GPT-5.4打个招呼,80美元就烧完了腾讯科技
北京时间3月6日凌晨,OpenAI正式发布新一代旗舰模型GPT-5.4,官方定位为"专为专业工作而设计的最强且最高效的前沿模型"。
手捧GPT-5.4的奥特曼。图片由AI生成
比起“更强更快”的常规叙事,这次发布真正值得关注的是模型角色的转变:GPT-5.4是一个为Agent而生的模型。它首次将原生计算机操控能力融入通用模型,并同时整合了GPT-5.3-Codex级别的编程能力、百万Token上下文窗口和工具搜索机制——据官方介绍,没有为整合而牺牲任何单项能力。过去让AI操作电脑需要依赖专用的ComputerUse Agent,现在编程、操控电脑、调用工具由同一个模型一并完成。
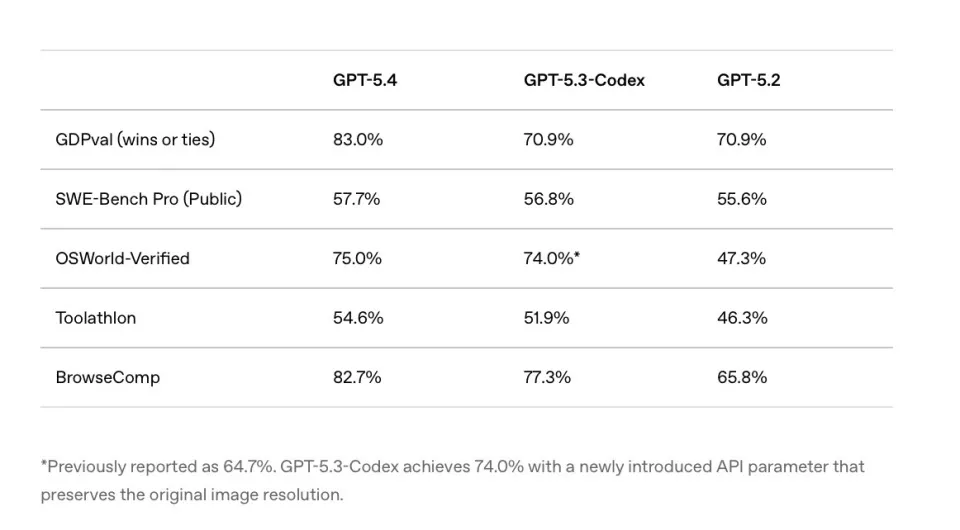
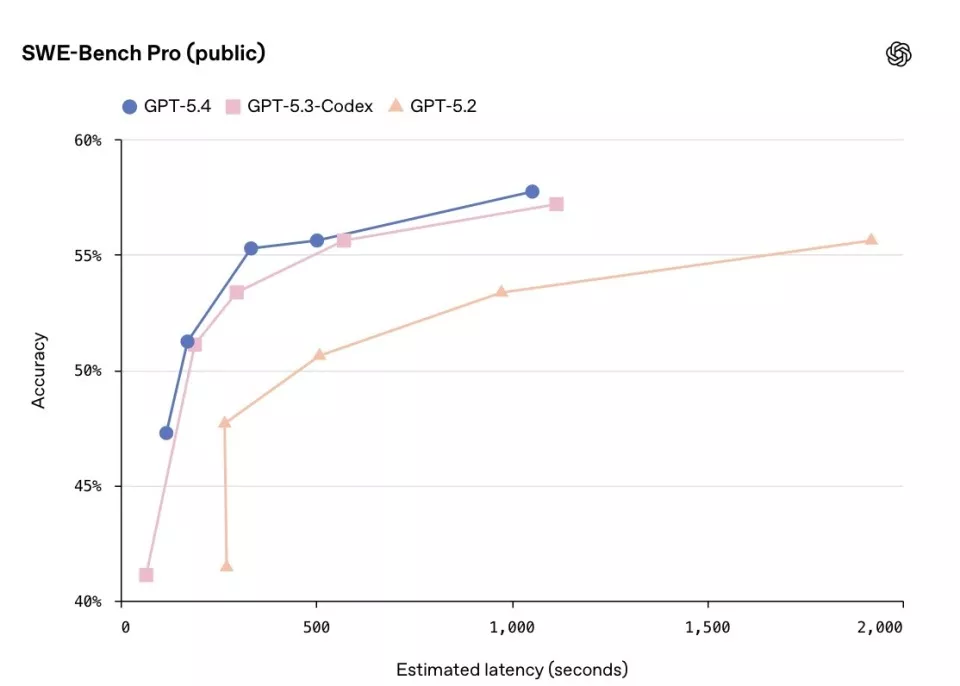
跑分印证了这一点:GDPval基准测试中,GPT-5.4在83%的任务上达到或超过行业专业人士水平;OSWorld桌面操控测试成功率75%,首次超过人类基线(72.4%);编程能力与GPT-5.3-Codex持平,世界知识比GPT-5.2更强。
价格方面,GPT-5.4的API定价为输入$2.50/百万Token、输出$15,约为Claude Opus4.6($5/$25)的一半,且支持订阅额度调用。不过Pro版依然很贵——有网友仅发了一句"Hi",GPT-5.4Pro就认真推理了一番,直接烧掉80美元。日常轻量任务,标准版可能是更明智的选择。
在ChatGPT中,GPT-5.4以“GPT-5.4 Thinking”形式上线,逐步取代GPT-5.2Thinking(后者将保留3个月,于2026年6月5日正式退役)。新增的前置思路概述功能让用户可以在模型执行过程中随时介入调整方向,网页版和Android已上线,iOS即将跟进。
如果用一句话概括GPT-5.4的意义,过去几年大模型的进化逻辑是"哪块短板补哪块",GPT-5.4不再单点拔高,而是把所有能力整合进同一个模型做系统性优化。一个能写代码的模型是工具,一个能写代码、打开浏览器查文档、调用API验证结果、再把输出整理成报告的模型,是工作系统。GPT-5.4更接近后者。
01 在83%的任务中达到或超过行业专业人士水平
GPT‑5.4 与前代模型在多项专业能力基准测试中的表现对比
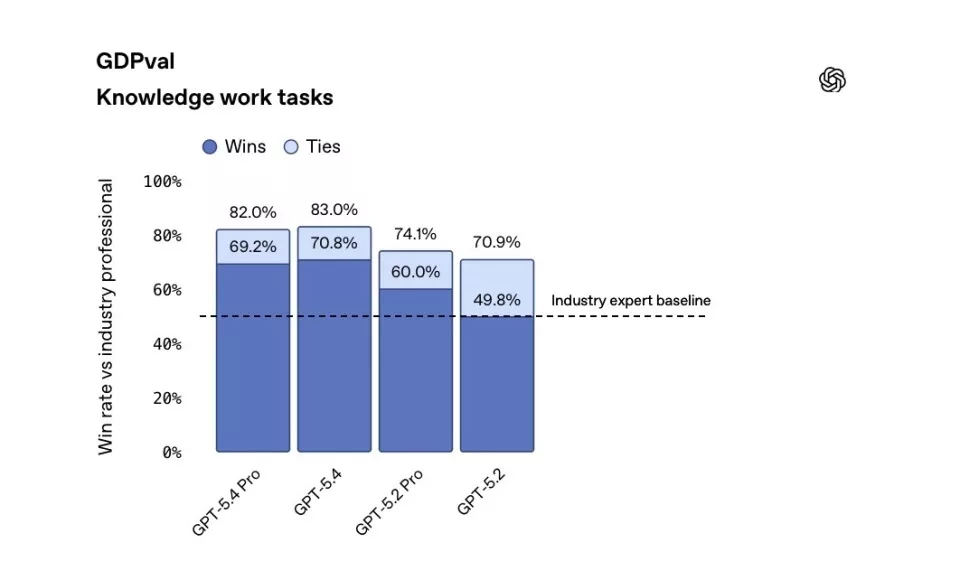
为了评估模型在真实工作环境中的表现,OpenAI使用GDPval基准测试,这项测试要求模型完成完整职业任务,而不仅仅是问答。GDPval覆盖美国GDP贡献最大的九个行业和四十四种职业场景,包括制作销售演示文稿、建立会计电子表格、安排医院急诊排班、绘制制造流程图或生成短视频内容。
GPT‑5.4 与前代模型在GDPval基准测试中的对比
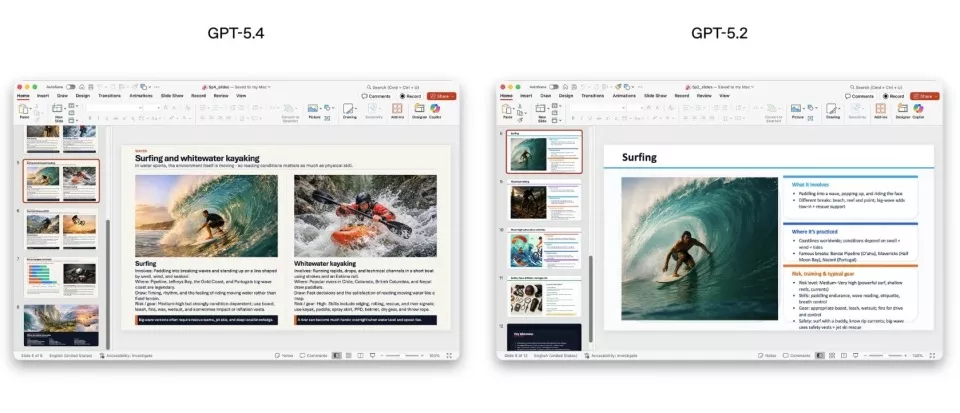
在测试中,GPT‑5.4在83%的任务中达到或超过行业专业人士水平,而GPT‑5.2仅为70.9%。模拟初级投行分析师的电子表格建模测试中,GPT‑5.4平均得分87.3%,GPT‑5.2为68.4%。演示文稿生成任务中,人类评测者68%情况下更偏好GPT‑5.4的输出,理由是视觉设计更成熟、结构更清晰、图像使用更合理。
招聘平台Mercor在面向专业服务工作的APEX-Agents评测中也得出类似结论。CEO布伦丹·富迪(BrendanFoody)表示,GPT‑5.4在生成财务模型、法律分析和完整幻灯片等长期交付成果方面表现突出,同时运行速度更快,成本低于同级前沿模型。
OpenAI还推出了ChatGPTExcel插件,使企业用户能够在Excel中直接调用模型,实现AI与传统办公软件的无缝协作。
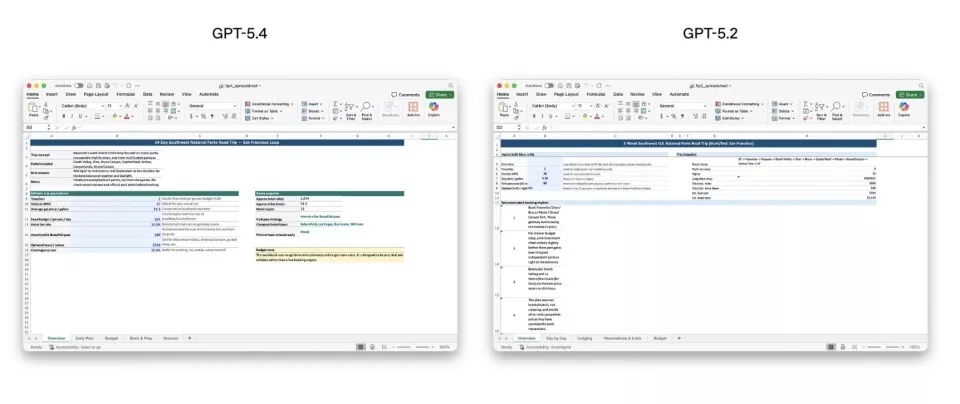
GPT‑5.4电子表格、演示文稿和文档创建及编辑能力的提升
OpenAI特别关注GPT‑5.4在电子表格、演示文稿和文档创建及编辑能力上的提升。在一项内部电子表格建模测试中,GPT‑5.4的平均得分达到87.3%,显著高于GPT‑5.2的68.4%。在演示文稿评估中,人类评测者在68%的情况下更偏好GPT‑5.4生成的内容,认为其视觉设计更成熟、结构更清晰、视觉变化更丰富,同时图像生成的运用也更为有效。
02 原生“操作”电脑
GPT‑5.4的最大亮点或许并非编程,而是计算机操控能力的原生整合。过去,模型要操作电脑通常需要专用的Computer UseAgent,而GPT‑5.4首次将这一能力直接融入通用模型。它不仅可以编写控制计算机的软件脚本,还能根据屏幕截图直接发出鼠标点击和键盘输入指令,从而完成跨应用程序的复杂操作。
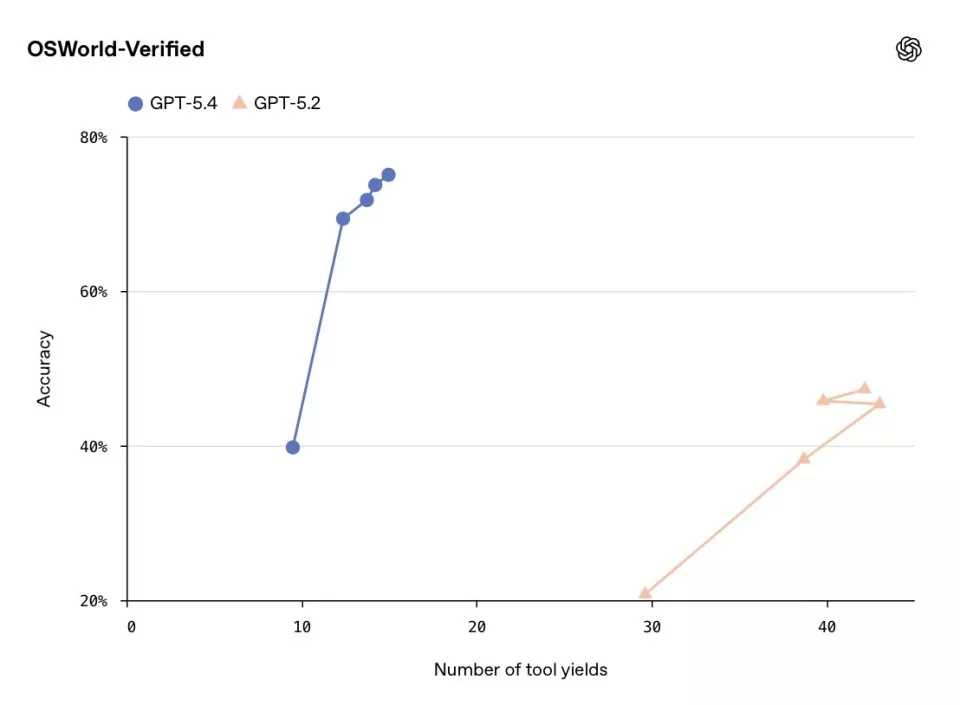
GPT‑5.4与GPT‑5.2在OSWorld-Verified测试中的表现
在OSWorld-Verified测试中,GPT‑5.4通过截图识别桌面界面并执行键鼠操作的成功率达到75%,明显高于GPT‑5.2的47.3%,甚至略高于人类平均水平72.4%。在WebArena-Verified浏览器操控测试中,成功率为67.3%,高于GPT‑5.2的65.4%。仅通过截图理解网页结构的Online-Mind2Web测试中,成功率达到92.8%,远高于ChatGPTAtlas智能体模式的约70%。
房地产数据公司Mainstay对这一能力进行了大规模实测。覆盖约三万个HOA和房产税门户网站的测试中,GPT‑5.4首次尝试成功率95%,三次以内成功率100%,任务完成速度提升约三倍,Token消耗减少约70%。这意味着基于GPT‑5.4的自动化系统(如RPA)在可靠性和成本上可能发生根本性变化。
03 视觉理解与文档解析能力显著提升
GPT‑5.4与GPT‑5.2在MMMU-Pro和OmniDocBench测试中的表现
除了计算机操控能力,GPT‑5.4在视觉理解和文档解析方面也有进步。在内部 MMMU-Pro测试中(无需外部工具辅助),GPT‑5.4的视觉理解准确率达到81.2%,高于GPT‑5.2的79.5%;在含工具辅助的测试中,GPT‑5.4进一步提升至82.1%,同样优于前代模型。
这表明模型不仅能操作电脑,还能更准确地识别屏幕信息和解析文档内容,为长周期、多步骤的办公任务提供支持。
在OmniDocBench文档解析测试中,GPT‑5.4的平均归一化编辑距离为0.11,低于GPT‑5.2的0.14,显示出更高的解析精度和生成文档的准确性。
这意味着GPT‑5.4在处理复杂文档内容时,能够更好地理解结构、保持信息完整,同时减少错误,为企业办公、数据分析和报告生成提供可靠支撑。
此外,OpenAI对高分辨率和高密度图像的处理能力也有所增强。从GPT‑5.4开始,模型支持“原始图像输入细节”模式,可处理总量最高达1024万像素或最大边长6000像素的全保真图像;“高细节”模式支持最高256万像素或最大边长2048像素。
这使得模型在目标定位、图像理解及点击精度方面表现更佳,同时提升了文档生成、演示文稿和图表的质量。
04 编程与工具生态进一步强化
GPT‑5.4与GPT‑5.3-Codex的编程能力对比图