DeepSeek暴力优化AI架构新智元
2026新年第一天,DeepSeek发表了梁文锋署名的重磅新论文,提出了一种名为「mHC(流形约束超连接)」的新架构,在27B参数模型上,仅增加约6.7%的训练时间开销,即可实现显著性能提升。
刚刚,DeepSeek送上2026年新年第一个王炸。
这次的创新是,mHC(流形约束超连接)新架构。
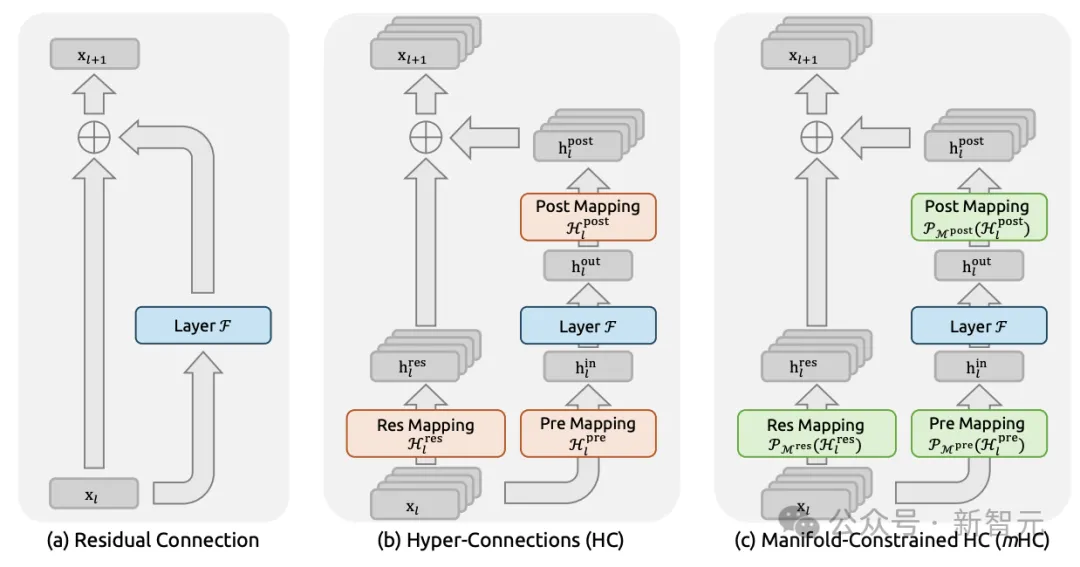
在这篇论文中,DeepSeek提出了流形约束超连接(mHC),将矩阵投影到约束流形上优化残差连接空间,从而确保稳定性,彻底颠覆了传统AI架构认知——
可以扩大残差流通道宽度(residual stream width),而在算力和内存上的代价却微乎其微。
图1: 残差连接范式示意图
继Hyper-Connections(HC)开辟「残差连接宽度可扩展」路线之后,mHC直接把这一思路推上实用化的快车道。
DeepSeek这次直击AI痛点,给同行上了一课!
值得一提的是,这次梁文锋署名,但解振达、韦毅轩、Huanqi Cao为核心贡献者,解振达为通讯作者。
DeepSeek,或敲响ResNet丧钟
这简直是为「模型优化玩家」量身打造的王牌秘方。
过去,超连接(hyper-connections)更多只是学术圈的小众尝试。
而现在,DeepSeek直接把它升级为基础架构的核心设计要素。
这也正是拥趸一直以来对DeepSeek的期待:数学上的洞察力+硬件层面的极致优化。
顶级大语言模型(LLM)中,ResNet结构或许即将被淘汰。
毕竟,残差流通道宽度一直是扩展模型的「烦人瓶颈」。
这波操作,也再次展现了DeepSeek典型的风格:对同行的温和降维打击——
你们两年时间都在打磨微结构,调整DS-MoE?挺可爱哈。
来看看我们怎么玩:把一个理论上看起来还不够成熟的高级原语,直接做实,顺手解锁游戏下一关。
他们在论文中写道:「我们的内部大规模训练实验进一步验证了mHC在大规模应用中的有效性。」
这句话在DeepSeek的原生稀疏注意力(Natively trainable Sparse Attention,NAS)那篇论文里可没有。
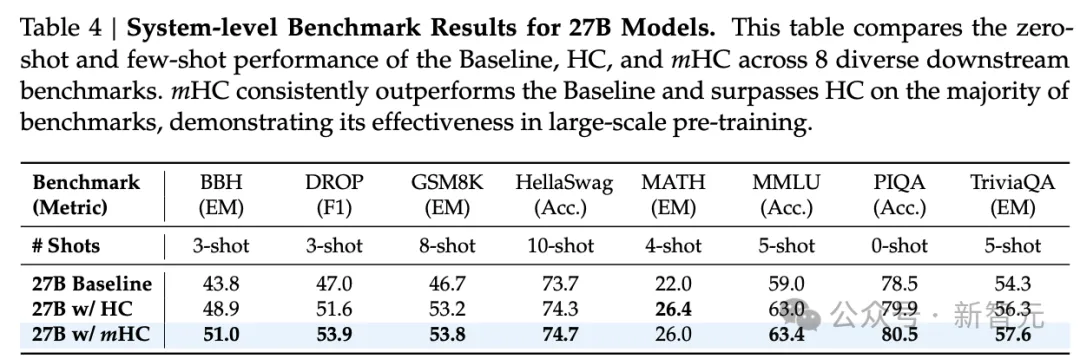
在27B模型的系统级基准测试结果中,新架构mHC在绝大多数基准测试中持续超越基线模型并优于HC,这证明其在大规模预训练中的有效性。
换句话说,DeepSeek信心十足,不怕同行知道自己的「杀招」。
这给了DeepSeek的铁粉Teortaxes很大信心,他有九成把握:mHC会进入DeepSeek V4。
Manifold-Constrained Hyper-Connections (mHC)
这个方法的关键目标,就是在Hyper-Connections的拓扑设计下恢复身份映射属性。这样,就可以在大规模训练与现实基础模型任务中体现实际价值。
mHC与传统残差连接和HC的根本差异在于:传统残差连接只保留简单的输入 + 输出形式(稳定但表达受限);Hyper-Connections (HC) 强化连接能力,但牺牲了稳定性与效率。
而mHC的思路是:将Hyper-Connections的参数空间约束到特定的流形(manifold)上,以恢复恒等映射结构。
这意味着该可学习映射是非扩张的,从而能够有效缓解梯度爆炸问题。
这提供了清晰的几何直观:残差映射可以被看作是若干置换的凸组合。