MIT:递归智能,AGI 的前夜?波动智能
过去几周,硅谷的空气里弥漫着一种难以言说的紧张感。三家顶级实验室几乎在同一时间向内部团队发出了类似的警告,他们的模型出现了“未经编程的能力”。
这些能力不属于训练目标,不属于数据分布,甚至不属于任何人类设计的范畴。有人形容这种现象像是在“空无一人的房子里发现脚印”——你不知道它从哪里来,也不知道它下一步会走向哪里。
这种“递归智能”的迹象让整个行业开始重新审视一个被忽略已久的问题,递归能力,正在成为下一代LLM的真正战场。
过去一年,大模型的上下文窗口从 32K、128K,一路飙升到 200K、1M,甚至出现了号称“无限上下文”的模型。但窗口变大并不意味着模型真的能理解这些内容。越来越多的证据显示,模型在面对超长输入时会出现一种被称为“上下文腐烂”(context rot)的现象,输入越长,模型越迷糊,越容易忘记前面的信息,越难保持推理链条的稳定性。
这不是算力问题,也不是训练规模问题,而是 Transformer 架构本身的结构性限制。注意力机制在百万级 token 面前会迅速稀释,模型的有效注意力范围远小于它的物理窗口。换句话说,你给它一本百万字的书,它最多只能认真读前几章。
于是业界开始尝试各种补丁式方案, 有人用长上下文训练硬撑; 有人用压缩、摘要、滑动窗口来“挤”信息; 有人用检索增强(RAG)来“查字典式”访问内容。
但这些方法都有一个共同的问题,它们假设模型是被动的。模型只能等着人类把信息整理好、切好、喂好。
而真正的智能,不应该是这样的。
麻省理工学院的计算机科学与人工智能实验室MIT CSAIL 的 Alex L. Zhang、Tim Kraska 和 Omar Khattab提出了一个颠覆性的想法,为什么不让模型自己去读?自己去查?自己去切片?自己去调用自己?
于是,Recursive Language Models(递归语言模型RLM)诞生了。
RLM 的核心洞察非常简单,却极具革命性,把上下文从“输入”变成“环境”。
模型不再被动接收一长串 token,而是像程序一样,在一个 REPL 环境中把整段上下文当作变量,随时可以查看、切片、搜索、过滤、递归调用自己。 它不再是“被喂信息”,而是“主动探索信息”。
这就像从“给你一本书,你读吧” 变成了 “给你一个图书馆,你自己查、自己拆、自己总结、自己调用助手”。
这不仅绕开了 Transformer 的上下文限制,更让模型第一次拥有了“程序化访问世界”的能力。
麻省理工学院的计算机科学与人工智能实验室(MIT CSAIL)是由 MIT 的 AI Lab 与 LCS(计算机科学实验室)在 2003 年合并而成。它是全球计算机科学、人工智能、机器人学、系统与理论研究的核心力量之一。Kraska 是数据库系统与 ML 系统领域的顶尖人物, Khattab 是 RAG、DSPy、ColBERT 等推理系统的核心作者,Zhang 则是系统实现与推理框架的主力研究者。
他们把系统工程、检索推理、程序化智能三条线合在一起,造出了一个真正意义上的“递归智能框架”。
研究背景:长上下文任务的真实挑战
如果说 RLM 是一种“新范式”,那它要解决的问题其实非常朴素,现代LLM在长上下文任务上表现得远比我们想象的糟糕。
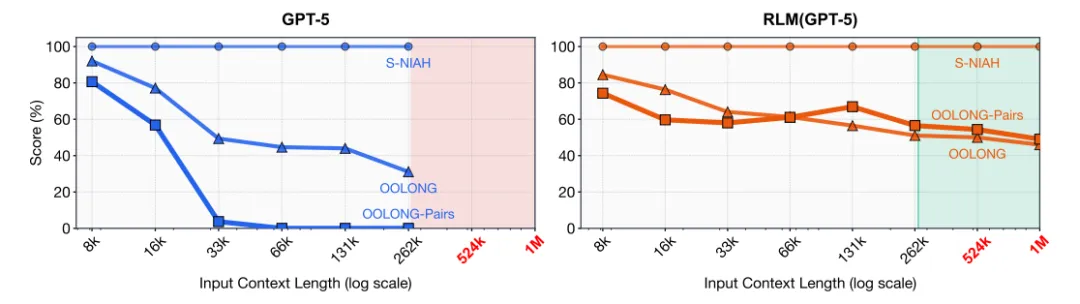
当上下文长度从 10K、50K、100K 一路扩展到百万级,模型的性能不是线性下降,而是断崖式崩塌。研究中引用了 GPT‑5 的实验结果,在百万级上下文下,模型几乎无法维持任何有效推理,甚至连简单的needle-in-a-haystack 都会出现错误。
图1:GPT-5和相应的RLM在三个复杂度不断增加的长上下文任务上的比较:S-NIAH、OOLONG和OOLONG对。对于每个任务,我们将输入长度从2.13缩放到2.18。GPT-5的性能随着输入长度和任务复杂度的增加而显著下降,而RLM则保持了很强的性能。超出红色区域的输入不适合GPT-5的272K令牌上下文窗口,但RLM有效地处理了它们。
更糟糕的是,任务复杂度与上下文长度之间存在双重耦合。 不是所有任务都一样,有些任务对上下文的依赖是指数级的。
研究团队将任务分成三类。
第一类是常数复杂度任务,比如 S‑NIAH。 无论上下文多长,你只需要找到一个 needle。 模型只要能扫描到关键片段,任务就能完成。
第二类是线性复杂度任务,比如 OOLONG。 每一行都可能影响最终答案,信息密度高,模型必须“读完整本书”。
第三类是二次复杂度任务,比如 OOLONG‑Pairs。 不仅要读完整本书,还要对每一对条目进行组合推理。 信息量呈平方级增长,模型几乎必然崩溃。
这些任务共同揭示了一个残酷事实,模型不是不能处理长上下文,而是不能结构化地访问长上下文。
Transformer 的注意力机制本质上是一种“全局广播式”机制,它没有指针、没有索引、没有随机访问能力。 面对百万级 token,它就像一个只能从头读到尾的读者,既不能跳页,也不能查目录,更不能做笔记。
这就是为什么“更大的窗口”不是答案。 你可以把窗口扩到 10M,但模型依然无法有效利用它。
真正的突破必须来自一种新的思维方式, 让模型像程序一样访问上下文,而不是像读者一样被动阅读。
这正是 RLM 的起点。
递归语言模型方法论
RLM到底是怎么做到的?
为什么它能让 GPT‑5 在百万级上下文里依然保持清醒?为什么它能让 Qwen3‑Coder 在 OOLONG-Pairs 这种信息密度爆炸的任务里不至于直接昏厥?为什么它能把“长上下文”这个行业公认的死结,拆成一个个可控的小问题?
答案藏在一个看似朴素、但极具颠覆性的范式里,LLM × REPL ×递归。
RLM的基本范式,LLM × REPL ×递归
传统 LLM 的工作方式很简单,你把一大串 token 塞进去,它在一次前向推理里给你一个答案。 但当上下文长度突破几十万、几百万时,这种方式就像让一个人一次性读完《战争与和平》再回答问题——不崩溃才怪。
RLM 的做法完全不同。
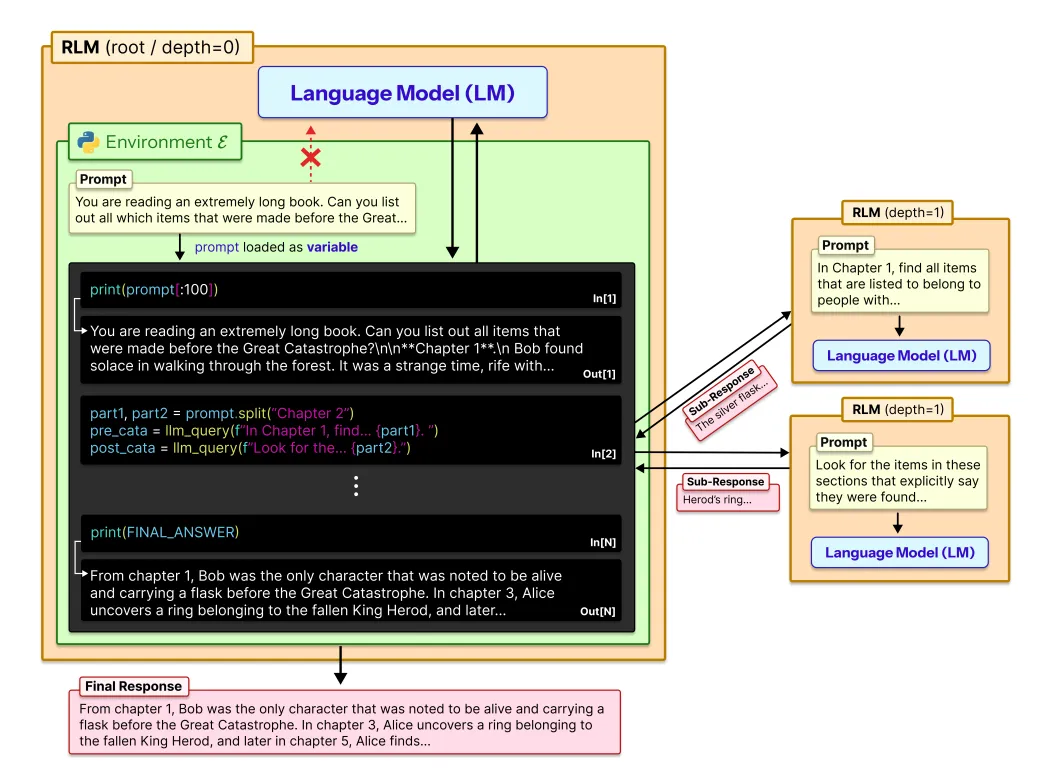
它把整个长上下文加载进一个 Python REPL 环境,作为一个变量,比如 context。 模型不再直接“吃掉”这些 token,而是像一个程序员一样,写代码去访问它们。
这意味着模型第一次拥有了“工具”。 它可以:
查看局部片段:print(context[:500])
搜索关键词:re.findall("festival", context)
按章节切分:part1, part2 = context.split("Chapter 2")
构造子任务:sub_answer = llm_query(f"请总结{part1}")
甚至递归调用自身:result = rlm_query(sub_prompt)
这就像给模型装上了“手”和“眼睛”。 它不再是一个被动的语言生成器,而是一个能主动探索、主动拆解、主动规划的智能体。
研究里的示例非常形象, 模型会先打印前 100 行看看结构,再决定怎么切片; 会用关键词过滤出可能相关的段落; 会把任务拆成多个子问题,再递归调用自己去解决。
这不是 prompt engineering,这是program engineering。
图2:递归语言模型(RLM)将提示视为环境的一部分。它将输入提示符作为变量加载到Python REPL环境E中,并编写代码,在变量的编程片段上递归地窥视、分解和调用自己。
程序化上下文访问,从“序列输入”到“随机访问”
Transformer 的最大弱点之一,就是它只能“顺序读”。 即使注意力机制允许它“看全局”,但在百万级 token 面前,这种注意力会迅速稀释,位置编码也会失效,导致模型根本无法保持对远距离信息的敏感度。