梁文锋署名:直击Transformer致命缺陷新智元
深夜,梁文锋署名的DeepSeek新论文又来了。这一次,他们提出全新的Engram模块,解决了Transformer的记忆难题,让模型容量不再靠堆参数!
刚刚 ,DeepSeek新论文发布了,梁文锋署名!
这一次,他们联手北大直接瞄准了「记忆」,是Transformer最致命的关键难题。
如今,MoE成为大模型主流架构,但本质仍是Transformer,因其缺少原生「知识查找」机制,很多检索能力被迫用大量计算去模拟。
33页论文中,团队提出了 MoE 互补的「条件记忆」稀疏轴,并通过一种全新的Engram模块去实现:
将经典哈希N-gram嵌入现代化,提供近似O(1)的确定性知识查找。
论文地址:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
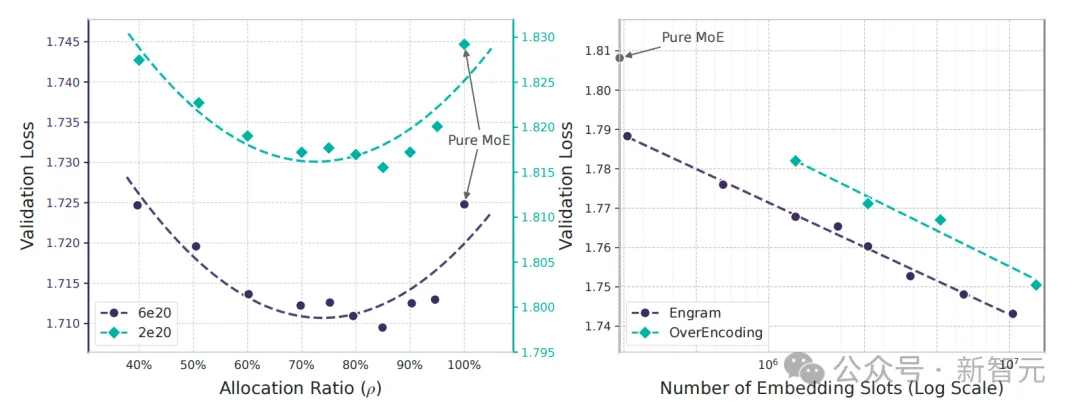
通过「稀疏分配」(Sparsity Allocation)建模,他们意外发现MoE与Engram之间,存在「U形scaling law」。
这意味着,需调整两者之间资源比例,让计算与静态记忆间找到最优权衡。
沿着这个规律,将Engram扩展到27B参数后,并在严格等参数、等FLOPs下优于MoE基线。
直白讲,MoE只解决「怎么少算」,Engram直接解决「别瞎算」。
它把该查的交给 O(1)记忆,把注意力从局部琐碎中解救出来,结果不只是更会背知识,同时推理、代码、数学一起变强。
这可能成为稀疏LLM下一条主流路线,更重要的是,下一代V4或将集成这一新方法。
不再苦算,给Transfomer插入「电子脑」
当前,LLM越做越大已成为「铁律」,一条熟悉的路径是——把参数做大,把计算做「稀疏」。
混合专家模型(MoE)就是典型代表,每个token只需激活少量专家,用「条件计算」让参数规模飙升,FLOPs还能控住。
从Artifical Analysis榜单中可以看出,现有的稀疏大模型,主流都是MoE。
但问题在于,Transformer缺少一种「原生的知识查找」能力,所以很多本该像检索一样 O(1)解决的事,被迫用一堆计算去「模拟检索」,效率很不划算。
北大和DeepSeek新论文带来一个很有意思的观点:稀疏化不只服务「计算」,也可以服务「记忆」。
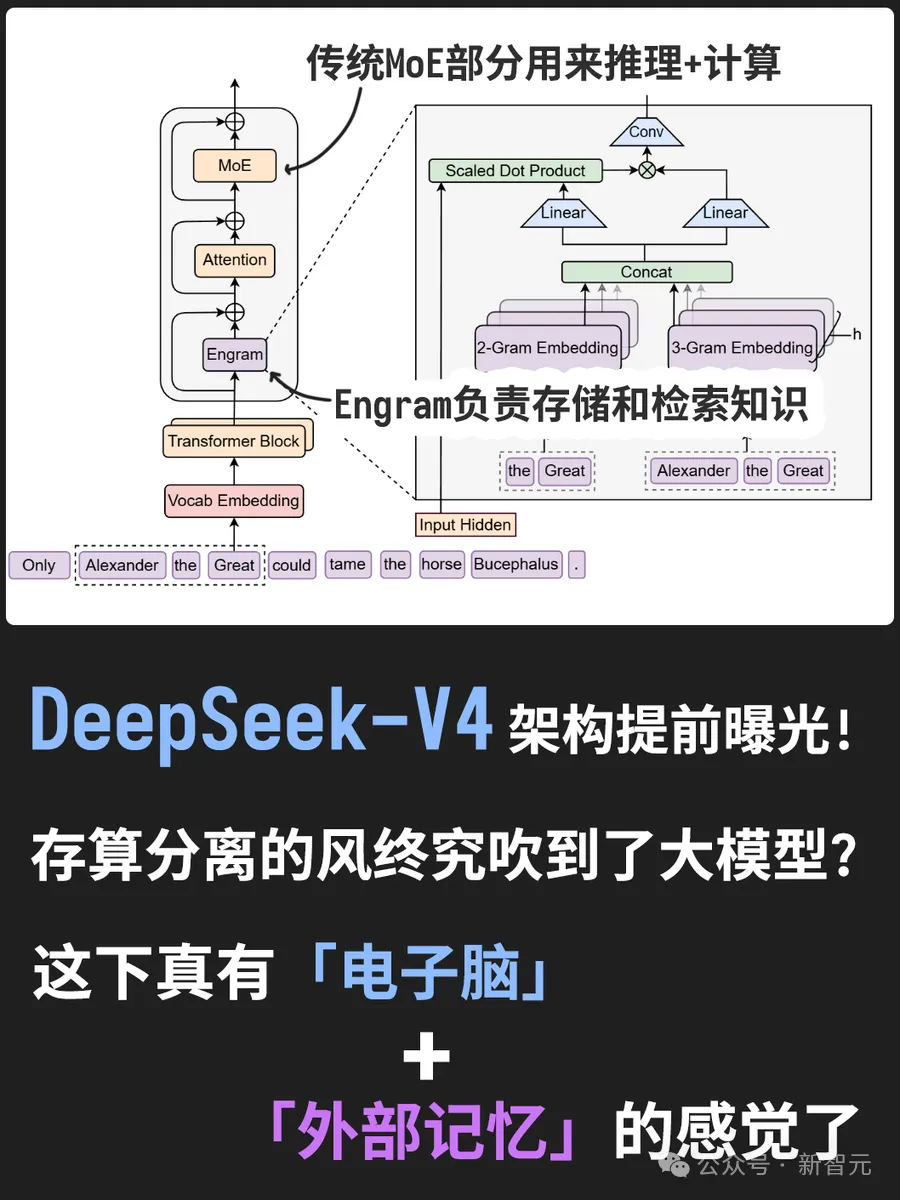
由此,团队提出了Engram,把语言建模中大量「固定、局部、刻板」的模式,交给一个可扩展的查表模块去承担。
这样一来,可以让Transformer主干把注意力和深度用在更需要「组合与推理」的地方。
语言建模,两类任务
论文中,作者明确将语言建模拆成两类子任务:
一部分任务需「组合与推理」:上下文关系、长程依赖、逻辑推理、链式推理。
另一部分任务更像「模式检索」:实体名、固定搭配、常见短语、语法片段、重复出现的局部结构
后者的一个共同点很明显,即它们往往局部、稳定、重复出现。
若是用多层注意力和FFN去「算」他们,模型做得到,但成本极高,还会挤占早期层的表达空间。
为了识别实体「戴安娜,威尔士王妃」(Diana,Princess of Wales),LLM必须消耗多层注意力和FFN来逐步组合特征,这个过程理论上是可以通过一次知识查找操作来完成的。
而Engram想做的事情很直接——
把这类「局部静态模式」转移到一个廉价的知识查找原语。
它用确定性的查表快速给出候选信息,再由上下文决定是否采纳。
Engram核心架构:暴力查表+记忆开关
Engram一词源于神经学,本意为「记忆痕迹」,是一种可扩展、可检索的记忆单元。
它可以用于存储LLM在推理过程中,可能已接触过的模式、信息片段。
可以将Engram理解为,把经典「哈希N-gram嵌入」现代化,做成插在Transformer中间层的一个「可扩展查表模块」。