GPT-5.3上线Codex量子位
火星撞地球,新模型大战!
Claude Opus 4.6发布仅仅15分钟,OpenAI也甩出了自己最新最强编程模型——
GPT-5.3-Codex。
最直观的感受是,这个新模型终于有点美学品味了。
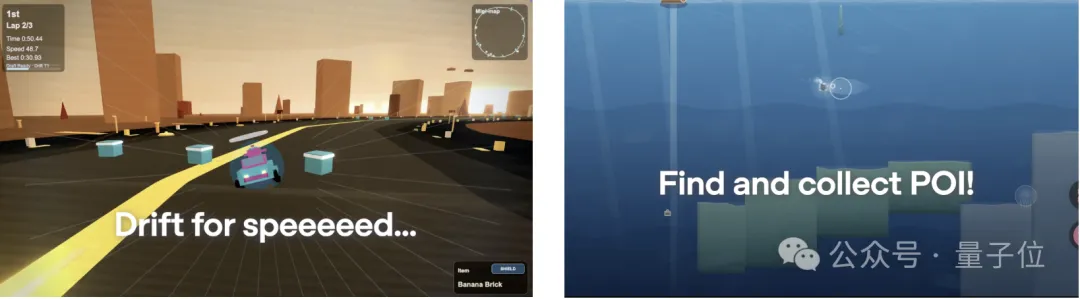
官方展示了两个Demo:一个赛车游戏、一个潜水游戏。还蛮有风格的。
据说,GPT-5.3-Codex在几乎没有人工干预的情况下,持续迭代这些游戏,累计消耗了数百万token。
在网页开发上,除了UI更好看,对「意图」的理解也更强了。
即便Prompt给得不清楚,它也能自动补全逻辑,生成一个功能齐全的网站。
就这些Demo来看,设计感确实比之前强了一截。
Computer use能力同样拉满,现在已经能用来帮金融从业者直接做PPT。
其他职场工作也能覆盖,尤其是在专业知识密集型任务上,写文档、做电子表格都没什么问题。
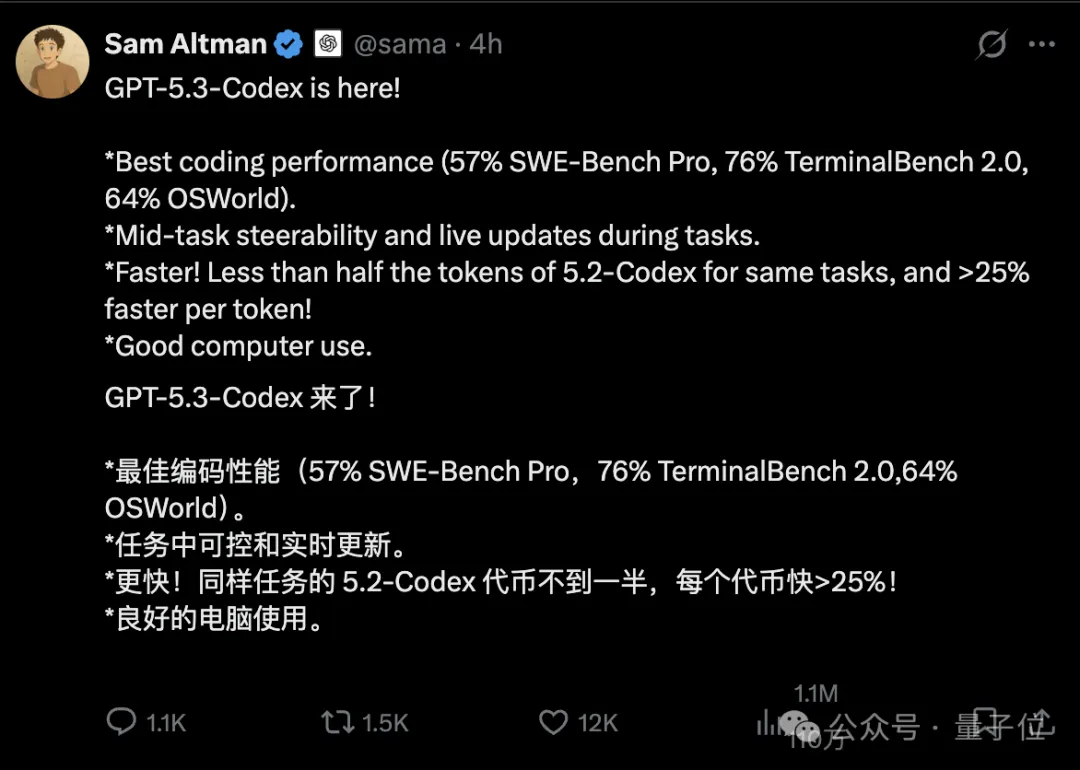
硬实力方面,官方给出的亮点如下:
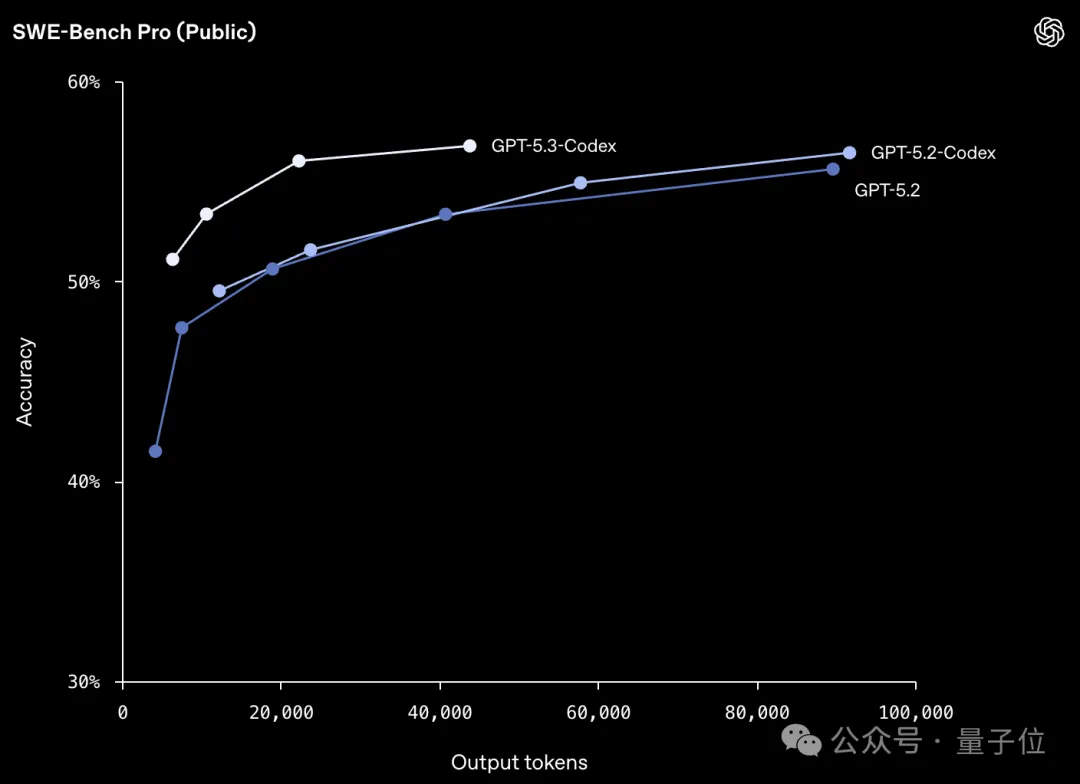
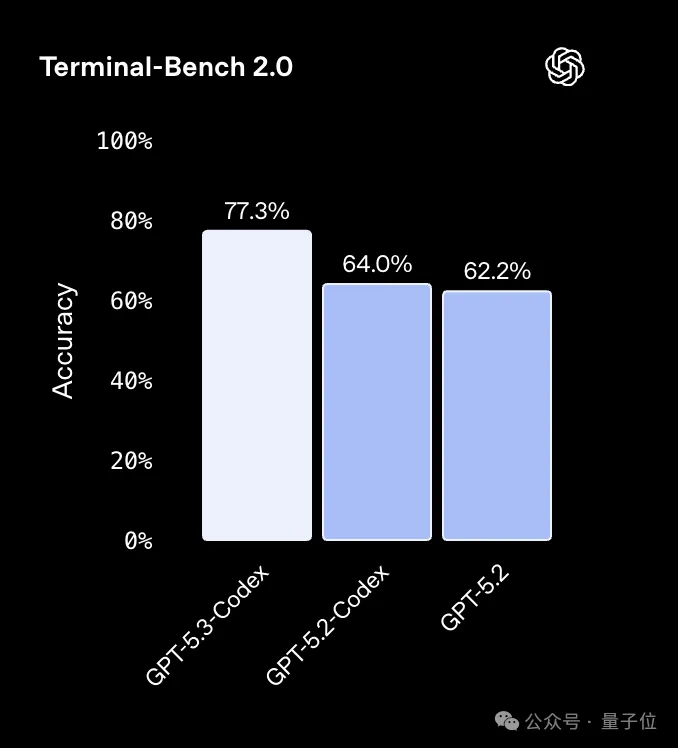
更聪明:SWE-Bench Pro 57%,TerminalBench 2.0 76%,OSWorld 64%。
更可控:支持任务进行中的实时引导,可随时调整方向并获取更新。
更快速:完成相同任务时,所需token不到5.2-Codex的一半,单token速度提升超过25%。
更Agent:不只是更会写代码,计算机操作同样很强。
直接看这张对比表会更直观,几乎每一个维度,都比上一代有明显提升。
网友直呼过于刺激,昨天OpenAI刚被Anthropic拿广告狙了一枪,今天就对轰了回来。
一天之内,两个重量级编程模型。
评论区也迅速分成了Anthropic派和OpenAI派。
下面来看看,这场奥特曼主动挑起的AI coding大战,OpenAI到底表现如何?
GPT 5.3 Codex
大家最关心的,当然还是编程能力。
OpenAI表示,GPT-5.3-Codex在SWE-Bench Pro上实现了SOTA。
这是一个专为真实世界软件工程设计的测试,覆盖四种编程语言,整体难度更高、任务更丰富,也更贴近真实生产场景。
同时,GPT-5.3-Codex在Terminal-Bench 2.0上的表现也有明显提升。
更关键的是效率。在拿下这些成绩的同时,GPT-5.3-Codex使用的token数量少于任何以往模型。