首个龙虾大模型排行榜:两国产AI杀进前三APPSO
首个龙虾AI基准测试排行榜出炉,32款模型同台竞技,Gemini 3 Flash以95.1%成功率夺冠,国产MiniMax与Kimi双双杀入全球前三,完胜GPT-4o。扎心的是,Claude旗舰版成本高达竞品近200倍,准确率反不及中端模型。
你现在养了几只龙虾?
这就是现在打招呼最常见的问题,上周腾讯深圳总部排起龙等着免费装 OpenClaw,真是一代人有一代人的鸡蛋。
连黄仁勋也盛赞 OpenClaw 为「有史以来最重要的软件发布」,认为它已经证明了 AI 在高度个性化环境中,能够完美复刻人类的复杂工作流。
养龙虾太过火爆,也终于出现专门针对 OpenClaw 的基准测试 PinchBench,用于评估大语言模型在 OpenClaw 任务中的表现。
PinchBench 评分方式也很硬核,有的任务看代码能不能跑通(自动化检查),有的看写得好不好(Claude Opus 当评委),还有的是两者结合。所有题目和答案都开源在 GitHub 上,谁都可以去验货。
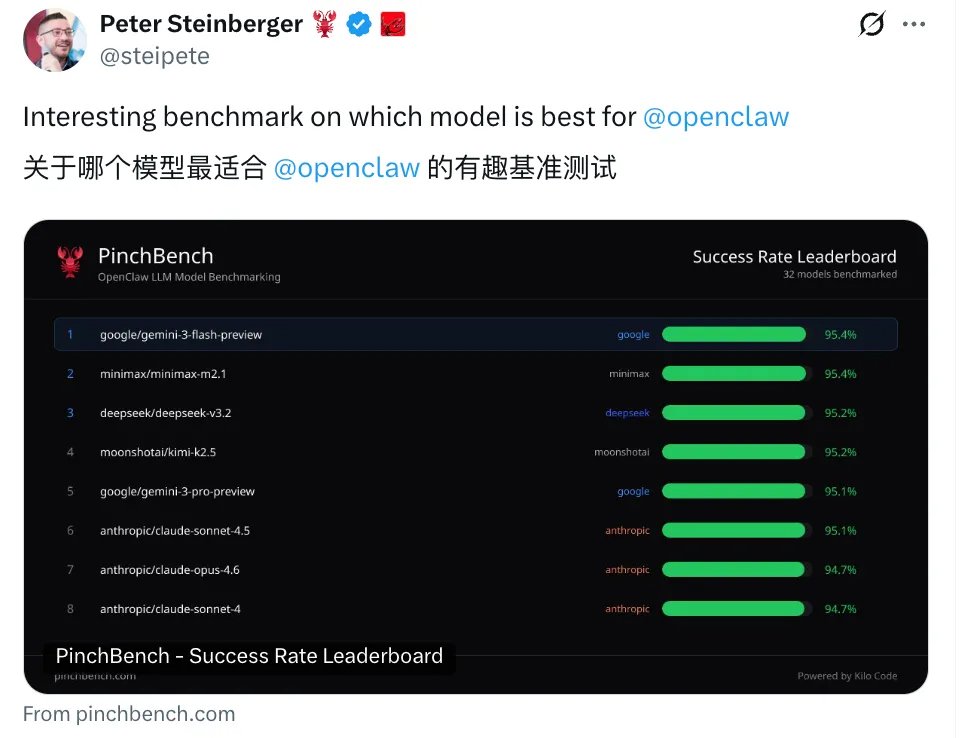
今天,OpenClaw 创始人 Peter Steinberger 分享这个龙虾基准测试排行榜。
PinchBench 一口气测了 32 款主流大模型,从成功率、速度、费用三个维度,看看哪个模型最适合养龙虾。
PinchBench 官网:https://pinchbench.com/
Gemini 3 Flash 成功率最高,国产模型也杀疯了
来看最重磅的成功率排名。
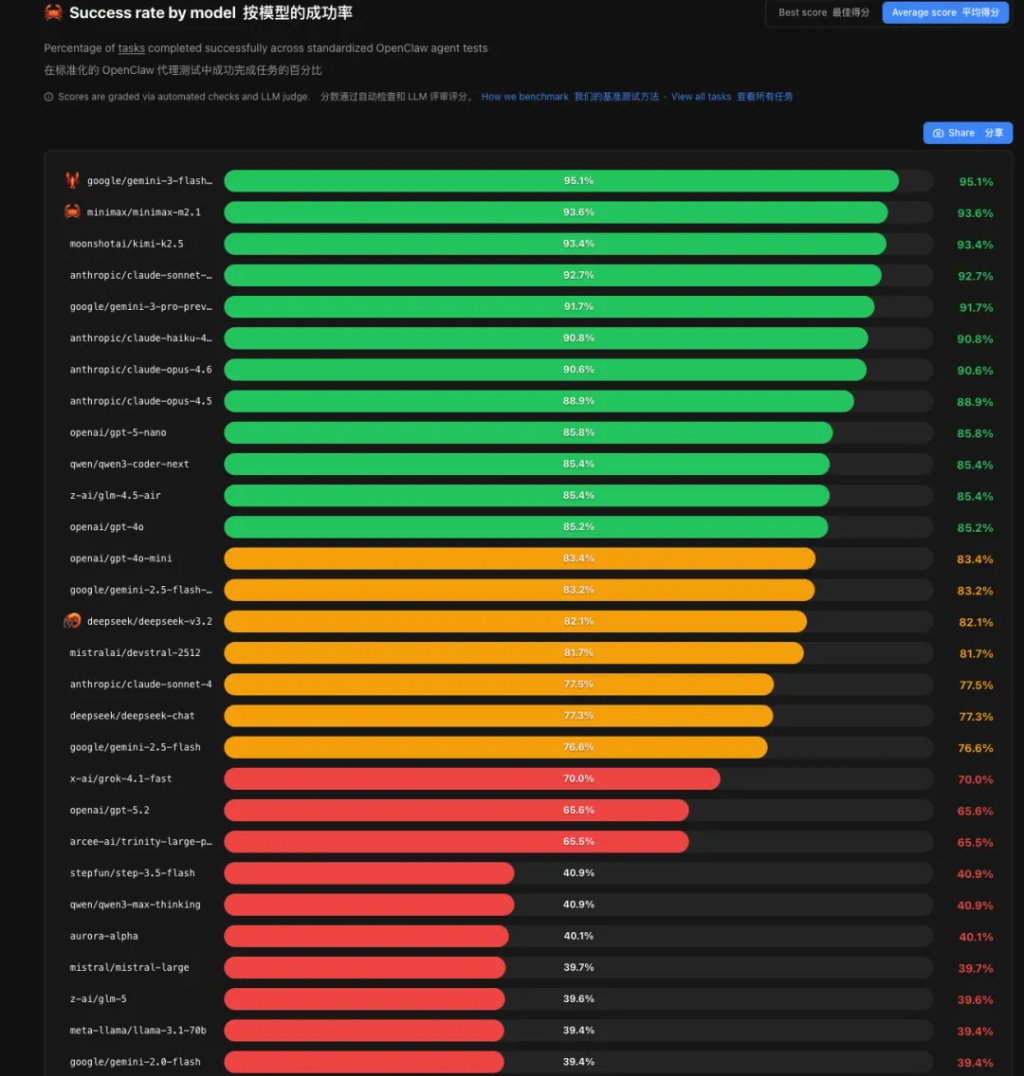
Google 的 Gemini 3 Flash Preview 以 95.1% 的成功率夺冠,这个成绩说实话让我有点意外。因为 Flash 系列一直是 Gemini 的「轻量版」,主打快和便宜,没想到这次在准确率上直接把自家 Pro 老大哥和 Claude、GPT 系列全超了。
这说明Google 在模型效率优化上是真的下了功夫。轻量模型不代表能力弱,关键看怎么调。
第二名是 MiniMax M2.1,成功率 93.6%。国产模型真的站起来了,MiniMax 的表现相当亮眼,成功压过了 Claude Sonnet 4.5(92.7%)和 GPT-4o(85.2%)。
Kimi K2.5 紧随其后,成功率 93.4%。Kimi 的长文本能力一直很强,这次在编程任务上也证明了自己。和 MiniMax 一起,国产双雄直接占据了 TOP3 的两个席位。
再往后看,Claude Sonnet 4.5 排第四(92.7%),Gemini 3 Pro 第五(91.7%),Claude Haiku 4.5 第六(90.8%)。
有意思的是,Claude Opus 4.6 作为 Anthropic 的旗舰大模型,成功率只有 90.6%,排在第七。
看来「大」不一定「强」,至少在编程这个场景下,中端模型反而更香。
唯快不破,MiniMax 赢麻了
在开发这些重度任务中,谁都不想对着屏幕干等。速度接影响干活的心情。
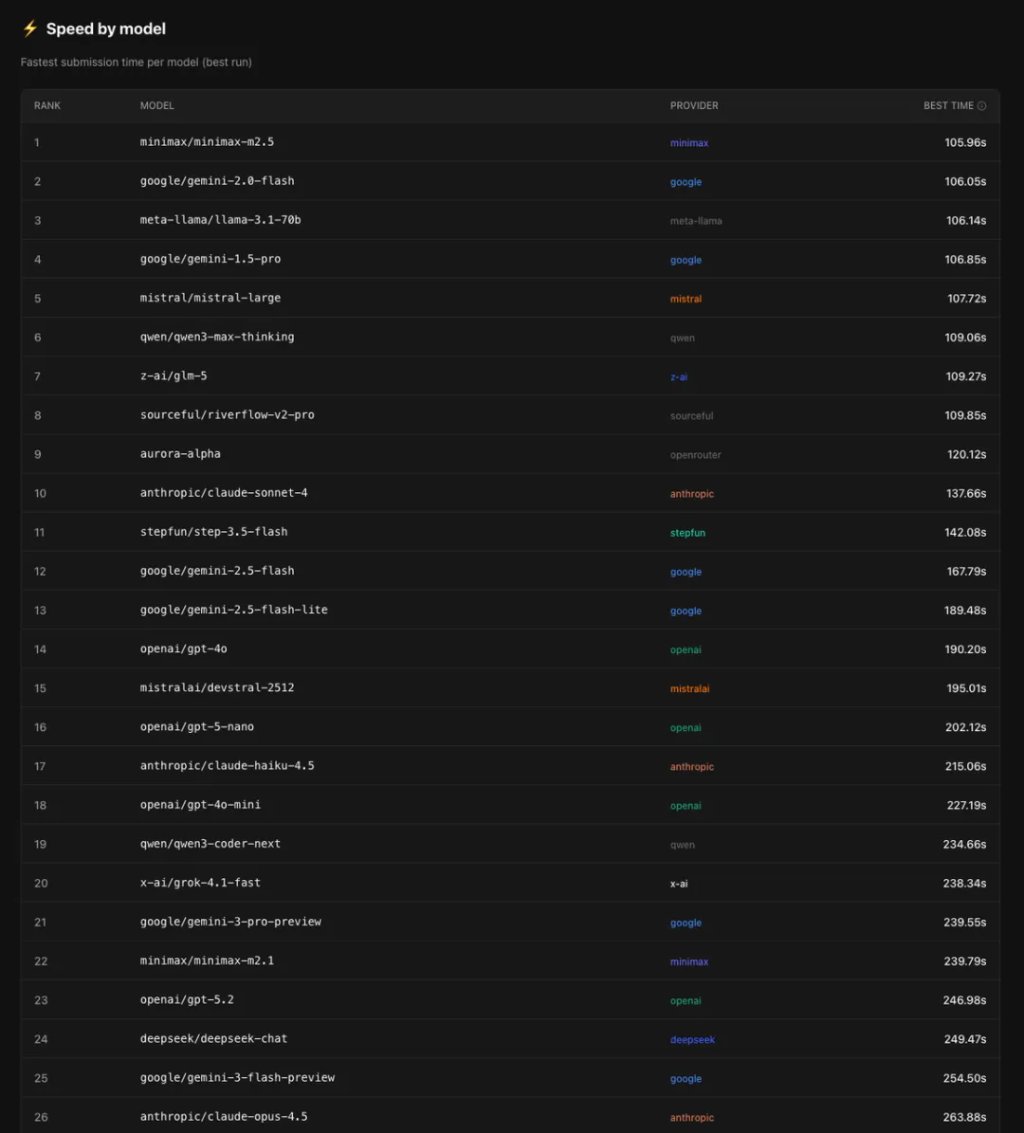
MiniMax M2.5 以 105.96 秒的成绩拿下速度冠军,完成全部测试任务。什么概念?比第二名 Gemini 2.0 Flash 只快了 0.09 秒,但第一就是第一。
第三名 Llama 3.1 70B(106.14 秒)、第四名 Gemini 1.5 Pro(106.85 秒)、第五名 Mistral Large(107.72 秒)——这几个差距都不大,基本在同一梯队。
但往下看就有意思了。
Claude Sonnet 4 用了 137.66 秒,比第一梯队慢了 30 秒。Gemini 3 Pro 更是用了 239.55 秒,是 MiniMax M2.5 的两倍多。
这说明一个规律:轻量级模型普遍更快。如果你做的是快速原型开发、需要频繁迭代,选轻量模型准没错。但如果是那种「跑一遍就行」的任务,等等大模型也无妨。
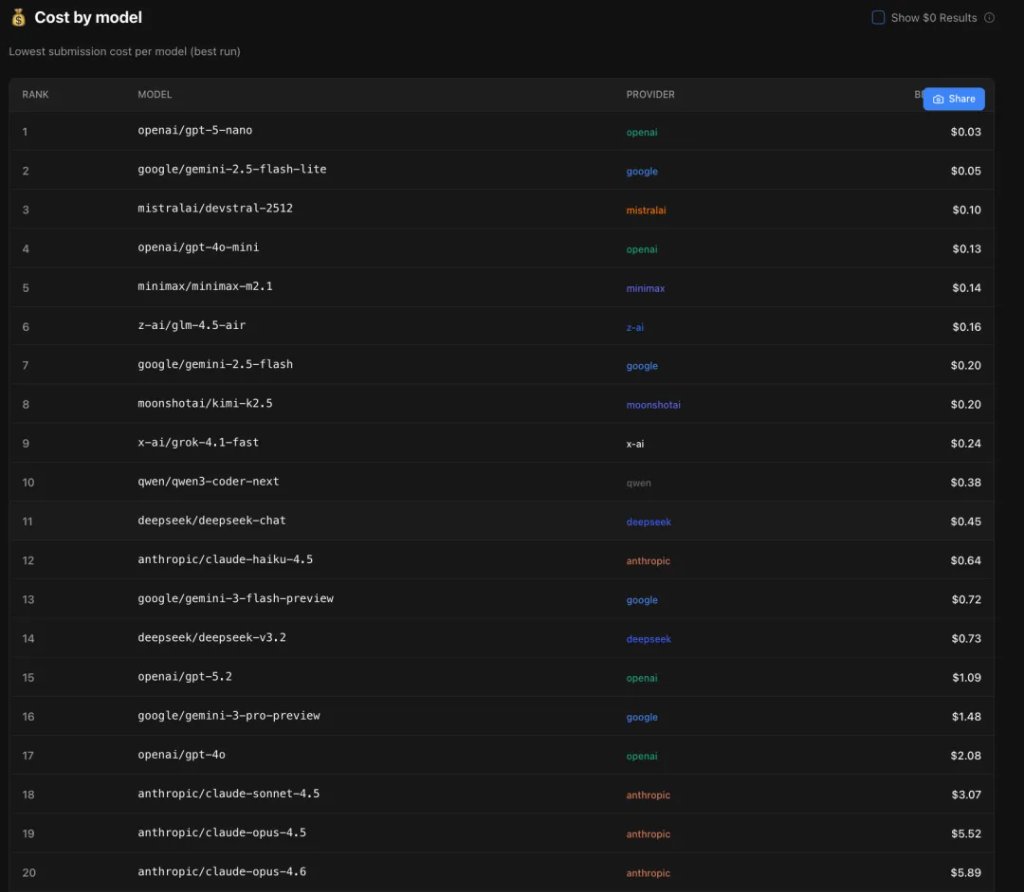
怎么养龙虾最划算
养龙虾,精打细算很重要,毕竟很多OpenClaw 任务都是 Token 无底洞,稍不留神就能让你怀疑人生。
GPT-5 Nano 以 0.03 美元的成本成为全场最便宜的选择,成功率 85.8%。虽然准确率不算顶尖,但这个价格……还要什么自行车?适合预算有限、对错误容忍度高的场景。
Gemini 2.5 Flash Lite 排第二,只要 0.05 美元,成功率 83.2%。这个性价比就很能打了——成本是 GPT-5 Nano 的不到两倍,成功率只低了 2.6 个百分点。
MiniMax M2.1 排第五,成本 0.14 美元,但别忘了它的成功率是 93.6%。算下来每百分点的成本只有 0.0015 美元,性价比极高。
再看高端模型的成本,就有点触目惊心了。