一个颠覆认知的数学发现:LLM是单射的MoonAGI
12/23/2025
想象一下:你把一段私密对话输入到 ChatGPT,它把你的话转换成了一串看起来毫无意义的数字(隐藏状态)。你以为这些数字像加密后的密码一样安全,别人看不懂原文是什么。
但如果我告诉你,只要有正确的工具,这些数字可以被 100% 完美还原成你输入的每一个字,连标点符号都不差呢?
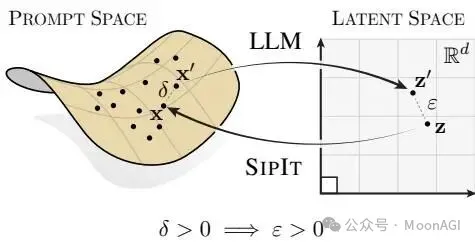
最近一篇来自罗马智慧大学和 EPFL 的研究彻底打破了这个安全幻觉。研究团队用严格的数学证明了:标准的 Transformer 语言模型(GPT、Llama 等)是单射的——不同的输入文本几乎必然产生不同的内部表示,而且这个过程是完全可逆的。
更令人震惊的是,他们开发的 SIPIT 算法可以从模型的隐藏状态中逐字逐句地还原出原始输入,速度快、准确率 100%。
这不仅仅是一个理论发现——它直接影响着每一个使用大语言模型的人的隐私和安全。
在深入细节之前,让我先把这篇论文的核心观点列给你:
核心结论:Transformer 语言模型是单射的。意思是:不同的输入文本必然产生不同的输出向量,绝不会混淆
数学原理:模型内部的组件(注意力、LayerNorm 等)都是"实解析函数"。这类函数有个特性:除非运气极差(概率为 0),否则一定能保留所有输入信息
训练无害:无论怎么训练(梯度下降),都不会破坏这种"信息无损"的特性
实验验证:在 6 个主流模型上进行了 50 亿次测试,没发现任何两个不同输入产生相同向量的情况
SIPIT 算法:可以 100% 精确地从模型内部向量还原出原始文本
隐私警示:把文本变成向量(Embedding)并不安全,因为它可以被完美逆向还原
现在让我们像剥洋葱一样,一层层把这个复杂的数学证明讲清楚。