马斯克罕见低头:X推荐算法“很烂”量子位
就现在,GitHub已经能完整看到马斯克开源的𝕏推荐算法系统了。
开源文件里明确表示,这是一个几乎完全由AI模型驱动的算法系统。
我们移除了所有人工设计特征和绝大多数启发式规则。
消息一出,整个社区立刻沸腾了,最高赞上去就是一顿猛夸:
incredible!没有其他平台能做到如此透明。
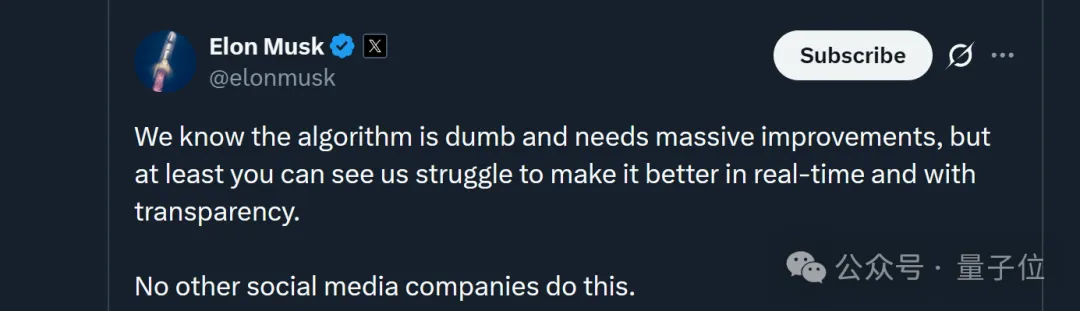
马斯克本人也火速转发了𝕏工程团队原帖,不过一向言辞高调的老马,此番却低调表示:
我们知道这个算法很蠢(dumb),需要大幅改进,但至少您可以实时、透明地看到我们为改进它而努力。
其他社交媒体公司都没有这样做。
早在2022年收购𝕏(原Twitter)之前,马斯克就多次批评该平台过于封闭。
自收购之后,他也兑现承诺多次公开Twitter核心推荐算法,这一次也算是不忘初心了。
原来纯AI驱动的推荐系统,是这样运作的!
话不多说,咱这就扒一扒整套系统的运作机制。
一句话概括这个系统即为:
基于Grok-1同款Transformer架构打造,能通过学习你的历史互动行为(点赞/回复/转发过什么),来决定给你推荐什么内容。
从用户打开“For You”开始,客户端会向服务器发送一个请求,触发整个算法流程。
然后系统会先做一件事——搞清楚你是谁、你最近在干什么、你平时对什么内容有反应。
为实现这一目的,系统会拉取两类用户信息:
行为序列(Action Sequence):一类代表最直接、最强烈的兴趣信号,比如最近点赞、回复、转发、点进、停留过什么。
属性(Features):另一类代表长期属性,比如关注列表、声明的兴趣主题、地理位置、使用设备等。
这一步的目标并不是人工构造特征,而是尽可能真实地构建“实时用户画像”——
以前工程师可能会假设“某些属性很重要”,然后手动编写规则或公式去计算一个“用户兴趣得分”。
但这本质上是工程师的猜想,而非用户真实状态的反映。
于是马斯克的这套算法就决定不做任何预设假设,而是尽可能多地、原始地收集用户最真实的行为反应,然后将这堆数据直接喂给后续的模型,从而让模型自己去从原始数据中学习和发现规律。(即“去人工化”和“端到端”)
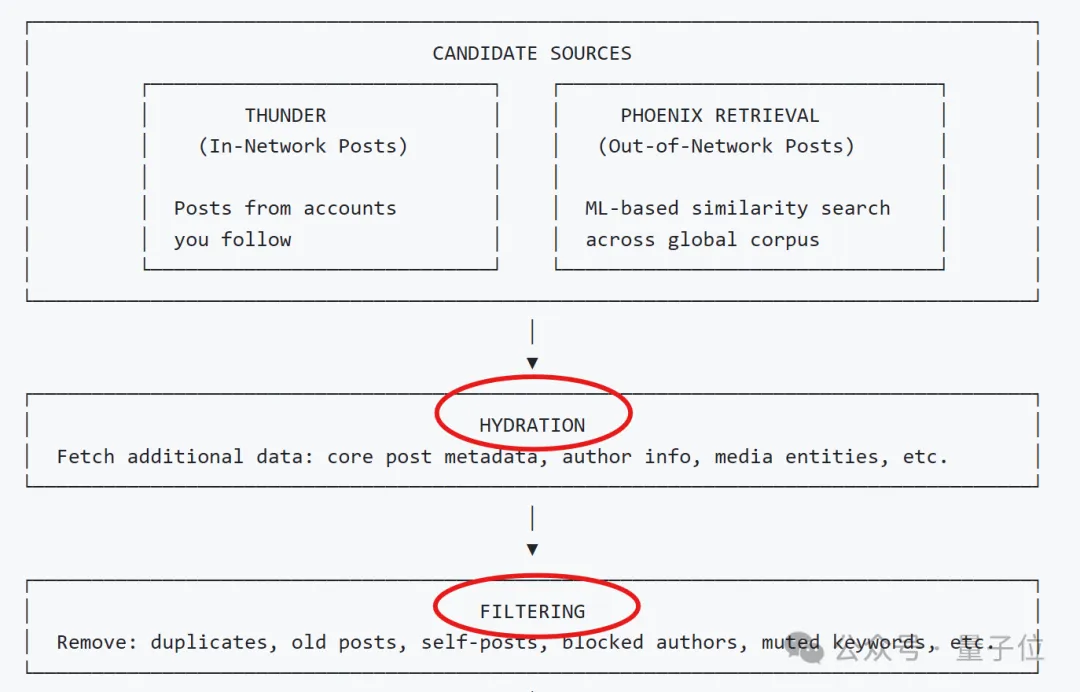
而拿到实时用户画像后,系统会接着兵分两路,从整个平台的海量推文中快速筛选出几千条“可能相关”的推文。
一条是通过熟人圈。即从Thunder模块,直接抓取你关注的所有人的最新推文。
另一条是通过外部。利用Phoenix Retrieval这一核心检索模块,抓取那些你可能感兴趣、但来自未关注账号的推文。
以上两类来源不同的信息,会在后续阶段被统一对待。
需要提醒,此时筛选出来的还只是推文ID。
于是系统会通过Hydration模块,补全每条候选推文的信息,包括推文全文、作者详情、图片/视频、历史互动数据等,以便后续深度评估。
而且在正式开始计算前,还会进一步通过Filtering模块淘汰那些明显不要的内容,例如:
重复或过期的帖子
用户自己发布的内容
来自拉黑或静音账号的帖子
包含用户屏蔽关键词的内容
已经看过或在当前会话中展示过的帖子
用户无权限访问的订阅内容
记住,这一步只做一件事:回答某条内容“能不能出现,而不是值不值得推荐”。
铺垫到这里,最终剩下来的内容会被逐条送入Phoenix排序模型进行打分。
这个模型是一个基于Transformer的模型,它会同时接收:
用户的行为序列与属性信息
单条候选帖子的内容与作者信息
然后模型会预测用户对某条推文执行各种操作的概率,并将各种概率按照预设权重进行加权组合(如点赞类正向行为加分、拉黑类负向行为减分),并形成最终排序分数。
基于此,系统还会进行少量工程层面的调节——
比如控制作者多样性,避免单一账号在信息流中占据过高比例(防止某一大V刷屏)。
这里也需要提醒,为了保证送入的每条帖子都是独立评分的,所以系统还特意设置了“不允许候选帖子相互看见”(推文之间没有交叉注意力机制)。
所有候选帖子按最终得分排序,系统从中选出Top-K条帖子,作为本次请求的推荐结果。
而且在返回客户端之前,系统还会进行最后一轮校验,确保内容符合平台安全规范——
例如,移除任何已删除、被标记为垃圾信息或包含暴力血腥等违规内容的推文。
最终,经历重重筛选后的信息会根据分数高低,依次展示给客户端用户。