谷歌要重夺王座?晓静
2025年11月,谷歌发布的Gemini 3 Pro曾短暂封王,但很快就被OpenAI和Anthropic的新模型挤下了宝座。
AI世界的王座更替,比手机发布会还快。
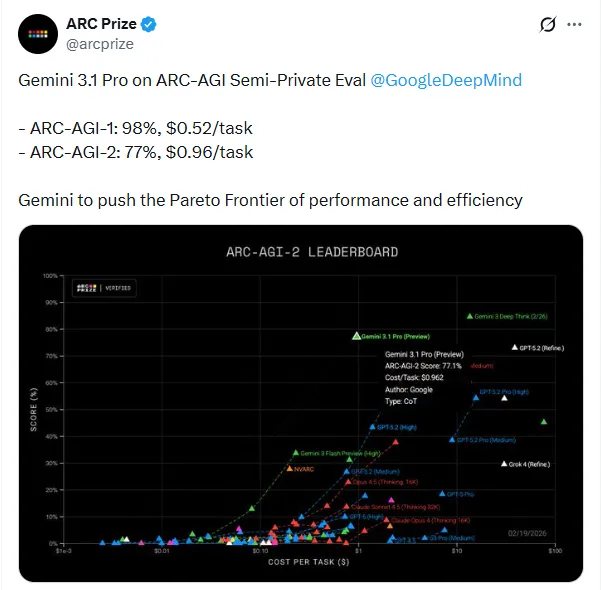
就在2026年2月19日深夜,谷歌带着名为“Gemini 3.1 Pro”的新模型杀了回来。官方数据看着挺吸引人:在一项衡量AI解决全新逻辑问题能力的“怪考题”ARC-AGI-2上,Gemini3.1 Pro的得分直接翻了一倍多,冲到77.1%。
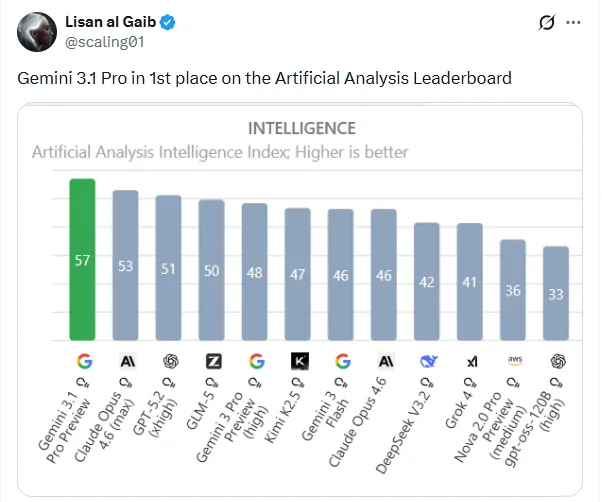
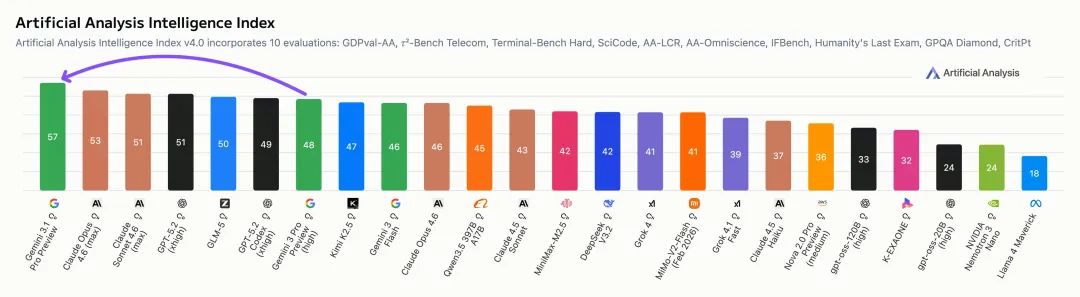
第三方机构Artificial Analysis的测试也显示,Gemini3.1 Pro的综合智能指数已经悄悄爬到了第一,把Claude Opus 4.6甩在了身后。
强调硬核推理、编码能力和成本控制,摆出一副要跟开发者和企业用户“务实合作”的姿态。
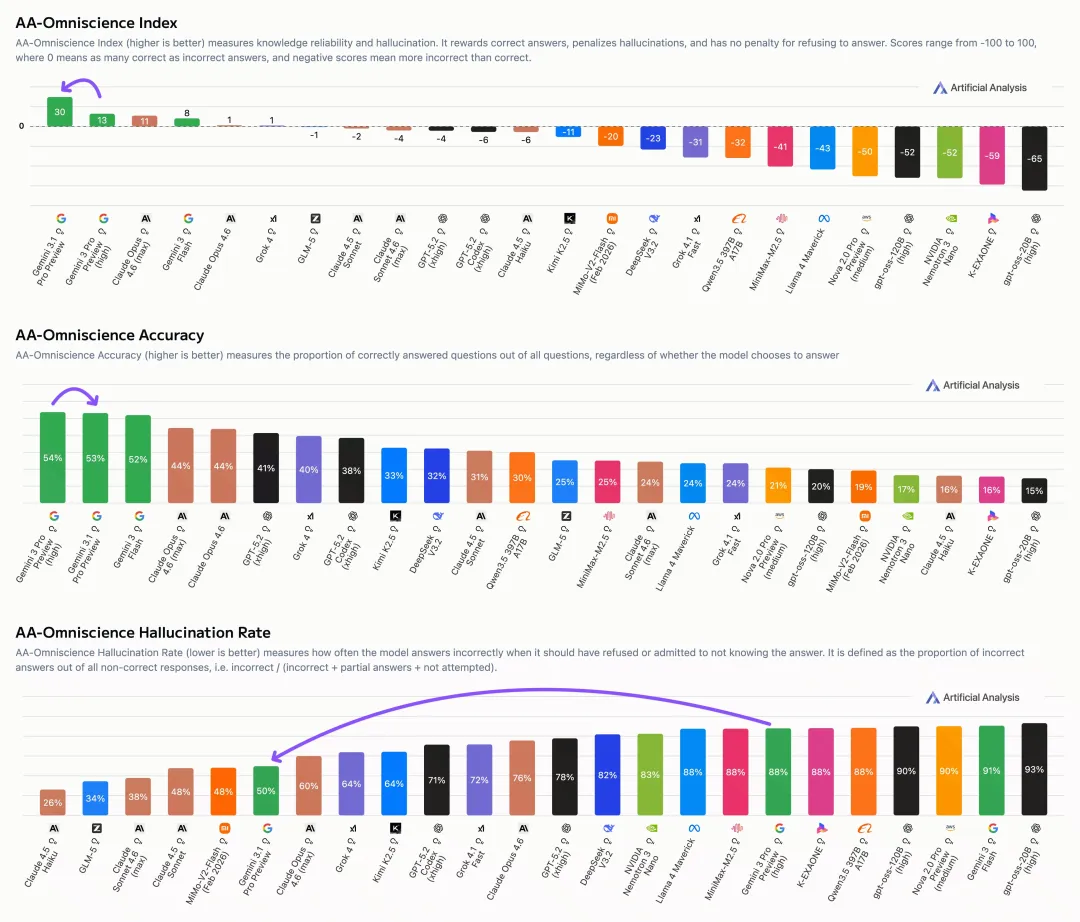
幻觉率继续降低,在测试模型是否“不懂装懂”的AA-Omniscience幻觉率上,Gemini3.1 Pro比前代模型大降了38%。
最关键的是,性能涨了,价格却没变。谷歌这次,似乎是铁了心要用“加量不加价”的策略,把丢掉的头衔再抢回来。
01 “三级思考”模式
之前的Gemini 3 Pro可能会让人觉得它够快、够强,但有时候答案还是有点“飘”。这次的Gemini3.1 Pro,谷歌把重点放在了“核心推理能力”上,换句话说,就是让它更会“动脑子”了。
这最直观地体现在名为ARC-AGI-2的测试里。这个测试考的不是死记硬背,全是些没见过的新逻辑题,专门用来检验AI真正的推理能力。
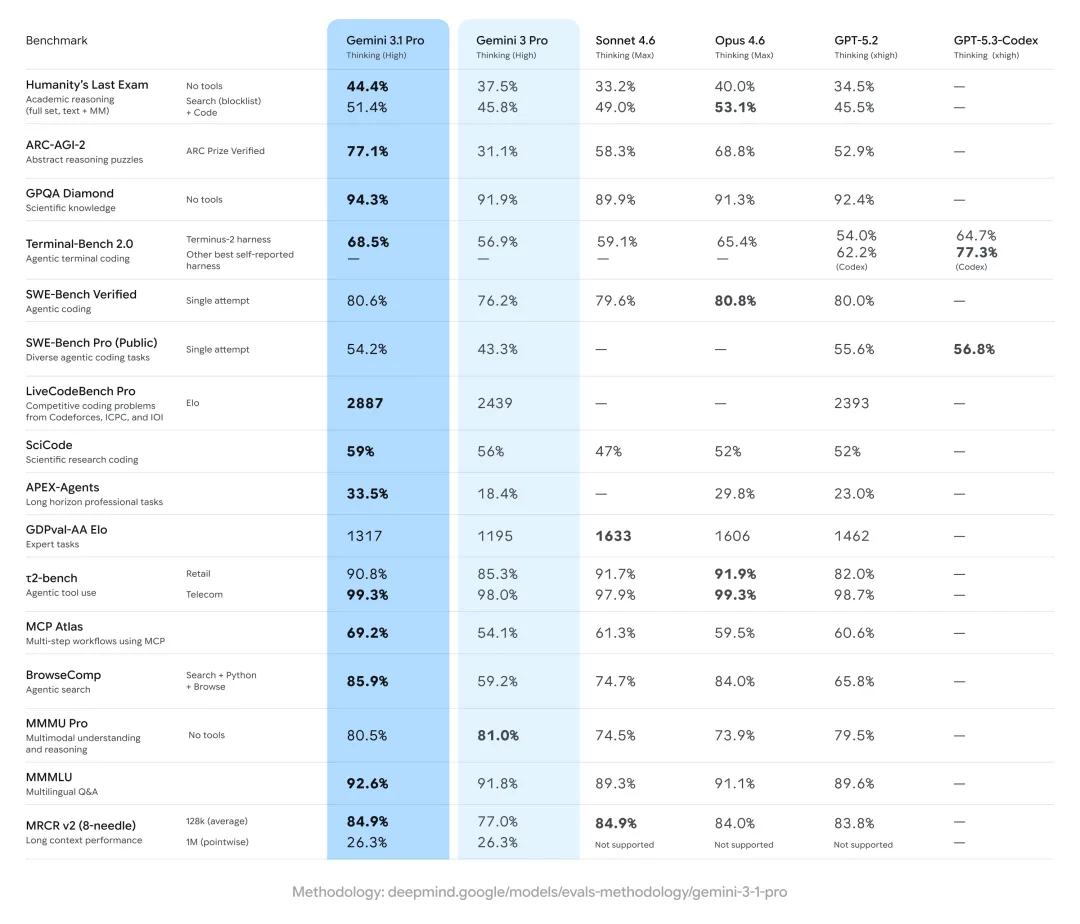
Gemini 3.1 Pro的得分在各项标准测试中均超越同类竞品
Gemini 3 Pro之前的得分是31.1%,而Gemini3.1 Pro一口气冲到了77.1%。谷歌DeepMind的老板戴密斯·哈萨比斯(Demis Hassabis)也特地发文说,这标志着模型在核心推理和问题解决能力上有了重大改进。
但真正的杀手锏,还不是得分。Gemini 3.1 Pro这次引入了一个“三级思考”模式——低、中、高。你可以把它理解为给模型装了一个可以调节的“算力旋钮”。简单说,就是用户可以根据任务难度,自己决定让模型花多少时间思考。
之前的Gemini 3 Pro只有两档:低和高。这次Gemini3.1 Pro在中间加了一档,同时调整了“高”模式的含义。调到高的时候,模型会进入类似Deep Think的状态。Deep Think是谷歌上周更新的推理模型,特点是花更多时间处理复杂问题。现在Gemini3.1 Pro自己就能做这件事,不用单独切换。
这个功能主要解决一个实际问题。以前开发者处理不同难度的任务,往往需要准备多个模型,简单对话用一个,复杂推理用另一个。接口不同,计费不同,还得自己写逻辑判断该调用哪个。时间长了,这套东西维护起来比较麻烦。
现在一个模型就够了。常规任务用低档,可以快速返回;复杂任务用高档,让它多花点时间处理。不用来回切换,也不用维护多个模型。
02 “抢王座”,跑分获胜
既然是来“抢王座”的,就免不了要和OpenAI的GPT-5.2、Anthropic的Claude Opus 4.6这些老对手掰掰手腕。
从纸面数据看,Gemini 3.1 Pro这次确实挺能打。Artificial Analysis的智能指数测试里,它在10项评估中拿下了6项第一,包括Terminal-Bench Hard(编码)、GPQA Diamond(科学知识)和Humanity's Last Exam(推理知识)。
在Artificial Analysis的智能指数测试中,Gemini 3.1 Pro吊打对手
尤其在测试模型是否“不懂装懂”的AA-Omniscience幻觉率上,Gemini3.1 Pro比前代狂降了38个百分点,这意味着它现在更清楚自己“不知道什么”,而不是瞎编一通。
在AA-Omniscience测试中,Gemini 3.1 Pro幻觉率大幅下降
在一项针对研究级物理推理问题的CritPt测试中,Gemini3.1 Pro更是拿下了18%的分数,比第二名的模型高出5个百分点以上。Artificial Analysis对此评价称,这表明谷歌这次在底层智能上确实下了狠功夫。
不过,AI圈的竞争从来不只是“考高分”。在更贴近用户体验的Arena排行榜上,情况就没那么一边倒了。
这个榜单靠用户给不同模型的回答投票排名,比的不是逻辑对错,而是谁的回答看起来更“顺眼”。目前,在纯文本任务上,Claude Opus 4.6依然领先Gemini 3.1 Pro 4分,在代码任务上,Opus系列和GPT-5.2也还保持着微弱优势。
Arena的排名可能会奖励那些回答“看起来正确”但未必真正正确的模型,而Gemini 3.1 Pro这次在减少幻觉上的进步,恰恰是为了追求“真正的正确”。
当然,也不是所有方面都完美。
虽然Artificial Analysis的数据显示,Gemini3.1 Pro在现实世界的智能体任务上有进步,得分从56.9%涨到了68.5%,但在这个领域,Claude Sonnet 4.6和GPT-5.2等对手依然跑在前面。
03 不只是编码,还能读懂《呼啸山庄》的“氛围”
跑分和排名终究是数字,Gemini 3.1 Pro到底能干什么?
最让人印象深刻的是它的“创意编程”能力。比如,让它为《呼啸山庄》设计一个现代风格的个人作品集网站。Gemini3.1 Pro不只是简单总结书的内容,可以“推理”出小说那种阴郁、狂野的氛围,然后把它转化成一个时尚、现代的界面设计。
另一个例子是3D交互。Gemini3.1 Pro能直接生成一段代码,创造一个复杂的3D欧椋鸟群模拟。你甚至可以用手去追踪和操控鸟群,鸟群飞舞的同时,还有根据它们运动变化生成的背景音乐。
来自初创公司Cartwheel的联合创始人安德鲁·卡尔(Andrew Carr)在试用后就发现,这个模型对3D空间变换的理解比之前强了一大截,以前做3D动画时老是搞错的旋转顺序问题,在Gemini3.1 Pro上居然被完美解决了。
对于普通用户来说,最实用的可能是生成动画SVG。以前你想做个网页小动画,可能要懂设计、会剪辑。现在,直接给Gemini 3.1 Pro一句描述,它就能生成一段纯代码构建的动画,不仅在任何屏幕上放大都清晰,文件还特别小。这被不少人看作是“氛围编程”的开始。
强大的推理能力还让Gemini3.1 Pro打破了复杂API与人性化设计之间的壁垒。谷歌展示的一个例子里,模型直接构建出一个实时的航天数据看板,完美接入公开的遥测数据流,将国际空间站的实时运行轨迹清晰地展现在你眼前,将一堆冷冰冰的数据接口变成了普通人也能看懂的交互界面。