英伟达龙虾登场爱范儿
今年英伟达 GTC 主题演讲,应该是史上悬念最少的一届。
2022 年说元宇宙,2023-2024 年说生成式 AI,2025 年说物理 AI。但今年不一样,即便台上英伟达创始人黄仁勋的演讲还没有开始,但台下所有人已经知道答案了——Agent。
包括英伟达也悄悄在 GTC 园区里开设了「Build-a-Claw」互动专区,让与会者现场搭建自己的AI Agent。 从芯片到模型,从英伟达版龙虾到数据中心,今年主题演讲的潜台词只有一句话:
一切都要为 Agent 让路。
专为 Agentic AI 打造的 Vera Rubin 正式发布
如果说 Hopper 架构开启了生成式 AI(Generative AI)的时代,让机器学会了「说话」;那么 Vera Rubin 的使命,就是开启智能体(Agentic AI)时代,让机器学会「干活」。
英伟达 Vera Rubin 架构包含七款芯片、五套机架系统,以及一台用于 AI Agent 的超级计算机七款芯片分别是 NVIDIA Vera CPU、NVIDIA Rubin GPU、NVIDIA NVLink6 交换机、NVIDIA ConnectX-9 超级网卡、NVIDIA BlueField-4 DPU 和 NVIDIA Spectrum
-6 以太网交换机,以及新集成的 NVIDIA Groq 3 LPU
五个机架分别是 NVIDIA Vera Rubin NVL72 机架、NVIDIA Vera CPU 机架、NVIDIA Groq 3 LPX 机架、NVIDIA BlueField-4 STX 存储机架,以及 NVIDIA Spectrum-6 SPX 以太网机架。过去的 AI 像是一个极其聪明的图书馆管理员,我们问一个问题,它慢条斯理地翻书,然后把答案整理出来。我们对这种速度是宽容的,因为我们自己打字看书也慢。
但 Agent 完全不同。它不仅要用大模型思考,还要疯狂地调用工具——比如打开浏览器、控制云端的虚拟 PC、在无数个数据库里来回比对。更要命的是,AI 对工具的容忍度极低,它要求一切操作都在毫秒级完成。
「它会狠狠地捶打内存。」黄仁勋在台上这样形容。
当模型越来越大,上下文长度从十万 Token 飙升到数百万,还要同时处理结构化和非结构化的数据,传统的算力架构开始喘不过气了。为了应对这种「捶打」,英伟达交出了第一份答卷,全新的 Vera CPU。
这颗芯片特立独行,它是世界上首款专为智能体 AI 和强化学习时代打造的处理器,其效率是传统机架式 CPU 的两倍,速度提升 50%,采用 LPDDR5X 内存,能实现极高的单线程性能、大型的数据吞吐量和极致的能效。
黄仁勋甚至毫不掩饰他的骄傲:「我们从没想过会单独卖 CPU,但现在,这绝对是一个价值数十亿美元的业务。」
紧随其后的是 Rubin GPU,单片芯片直接塞进了高达 288 GB 的海量内存。它就像是一个拥有无限脑容量的思考者,专门用来装载那些体积越来越庞大的超大语言模型,以及处理成百上千万的上下文 KV 缓存。
除了堆叠 CPU 和 GPU,英伟达这次发布的 Vera Rubin 架构,直接把 NVLink 的带宽翻了一倍——260 TB/s 的全互联带宽。
十年前,DGX-1 用第一代 NVLink 把 8 张卡连在一起,那是专为 AI 研究员打造的奇迹;到了 Hopper 时代,是 NVLink 4;而前不久的 Blackwell 架构,用 NVLink 72 实现了 72 张 GPU 的全互联,带宽达到 130 TB/s。
为了配合 Vera Rubin,黄仁勋甚至掏出了被称为 Kyber 的全新机架。在这个机架里,计算节点垂直插入,背后是第六代 NVLink 交换机。完全抛弃了传统的以太网或 InfiniBand 限制,在一个 NVLink 域内直接打通 144 张 GPU。
即便强如 Vera Rubin,在面对「无限生成 Token」的极端需求时,也会感到吃力。
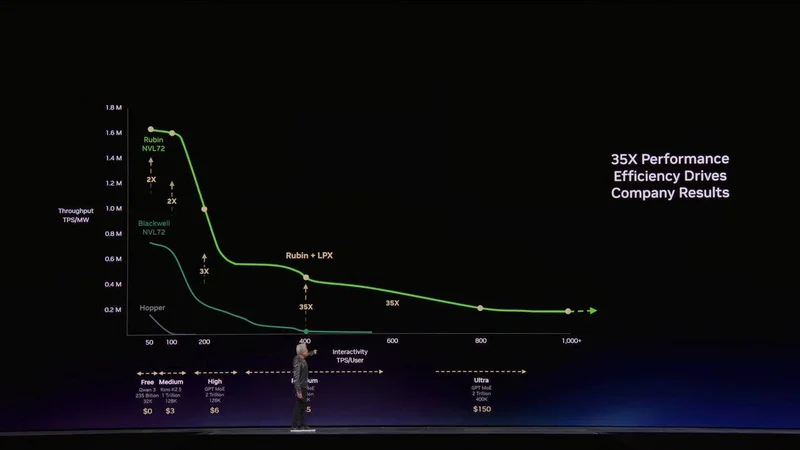
在算力世界里,吞吐量(Throughput,同时处理巨量任务的能力)和延迟(Latency,单次任务的极速响应)是一对物理学上的死敌。英伟达是吞吐量的绝对霸主,但在极致低延迟的 Token 生成上,传统 GPU 架构显得过于笨重。
这时候,Groq 出场了。英伟达早在之前就「收购」并授权了 Groq 团队的技术,在今天正式推出了 Groq LPU(语言处理单元)。
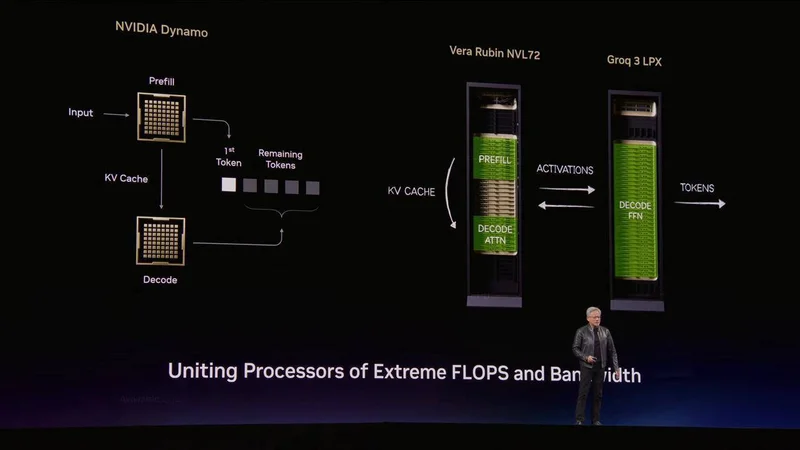
黄仁勋用一款名为 Dynamo 的软件,把这两者完美捏合,首创了「解耦推理(Disaggregated Inference)」。
AI 推理前半段的 Prefill(预填充)和极其耗费算力的 Attention(注意力机制),全部交给 Vera Rubin 这个性能王者来处理;后半段的 Decode(解码),也就是生成 Token 的瞬间,直接卸载给 Groq LPU 来降低延迟。
结果显示,在最具商业价值的高端推理层级,这种组合让性能直接飙涨了 35 倍,且每兆瓦的吞吐量同样提升了 35 倍。