OpenAI挑战最新First Proof:做了7天错了一半量子位
2/15/2026
在谷歌发布Gemini 3 Deep Think爆火后,OpenAI也开始放出新的能力信号。
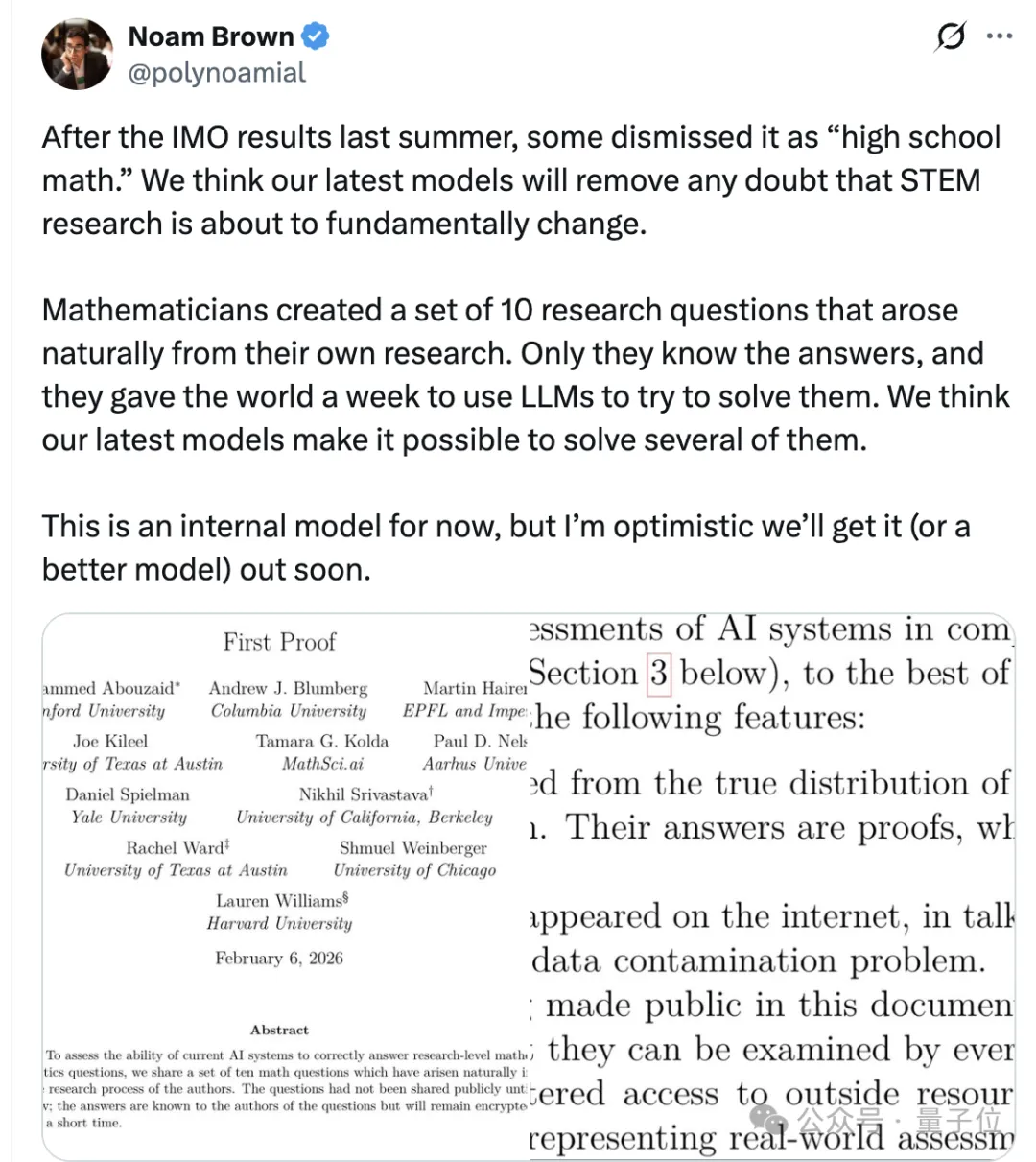
刚刚,OpenAI表示:他们用尚未发布的内部模型,在一周内尝试解答10道来自数学家科研现场的真实问题,其中有5道被认为基本正确。
值得一提的是,这批题目与此前GPT、Gemini等模型在IMO类测试中取得金牌成绩时面对的题目完全不同。
它们不来自标准题库,也不是竞赛题,而是直接取自数学家真实研究过程中的自然问题。
这在很大程度上切断了模型“背答案”或通过训练数据污染获得优势的可能性,从而意味着模型自主推理能力再次进化。
正如一位网友所说:
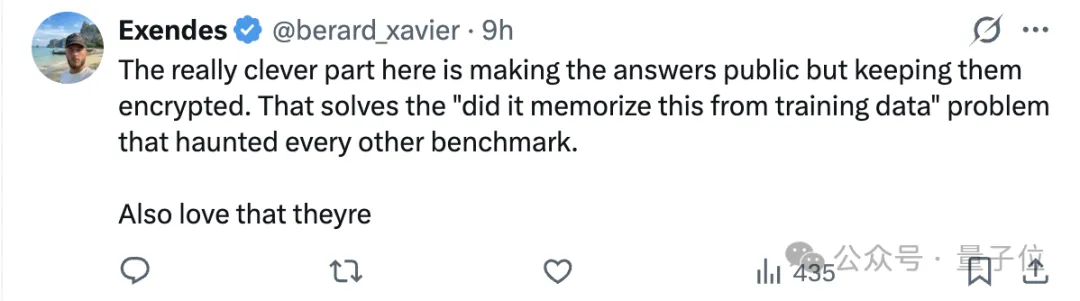
这里最聪明的地方,是把答案公开,但用加密的方式保存。这基本解决了困扰其他benchmark的老问题,模型是不是从训练数据里记住了答案。
此外,据称OpenAI研究员,o1核心贡献者Noam Brown表示:
这款内部模型很快就要发布了。
解决一半的真实数学问题
相信眼尖的你已经发现了:为什么图片里写的是6道,但正文却说是5道?
在早期评估中,确实一度认为模型做对了6道。
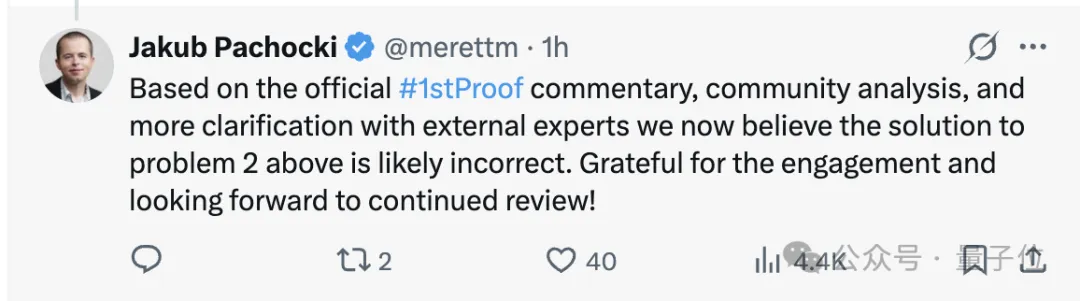
但随后在社区讨论与复核反馈中,第2题的解法被指出可能存在问题。
根据OpenAI的Jakub Pachocki的说法,第2题很可能是错的,因此更保守的估计应该在5道左右。
至于具体做对了哪些题,咱们先看这次测试本身是如何进行的。