陶哲轩:AI将如何改变“最保守学科”学术头条
日前,菲尔茨奖得主、华裔数学家、加州大学洛杉矶分校教授陶哲轩在牛津数学公开讲座中,探讨了人工智能(AI)将如何改变数学这个“最保守的学科”。
他指出,数学有着惊人的连续性——200 年前的教科书今天仍可使用,黑板与粉笔依然是标配,论文合著者数量长期徘徊在每篇 2.5 人,远低于其他科学的“大合作”模式。但这种延续数个世纪的研究范式,正在被新技术打破。
核心观点如下:
形式化验证使正确运用机器学习和 AI 来解决问题成为可能。
当前 AI 本质是“猜测机器”,必须与验证器结合,AI 负责批量生成候选答案,验证器负责剔除错误。
AI应处理“中等难度长尾问题”,而非替代数学家攻坚。 最有效的应用方向不是让AI挑战人类最擅长的创造性难题,而是让它完成第一遍筛选,再把真正困难的留给人类专家。
数学研究正在从“个案研究”转向“大规模调查”。AI 的使命不是缩小数学的蛋糕,而是把它做大。
学术头条在不改变原文大意的情况下,做了简单的编译。演讲内容如下:
我将谈谈我所在的数学领域在 AI 时代是如何发生变革,以及这种变革可能对其他学科产生的影响。但当前我们身处一个充满变革和不确定性的时代,这是我们不太习惯的。就数学领域而言,我们或许是所有学科中最保守的,因为几个世纪以来,我们的研究方法几乎未曾改变。
左侧展示的是一本 200 年前由柯西教授撰写的教科书,其中介绍了我们现在称之为柯西积分公式的内容。虽然在当前的分辨率下难以辨认,但是它的内容几乎和如今研究生使用的教材一模一样。除了它是法语而不是英语,且没有采用现代计算机排版语言排版之外,它如今完全可以使用。数学的这种连续性正是其强大的一大优势。我们使用 200 年前、甚至 2000 年前的成果。比如我在工作中经常用到勾股定理。这确实很棒,但这确实意味着我们往往不像其他学科那样热衷于追逐潮流。
右边这本咖啡桌画册是由摄影师杰西卡·温创作的。她对数学家使用的黑板非常着迷。我们几乎是唯一一个仍然保留黑板和粉笔的学科了。其他人都开始用 PPT、白板等现代工具了。但是,我的办公室里还是有六块黑板。我超爱它们,绝对舍不得丢弃。话说回来,她给数学家们的黑板拍了照片,制作了一本精美的小型艺术画册。
我们与其他科学领域的区别还在于,数学研究往往缺乏合作。这里有一些科学指标可以参考:多年来,我们论文的合著者平均数从每篇 1.5 人逐渐上升到数学领域的 2.5 人。但看看其他学科,它们正在蓬勃发展——那些大型合作研究项目层出不穷,数学家们却远远落后。
现在,这并不是因为我们不善交际,或者不仅仅是因为不善交际。这里确实存在一些系统性问题。
传统数学项目历来都有很高的准入门槛。通常需要数学博士才能理解研究课题。我们要求证明必须在每个细节上都做到百分之百正确。所以,如果你尝试通过众包获取证明,当 100 个贡献中有一份出错时,整个证明就会被推翻。而我们现有的工作流程,比如用粉笔在黑板上一起讨论解决问题,无法扩展到与 100 人通过互联网进行协作。
其他科学领域正在蓬勃发展,我们难道就落后了吗?
其实情况正在开始改变,这要归功于新技术的推动,包括 AI (虽然我认为 AI 只是其中一部分)。我们正逐步掌握如何开展大规模研究项目。要知道,直到最近,数学研究还停留在“案例分析”阶段——先攻克一个难题,花几个月时间完成报告,然后转向下一个课题。但现在我们开始采用“调查研究”模式,能够同时处理数百甚至数千个问题。
我们或许无法解决所有问题,但我们可以收集有关这些难题群体的各种有趣数据。我们正开始突破数学博士群体的局限,扩大参与范围。“公民科学”正在其他学科领域蓬勃发展,而数学领域的“公民数学”才刚刚起步。
虽然目前还处于萌芽阶段,但我们正逐步摸索如何正确运用机器学习和 AI 来解决问题。虽然我们发现许多错误的 AI 应用方式,但这些工具的实用价值正逐渐显现。其中有个关键要素让这一切成为可能——形式化验证。
形式化验证是一种特殊的计算机语言,简单来说,它能自动处理数学论证并验证其正确性。这种技术能大幅减少干扰因素,有效过滤掉那些曾阻碍新型工作流程发展的“糟粕”。
举个例子,我今天只能在演讲中分享一个半案例。
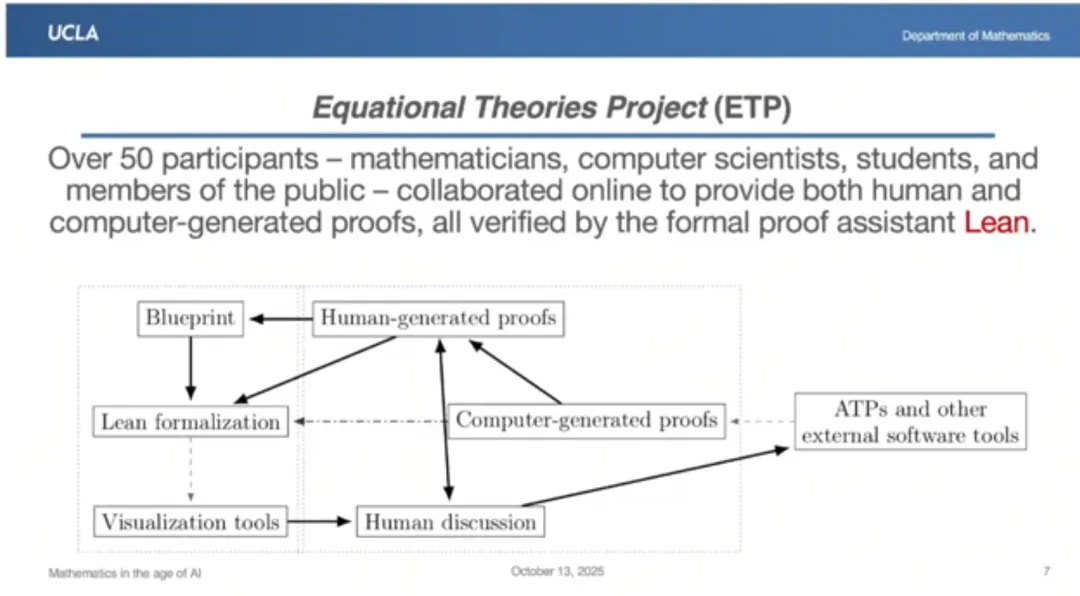
第一个案例是去年我在加州大学洛杉矶分校启动的“方程理论项目”,这个项目是我与 50 位合作者共同完成的。其中大部分伙伴都是通过这个项目结识的,之前我都没见过面。而且他们中的大多数并不是专业数学家。很多计算机科学家、学生、研究生、本科生,甚至一些高中生都参与了这个开放的协作项目。
这个代数研究项目的具体内容我暂时不便透露,但是我们通过程序生成了 2200 万个代数问题。比如典型问题就是:交换律是否蕴含结合律?如果有一个运算,使得 a*b 等于 b*a,你能推断出 a*b*c 等于 a*b*c 吗?结果表明答案是否定的。
但是我们生成了 2200 万个这类问题。任何一个具体的问题,也许一个代数专业的研究生可以花一个小时就能判断对错。但问题数量高达 2200 万个,我可没有 2200 万研究生。有人会说:“让我们众包吧”,“开放平台让公众参与”。但要处理 2200 万道代数题,这根本没人能搞定。我也没时间处理。
所以这类项目在过去根本无法实现。比如之前文献里提到的同类项目,最多也就研究过 20 道题。但这次涉及 2200 万道题,完全不是一个量级。
不过我们居然在三个月内完成了这个项目。对于每个命题,我们都有对应的证明或反证,来证明它是真是假。
为此我们不得不发明一些新的工作流程:
我们在 GitHub 上搭建了大型储存库,所有证明都必须用标准化语言“形式化”,这样才能实现自动化验证。我们使用了 Lean 这个证明辅助语言。
我们搭建了活跃的讨论区,这里既有人工生成的证明:有人会从 2200 万条推论中随机选取一条进行验证并发布,其他人则会尝试复刻这些成果。
研究人员会运行计算机程序,尝试解决全部 2200 万个问题,他们的程序每次最多能处理 10 万个问题。
团队成员会反复调整,将人类证明转换为计算机证明,或将计算机证明转换为人类证明。这种反复调整的过程我们算是即兴摸索出来的,但效果确实非常显著。
我认为这个项目成功有几个关键因素:
1.高度模块化设计
系统本身就被拆解成 2200 万个相关问题,研究人员可以针对其中的某个子集展开专项攻关。或者说,有些人会专门撰写人类可读的证明文件,而另一些人则会专门将这些证明转化成计算机可读的证明。你不必事无巨细地了解项目每个环节,完全可以专注于某个特定领域。这就像现代软件开发项目中的分工协作模式。
2.明确的评估标准
另一个关键优势在于我们制定了明确的评估标准。当项目设定目标并建立评分体系(比如损失函数)后,就能开始优化改进,这种机制为项目推进开辟了全新思路。
在项目进行到第 16 天时,系统显示存在 2200 万条关联数据。但实际上,我们早在第 16 天就解决了除 888 条之外的所有问题。随后团队会从这些数据中筛选出部分子集进行专项研究。这种机制让项目实现了自主分散化运作——参与者自发开展研究,若发现有效方案,就会为数据库新增解决方案,使剩余问题数量持续减少。整个团队就这样不断推动项目进展。
有些想法让这个数字大幅下降,有些则不太成功,不过我们不需要像传统项目那样协调配合——你知道的,大家各司其职。虽然我们进行了任务分配,但参与者们也自发地展开了许多独立活动,这过程其实挺有意思的。
3.形式化验证打破信任壁垒
最后我提到的秘诀是形式化验证,关键在于它能打破信任壁垒。
以前在数学领域,如果你想和其他人合作,要么你必须检查他们提交的每一行内容,要么你必须相信他们拥有足够好的声誉,相信他们的工作质量足够高,值得被纳入你的论文中。但是我们收到了来自各种各样的人的投稿,这些人我们从未见过。但是所有贡献都必须经过这种形式化验证,所以我们可以接受匿名或不受信任的贡献。
而且,这种验证方式确实能带来极其精确的讨论。比如有人尝试验证某个证明(比如人工验证),然后将其转换为Lean 代码。假设这个证明包含九个步骤,其中八个步骤都能正常运行,但最后一个步骤存在形式化问题。这时可以与原作者进行深入讨论,针对这个需要特别说明的微步骤进行澄清。这种讨论虽然不需要 BLE 工具,但通常需要耗费大量时间来规范符号体系和通用术语。
有时候人们可能不太明白,如果不能具体说明某个步骤,为什么你会卡在这个环节。但这些编程语言支持极其精确的技术讨论,甚至能细化到原子级层面。而且你不需要完全理解整个项目就能推进工作。