理想汽车发现端侧Scaling Law新智元
如何把庞大的大模型塞进受限的车载芯片?面对端侧算力瓶颈,最新的「软硬协同设计定律」给出破局解法:只需输入芯片参数,即可免训练算出最优模型架构。同等算力下,模型智商跃升近20%,研发周期从数月缩至一周。
如何把「大象」塞进冰箱?
这正是现代智能辅助驾驶正在努力完成的一个命题。
我们希望车子能拥有一个像爱因斯坦一样聪明的超级大脑,但现实的尴尬是:
你不可能在后备箱里塞进一个需要液冷的服务器机柜!
当云端大模型正在加速冲刺AGI的同时,具身智能、智能驾驶等真实物理场景却正面临着一个隐性的巨大焦虑:「小」。
如何把「大模型」塞进极其有限的「小空间」车载芯片或机器人控制核心里?
这就是目前智能驾驶、具身智能、VR等领域碰到的一个现实问题:
被一块小小的芯片「卡住了脖子」。
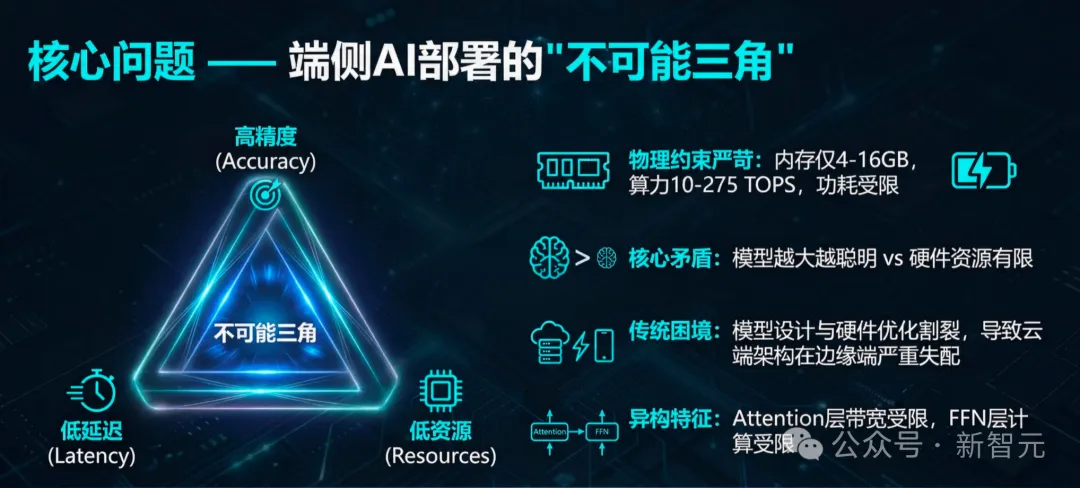
智能驾驶正在迈向全场景智能,但车载算力平台撞上了一个核心悖论:
比如,一个在云端GPU上10毫秒就能完成的推理任务,到了车载芯片上可能要300毫秒。对自动驾驶来说,300毫秒意味着车辆在高速上「盲开」了好几米。
所有巨头,英伟达、苹果、微软、谷歌都在想办法。
但是第一个给出理论级答案的,是一家中国车企。
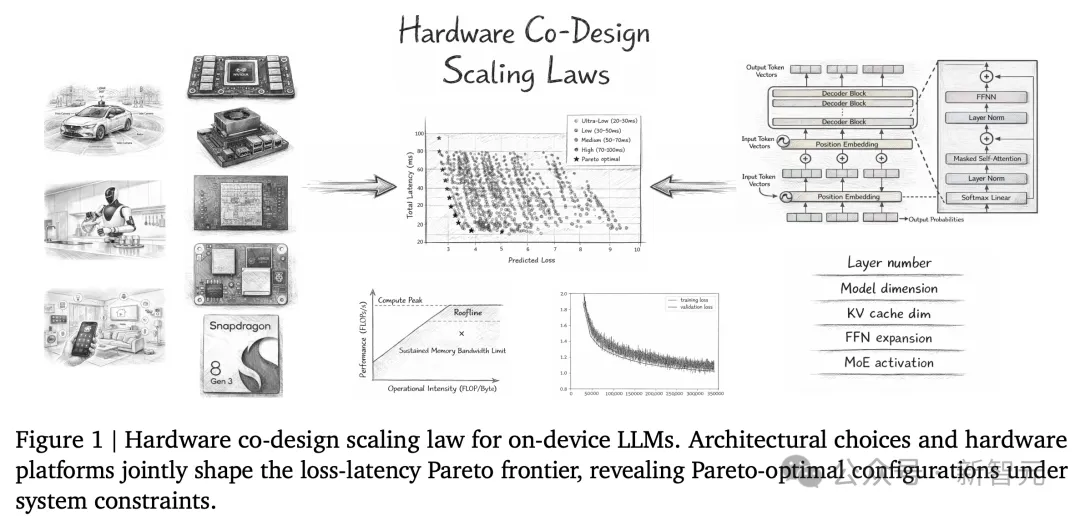
2026年2月,理想汽车基座模型MindVLA团队与国创决策智能技术研究所联合发布了一篇论文:《Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs》。
提出了面向端侧大语言模型的「硬件协同设计扩展定律」。
论文地址:https://arxiv.org/abs/2602.10377
这篇论文直面了当前最核心的挑战之一:
如何将越来越强大的大语言模型高效地部署在资源受限的「端侧设备」(如汽车、手机、机器人)上。
提到理想汽车,多数人的第一反应还是「增程式电动车的代表」。但审视其近两年的技术布局:自研5nm车规芯片马赫100、开源操作系统星环OS、自研基座大模型MindVLA、端到端智驾全栈自研。
理想正在从一家以增程技术见长的汽车公司,蜕变为一家以智能驾驶和具身智能为核心的AI公司。
而这篇刚刚发布的论文,是理解这场转型最好的注脚。
大模型「上车」,卡住了!
如何将目前「最先进的AI」装入汽车?
这里会遇到了一个巨大的矛盾:
一方面,希望车载AI模型尽可能地聪明、反应迅速,以确保驾驶安全和流畅的交互体验。这要求模型规模大、结构复杂。
另一方面,汽车内部的计算单元(芯片)受到严格的物理限制,包括功耗、散热、内存大小和成本。这要求模型必须小巧、高效。
传统的做法通常是「模型归模型,硬件归硬件」。
AI研究者设计出性能强大的模型,然后由工程师想办法在硬件上进行优化和「塞入」。
这种方式效率低下,且往往无法达到真正的最优。
这就好比为一个F1赛车引擎设计了一个巨型卡车的底盘,二者无法完美匹配,引擎性能大打折扣。
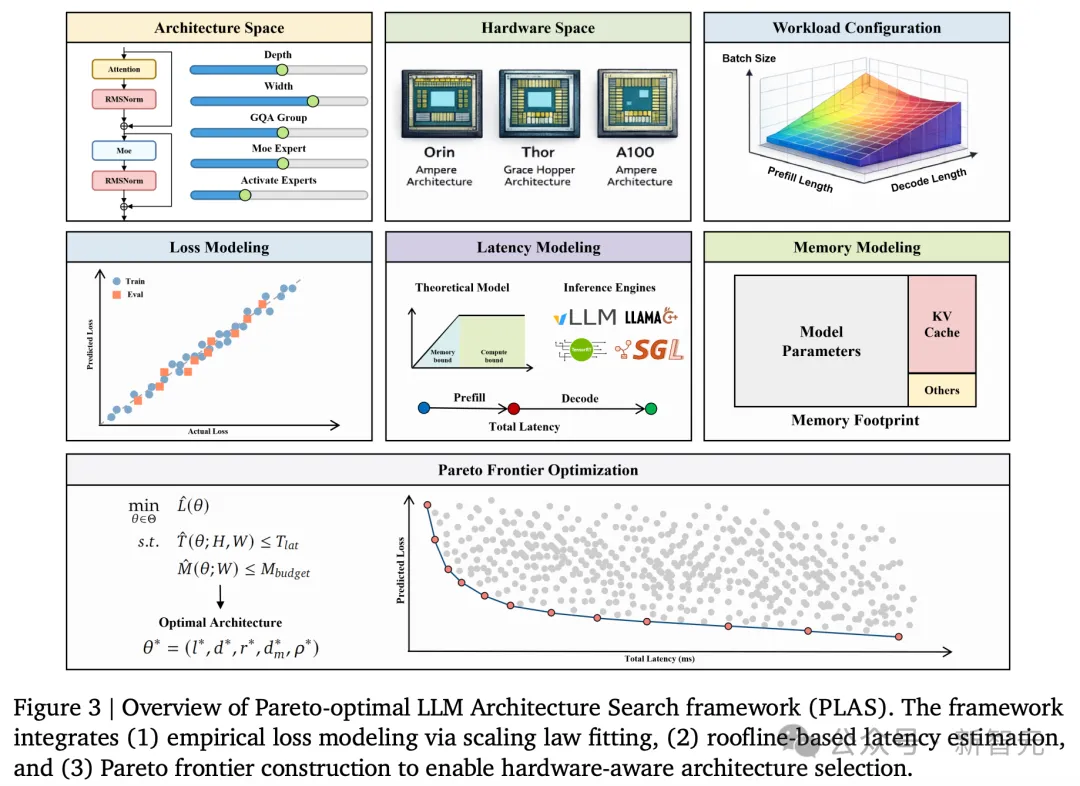
而理想这篇论文正是为了解决这个「失配」问题,他们提出了一套系统性的方法:
在设计模型之初就将硬件的能力考虑进来,实现「软硬协同设计」(Hardware Co-Design)。
架构选择(右侧)与硬件平台(左侧)共同塑造损失-延迟帕累托前沿
软硬协同:连接模型与硬件的桥梁
如何衡量模型的「智慧」?
先来简单介绍下什么是损失-延迟帕累托前沿。
在AI领域,「损失」是衡量模型预测与真实答案之间偏差的指标。
损失越低,模型预测越准确,代表它越「聪明」、精度越高。你可以把它理解为「工作质量」。
延迟指的是AI给出反应需要多长时间。延迟越低,速度越快,代表它能做到「秒回」。你可以把它理解为「工作速度」。
帕累托前沿是一个经济学概念。
通俗地说,当你追求既要「质量高」(低损失),又要「速度快」(低延迟)时,你会遇到一个物理极限。
到了这个极限状态后,你不可能在不牺牲速度的前提下,让AI变得更聪明;也不可能在不牺牲聪明度的前提下,让AI跑得更快。
所有这些「最优的折中点」连起来的一条线,就叫「帕累托前沿」。
理想团队发现,模型的最终损失与其架构超参数(如网络深度、宽度、专家数量等)之间存在着可预测的数学关系。