老黄All in物理AI量子位
刚刚,英伟达CEO黄仁勋穿着鳄鱼皮夹克,在全球最大消费电子展CES 2026上发布AI新品。
这是五年来,英伟达首次来到CES却没有发游戏显卡,态度很明确:全力搞AI。
全力搞出来的结果也让围观群众直呼:竞争对手如何追上英伟达?
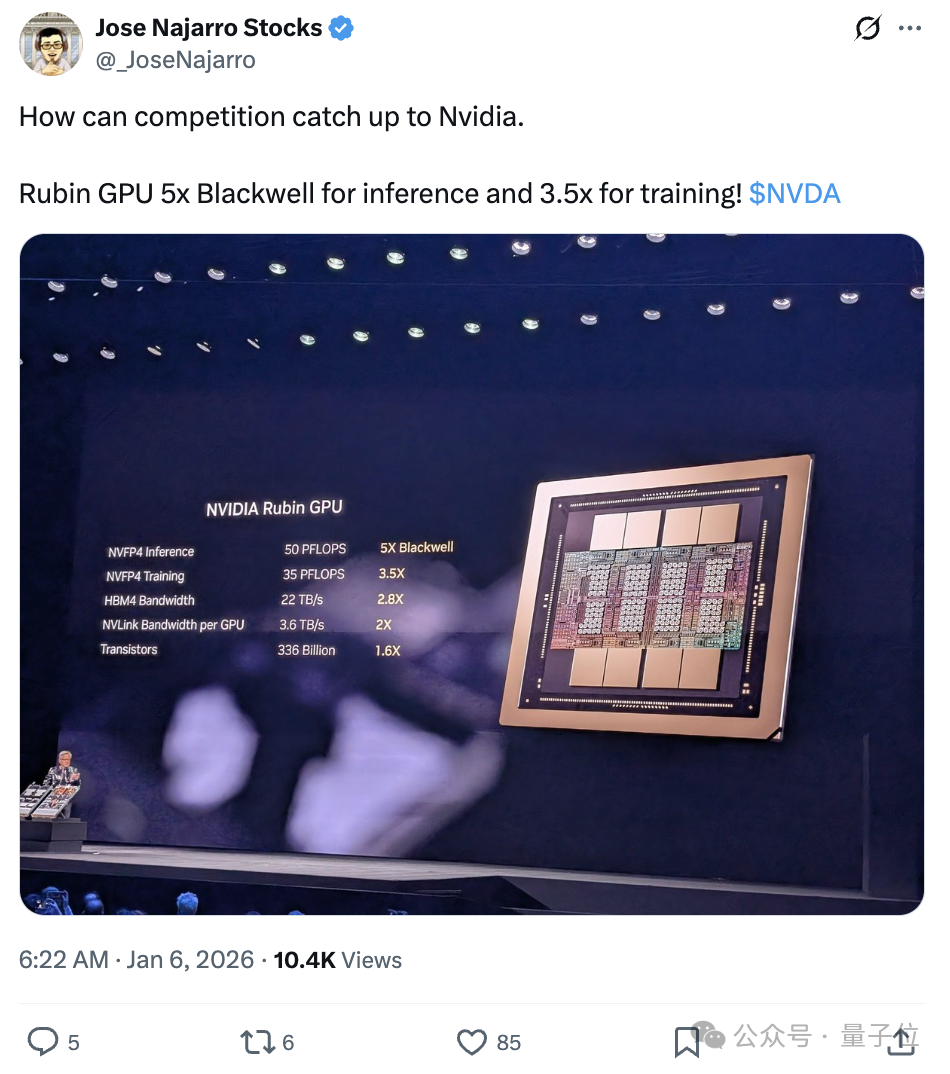
下一代Rubin架构GPU推理、训练性能分别是Blackwell GB200的5倍和3.5倍(NVFP4数据格式)。
除此之外,老黄还带来了五大领域的全新发布,包括:
面向Agentic AI的NVIDIA Nemotron模型家族
面向物理AI的NVIDIA Cosmos平台
面向自动驾驶开发的全新NVIDIA Alpamayo模型家族
面向机器人领域的NVIDIA Isaac GR00T
面向生物医学的NVIDIA Clara
同时,英伟达宣布持续向社区开源训练框架以及多模态数据集。其中数据集包括10万亿语言训练token、50万条机器人轨迹数据、45.5万个蛋白质结构、100TB车辆传感器数据。
这次的核心主题,直指物理AI。
用网友的话来说:
这是英伟达将护城河从芯片层进一步拓展到全栈平台层(模型+数据+工具)的体现,通过这种方式可以持续拉动更多GPU与基础设施投入,并显著增强用户与生态的锁定。
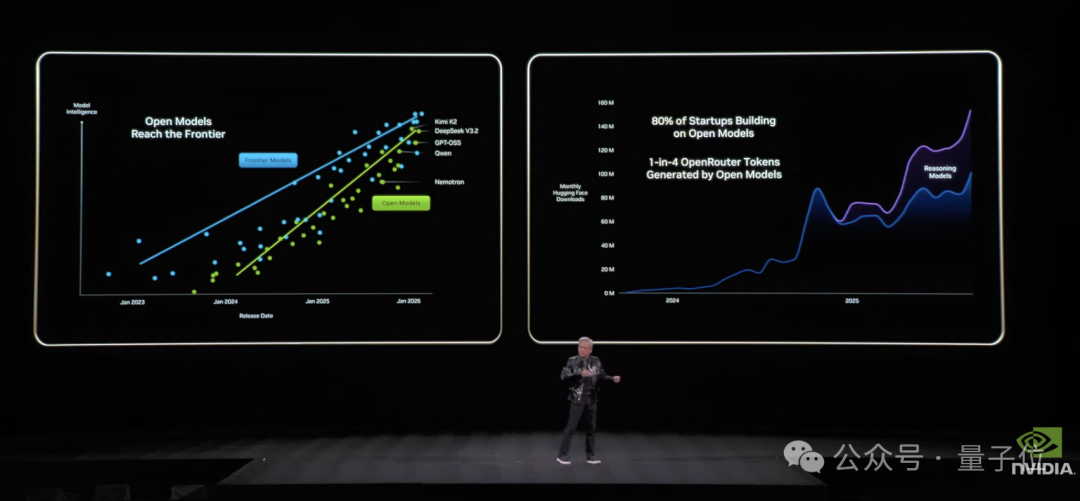
值得一提的是,咱国产开源模型又双叒被cue到了。
老黄在演讲开篇便提及了DeepSeek,Kimi K2、Qwen也出现在PPT展示页上。
正式推出Vera Rubin NVL72
老黄正式推出英伟达下一代AI数据中心的机柜架构Vera Rubin,披露架构细节。
六大核心组件共同构成Vera Rubin NVL72机架:Vera CPU、Rubin GPU、NVLink 6 switch、ConnectX-9 SuperNIC、BlueField-4数据处理单元(DPU)、Spectrum-6 Ethernet switch。
在NVFP4数据类型下,Rubin GPU推理性能可达50 PFLOPS,是Blackwell GB200的5倍;NVFP4训练性能为35 PFLOPS,是Blackwell的3.5 倍。
为支撑这些计算能力,每颗Rubin GPU封装了8组HBM4内存,提供288GB容量和22 TB/s的带宽。
随着主流大模型转向MoE架构,模型得以相对高效地进行规模扩展。然而,这些专家模块之间的通信,对节点间带宽提出了极高要求。
Vera Rubin引入了用于规模内扩展网络的NVLink 6。
它将单GPU的互连带宽提升至3.6 TB/s(双向)。每颗NVLink 6交换芯片提供28 TB/s的带宽,而每个Vera Rubin NVL72机架配备9颗这样的交换芯片,总规模内带宽达到260 TB/s。
NVIDIA Vera CPU集成了88个定制的Olympus Arm核心,采用英伟达称为“spatial multi-threading”设计,最多可同时运行176个线程。
用于将Vera CPU与Rubin GPU进行一致性连接的NVLink C2C互连,其带宽提升了一倍,达到1.8 TB/s。每颗Vera CPU可寻址最多1.5 TB的SOCAMM LPDDR5X内存,内存带宽最高可达1.2 TB/s。
为将Vera Rubin NVL72机架扩展为每组8个机架的DGX SuperPod,英伟达推出了一对采用共封装光学(CPO)的Spectrum-X以太网交换机,均基于Spectrum-6芯片构建。
每颗Spectrum-6芯片提供102.4 Tb/s的带宽,英伟达基于该芯片推出了两款交换机。
SN688提供409.6 Tb/s的总带宽,支持512个800G以太网端口或2048个200G端口。
SN6810则提供102.4 Tb/s的带宽,可配置为128 个800G或512个200G以太网端口。
这两款交换机均采用液冷设计,英伟达表示,与不具备硅光子技术的硬件相比,它们在能效、可靠性和运行时间方面表现更优。
随着上下文窗口扩展到数百万token,英伟达还指出,存储AI模型交互历史的键值缓存(KV cache)相关操作,已成为推理性能的瓶颈。
此前黄仁勋曾表态:没有HBM,就没有AI超算。
为突破这一限制,英伟达推出新硬件BlueField-4 DPU,构建了一个新的内存层级,称为推理上下文内存存储平台(Inference Context Memory Storage Platform)。
英伟达表示,这一存储层旨在实现键值缓存数据在AI基础设施中的高效共享与复用,从而提升系统响应速度和吞吐能力,并实现Agentic AI架构可预测、能效友好的规模扩展。