— 过去是你进行少量观察或产生一个突发奇想,然后收集数据来测试你的想法。那是经典的科学方法。现在几乎反过来了。你先收集大数据,然后尝试从中获取假设。
开普勒可能是最早的早期数据科学家之一,但即使是他,也不是先拿着第谷的数据集然后去分析的,他先有一些预设的理论。随着数据变得越来越庞大且有用,那种旧的模式似乎越来越不再是我们取得进步的主要方式了。