13万行代码——大事正在发生可遥笔记
在终端里敲下 python run_research.py 600519.SS --8phase,按下回车。
屏幕上开始滚动日志。研究定向智能体启动,分析贵州茅台的行业结构,识别竞争对手。数据采集模块同时从三个数据源抓取数据——十年财务报表、12个季度的电话会议记录、管理层讨论与分析、风险因素。综合分析模块把海量原始数据整理成结构化研究笔记。四个分析智能体同时启动——行业、财务、基本面、竞争对标——各自独立工作。
大约40分钟后,终端安静了下来。一次运行消耗了大约300万个词元(token)。
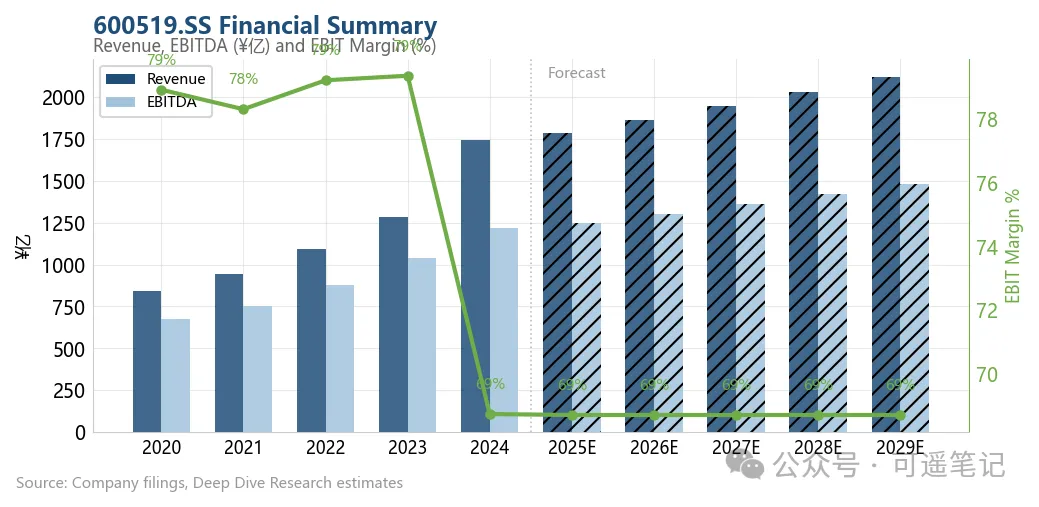
输出文件夹里多了十几个文件:一份完整的价值投资备忘录(中英文双版本PDF),8张《经济学人》风格的分析图表,一个包含三张报表五年预测的Excel模型——现金流折现估值、可比公司分析、敏感性分析、情景管理。Excel里的每一个数字都是公式,报表之间自动勾稽。
系统自动生成的财务概览图表
167个代码文件,超过13万行。我一行都没有写。
我愣在那里看了很久。不是因为技术上多么了不起——这个系统还非常非常粗糙——而是一种很朴素的快乐:这个东西是我做的,它真的跑起来了。
第一次用上Claude Code的时候,感觉看到了一道闪电。核心体验是:作为一个从未系统学过编程的人,我第一次借助AI工具做出了能跑的软件项目,进入了一种纯粹的心流状态——清晰的目标、即时的反馈、挑战与技能的匹配——创造力被释放的那种快乐。
一年多以前,大约2024年底,我就有一个想法:能不能用AI搭一套系统化的公司估值工具?做了近二十年PE投资,对公司研究的方法论很熟悉——波特五力、安全边际、护城河分析、估值框架——这些东西我闭着眼睛都能讲,但都还是手艺活。我知道该怎么分析一家公司,但好奇是否有办法把这套方法论"固化"成一个可重复执行的系统。
我一直对如何将新技术结合到传统的估值实践中很感兴趣。前段时间写过两篇关于Shortcut.AI的文章——那是一个AI驱动的财务建模工具,当时我用它和Kimi的多智能体对比着给苹果做了一套财务模型,还把谷歌NotebookLM的深度研究功能接进来做研究层。结论是AI在财务建模上已经能做到及格水平,但离真正的买方研究还有距离。不过Shortcut.AI有点像一个黑箱,自己不能完全控制其中所有细节。我好奇的是:如果不依赖现成工具,而是从零搭一个更完整的系统,能走到多远?
试过用ChatGPT拼代码,能跑的片段有,但要把几十个模块组装成一个完整的系统——模块之间怎么传数据,异常怎么处理,执行顺序怎么协调——这些工程问题超出了我的能力。试了几次就搁置了。
2025年初,Anthropic发布了Claude Code,风靡一时。在我看来,它像一个全天候在线的工程师搭档。我负责投资逻辑和方法论,它负责技术实现。积压了一年多的想法终于可以动手了。当然还有一层动机——一直听说Claude Code很强,手痒,想用一个有实际复杂度的小项目来亲身理解AI agent真实的能力边界。光看别人的评测不过瘾,绝知此事要躬行。
一个自动化的买方研究流程
这套系统叫"深度研究"(Deep Dive Research),核心是一个8阶段的价值投资研究流水线。对从业者来说,你们大概会觉得眼熟——这本质上就是我们做买方研究的标准流程,只不过写在代码里面了。
我先说结论:这个系统还非常非常粗糙,距离实际工作还有很大距离。但它能跑。给它一个股票代码,40分钟后吐出一套完整的研究报告、财务模型和分析图表,报表之间自动勾稽。
对我来说这就够兴奋的了。
1. 确定研究范围
在真实世界的买方研究中,这是分析师覆盖一家新公司的第一步——翻年报、判断行业结构、列出竞争对手、确定核心研究议题。在系统里,一个"研究定向"智能体自动完成这些工作。它调用Financial Modeling Prep(FMP)的数据接口获取公司基本信息和同行列表,同时调用SEC的EDGAR系统提取10-K年报中的Item 1A(风险因素)和Item 7(管理层讨论与分析),做初步的波特五力评估和护城河评级。
同时还有一个商业模式分类器,把公司归类到多种商业模式及行业之一——软件订阅、制药管线、工业、消费品牌、银行……每种原型配有校准过的行业阈值:ROIC的护城河判定标准、现金转换率的基准值、增长率的合理区间。后续所有的分析和校验都用这套行业特定的标准,不是一套通用模板套所有公司。
2. 数据采集
相当于分析师在彭博终端里拉数据、在FactSet里下载分部收入、在美国证监会EDGAR系统里翻文件的过程。系统从16个数据源接口同时抓取原始数据。
这是我个人的业余小项目,没有Bloomberg和FactSet这类付费终端的API接入。我自己付费订阅了FMP(financialmodelingprep.com)的数据接口来做平替——从这个接口拉取十年财务报表(利润表、资产负债表、现金流量表)、季度数据、分析师预测、目标价格、分部收入、公司基本信息(包括贝塔系数、市值、行业分类)。EDGAR客户端解析年报和季报文件中的管理层讨论和风险因素,还通过XBRL结构化数据填补FMP财务报表中的缺失字段。
对于中国市场,我写了三套专门的客户端:上交所客户端处理A股公告,港交所数据解析器处理港股年报,巨潮资讯网客户端抓取A股财务数据。这三套接口各有各的数据格式,各有各的坑——光是投资活动现金流这一个字段,FMP的接口里就有三种不同的拼法。
系统还对接了一个开源的中国市场数据库来获取A股的分部收入数据。有意思的是,这个数据库的收入口径跟FMP的利润表经常对不上——用了不同的收入定义。这个数据不一致的问题到现在还没完全解决。
3. 建模指引模板
传统的流程是先做研究再建模型。我最初也试着让AI按这个顺序走——先进行商业尽调和财务尽调,再做模型。但问题是:由于AI还不知道模型需要什么信息输入,所以尽调研究经常泛泛而谈,做了一堆工作但最后建模的时候发现关键假设没有数据支撑。
我反过来:先用历史数据生成一套大致的建模指引模板,包含50多个假设——营收增速用历史复合增长率估算,利润率用5年平均值,加权资本成本用资本资产定价模型自底向上计算。每个假设标注置信度:高置信度是能从利润表直接算出来的(当前毛利率、资本回报率),中等置信度是基于历史推算的,低置信度是需要尽调验证的(客户留存率、定价权、可寻址市场渗透率)。
然后把这些低置信度的假设按敏感性排名。"敏感性高但置信度低"的假设自动生成针对性的研究问题——不是泛泛地问"这家公司怎么样",而是精确地问"这家公司的获客成本在什么水平?管理层有没有在电话会议中讨论过定价策略的变化?"这些问题驱动后续的外部研究。
当这个逻辑第一次跑通的时候,我盯着那些精确对应模型假设的研究问题,有一种说不出的满足感。
4. 外部研究
相当于分析师做主动研究寻找洞察的环节——在真实世界里,这意味着专家网络的电话会议、行业研报、渠道调研。我的系统没有这些资源,它做的是网络研究——调用谷歌搜索和Kimi搜索(覆盖中文互联网),搜集最新的行业报告、公司新闻、竞品动态、监管变化。研究方向由上一步生成的问题驱动,不是漫无目的地搜集信息。
说实话,这一步跟真正的买方研究比差距很大。专家网络的一手访谈、渠道调研的微观数据、经销商的体感反馈——这些是网络研究替代不了的。不过即使是网络研究,也还有很大的提升空间。理论上可以接入专家访谈数据库,或者从小红书、播客、视频网站上去抓取相关信息。这些都是后续可以做的,理论上应该是可以解决的工程问题。
5. 数据综合
对应分析师阅读和消化原始材料的过程——翻完过去8个季度的财报电话会议记录,提炼管理层重点表态,标记分析师追问的核心问题,识别管理层语气的变化趋势。系统的综合Agent把前面抓回来的海量原始数据整理成一份结构化的研究笔记。
这一步还有一个电话会议解析器,专门解析财报电话会议的结构——提取管理层的营收指引、利润率预期、资本开支计划,把这些定性表态转化成可以与模型假设对照的结构化数据。
6. 关键驱动因素识别
这是买方研究中的一个核心环节——团队坐下来讨论:这家公司的损益表到底由什么驱动?是量还是价?哪个分部最重要?这通常需要分析师的行业经验和直觉判断。
系统的关键驱动因素智能体自动识别公司营收和利润的核心驱动因素。它先根据行业分类选择分解框架——对消费品公司用销量×均价,对软件订阅公司用用户数×单用户平均收入,对银行用净利息收入+中间业务收入——然后让大模型结合分部收入数据和电话会议记录,对每个驱动因素给出乐观/基准/悲观三种假设,每个假设附上证据出处和置信度评分。
坦率说,这个环节目前还比较机械,泛化能力不强。后面展开说。
7. 深度分析(四Agent并行)
对应买方研究的深度研究阶段——在对冲基金里,这可能是一份40-100页的研究报告。
四个分析智能体同时启动,各自独立工作:行业分析智能体用波特五力框架打分;财务分析智能体做杜邦分解、盈利质量检查(应计项目比率、现金转换率、应收账款增速与营收增速的比较)、计算巴菲特的"股东盈余";基本面分析智能体评估护城河类型(网络效应、品牌、转换成本、成本优势)和管理层资本配置能力;竞争对标智能体把标的公司和同行做逐项对比。
四个智能体共享一个研究上下文,各自往里写入发现,带置信度权重。
8. 价值投资框架评估
在真实世界中,每家基金都有自己的投资哲学筛选标准——这家公司符不符合我们的审美?在质量导向的长期持有型基金,这决定了一只股票能不能进观察名单。
系统用7个投资大师的框架做综合评估——格雷厄姆的安全边际(市净率2)、巴菲特的护城河和股东盈余、芒格的检查清单和永久资本损失风险、费雪的研发投入和市场份额趋势、卡拉曼的催化剂分析和下行保护、霍华德·马克斯的周期位置判断、格林布拉特的"魔法公式"(盈利收益率+资本回报率排名)。
这里有一个问题我后面会展开说——7个框架里有6个偏价值导向,对成长股的判断比较弱。
9. 尽调报告与模型落地
对应PE里的商业尽调和财务尽调报告,以及分析师把所有研究发现落实到模型假设的过程。
系统先生成商业尽调报告(市场分析、竞争格局、客户分析、护城河评估)和财务尽调报告(盈利质量分析、正常化利润基线、分部收入拆解、资本开支分析、营运资本趋势),然后用这些发现去升级第3步中低置信度的建模假设。